랭체인
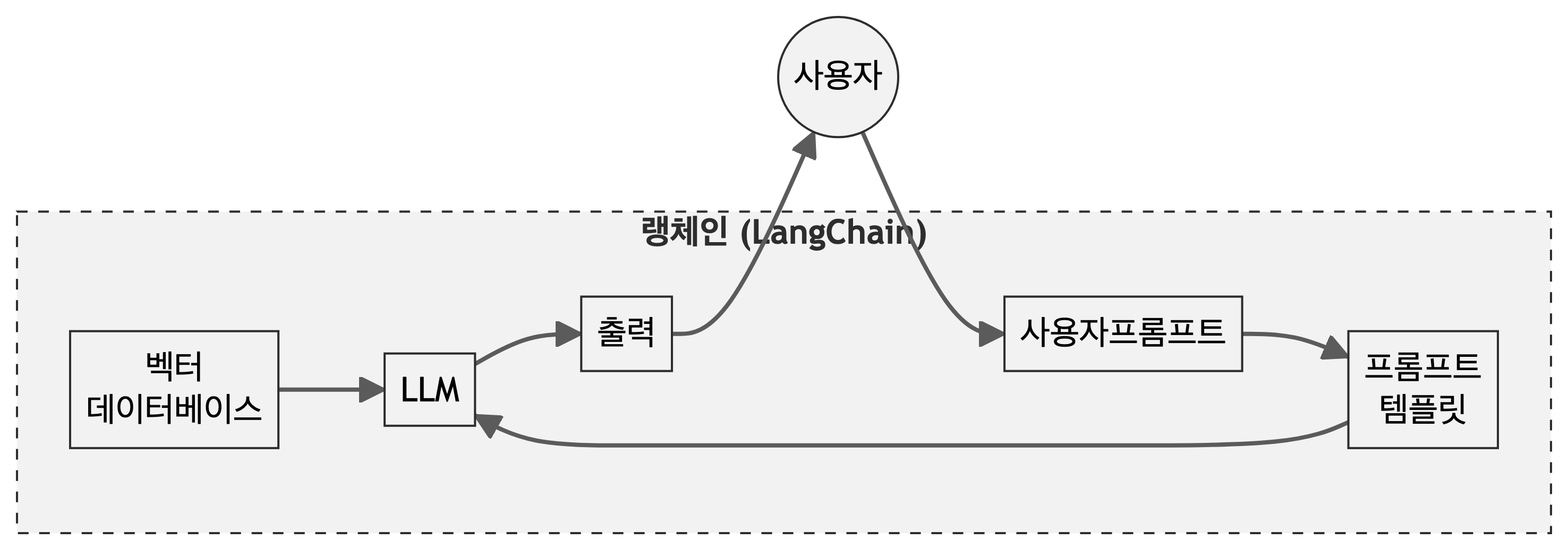
랭체인(langcahin)은 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발을 위한 소프트웨어 개발 프레임워크로, LLM을 다양한 애플리케이션과 통합하는 것을 용이하기 쉽기 때문에 인기를 얻고 있다. 랭체인은 LLM과 인터페이스, 다양한 구성 요소 연결, 메모리 관리 등이 수월하기 때문에 특히 개발자 사이에서 인기가 높다. 랭체인의 주요 목적은 LLM 기반 애플리케이션 개발을 단순화하고 가속화하는 것으로 데이터 처리, 프롬프트 관리, 모델 통합 등 LLM 애플리케이션 개발의 여러 측면을 쉽게 다룰 수 있도록 도구와 추상화를 제공한다.
- 대규모 언어 모델(LLM), 데이터 소스, 그리고 다른 기능들을 통합된 문법 아래 연결한다.
- 확장성을 허용한다.
- 모듈화된 컴포넌트들을 포함한다.
- 파이썬과 JavaScript를 지원한다.
API
허깅페이스
파이썬과 R을 사용해 Hugging Face Hub의 대형 언어 모델(Large Language Model, LLM)을 활용한다. 파이썬에서는 필요한 라이브러리를 설치하고, R에서는 reticulate 라이브러리를 통해 파이썬 환경을 사용한다. 파이썬 코드에서 Hugging Face Hub에 접근하기 위한 API 토큰을 로드하고, HuggingFaceHub 클래스를 사용하여 특정 모델(‘tiiuae/falcon-7b-instruct’)에 질문을 하고, 모델의 답변을 출력한다.
pip install langchain_community,pip install dotenv,pip install langchain-huggingface: 이 세 명령어는 파이썬 환경에서 필요한 패키지들을 설치한다.langchain_community는 언어 체인 커뮤니티 라이브러리,dotenv는 환경 변수를 관리하는 라이브러리,huggingface_hub는 Hugging Face Hub와 연동하는 데 사용되는 라이브러리다.R 코드 부분에서
library(reticulate)를 사용해 파이썬과 R 사이의 상호작용을 가능하게 하는reticulate라이브러리를 로드한다.use_condaenv("langchain", required = TRUE)는langchain이라는 이름의 Conda 환경을 사용하도록 지시한다. 이는 파이썬 코드를 R 환경에서 실행하기 위한 준비 단계다.파이썬 코드에서는 먼저
langchain_community.llms에서HuggingFaceHub클래스를,dotenv에서load_dotenv함수를 가져온다. 이후os모듈을 임포트한다.load_dotenv()를 호출하여 환경 변수를 로드한다. 이는.env파일에 저장된 환경 변수를 사용할 수 있게 한다.huggingfacehub_api_token = os.getenv('HF_TOKEN')는 환경 변수에서 ’HF_TOKEN’을 찾아 해당 토큰을 변수에 저장한다. 이 토큰은 Hugging Face Hub에 접근할 때 인증을 위해 사용된다.HuggingFaceHub클래스의 인스턴스를 생성한다. 이 때repo_id에는 사용할 Hugging Face 모델의 저장소 ID를,huggingfacehub_api_token에는 위에서 얻은 API 토큰을 넣는다.대형 언어 모델에 질문을 하기 위해
question변수에 질문을 저장하고,llm.invoke(question)을 호출하여 모델에 질문을 전달하고 결과를 받는다.마지막으로
print(output)을 통해 얻은 결과를 출력한다. 이 코드는 Hugging Face Hub의 특정 모델을 사용하여 질문에 대한 답변을 얻는 과정을 보여준다.
pip install langchain_communitypip install dotenvpip install -U langchain-huggingface
다양한 한국어가 지원되는 언어모형을 실험해봤지만 언어모형 크기가 큰 경우 실행이 불가능하다.
코드
from langchain_huggingface import HuggingFaceEndpoint
from dotenv import load_dotenv
import os
load_dotenv()
huggingfacehub_api_token = os.getenv('HUGGINGFACEHUB_API_TOKEN')
huggingfacehub_api_token
llm = HuggingFaceHub(repo_id='tiiuae/falcon-7b-instruct',
huggingfacehub_api_token = huggingfacehub_api_token)
question = 'What is LLM in AI?'
output = llm.invoke(question)
print(output)OpenAI
pip install --upgrade langchain openai 명령어로 openai 패키지를 설치하고 pip install langchain-openai 명령어로 랭체인 인터페이스를 사용해서 LLM 을 활용한다.
코드
from langchain_openai import OpenAI
openai_api_key = os.getenv('OPENAI_API_KEY')
llm = OpenAI(
model_name="gpt-3.5-turbo-instruct",
openai_api_key=openai_api_key
)
question = '인공지능 대규모 언어모형 LLM이 뭐야'
output = llm.invoke(question)
print(output)LLM은 'Large Language Model'의 약자로, 인공지능 기술 중 하나인 자연어 처리(Natural Language Processing) 분야에서 사용되는 대규모 언어모형을 말합니다. LLM은 수많은 문장과 단어를 학습하고 이를 바탕으로 텍스트를 생성하고 이해하는 기술을 갖춘 인공지능 모델을 의미합니다. 이를 통해 LLM은 인간과 유사한 수준의 언어 이해 및 생성 능력을 가지고 있습니다. LLM은 다양한 분야에서 활용되고 있으며, 텍스트 생성, 기계 번역, 자연어 이해 등 다양한 응용 분야에서 성능을 발휘하고 있습니다.클로드
pip install -U langchain-anthropic 앤트로픽을 설치한 후 동일하게 실행한다.
코드
from langchain_anthropic import ChatAnthropic
from dotenv import load_dotenv
import os
load_dotenv()
anthropic_api_key = os.getenv('ANTHROPIC_API_KEY')
llm = ChatAnthropic(
model="claude-3-opus-20240229",
anthropic_api_key=anthropic_api_key
)
question = '인공지능 대규모 언어모형 LLM이 뭐야?'
output = llm.invoke(question)
print(output.content)'인공지능 대규모 언어모형(Large Language Model, LLM)은 방대한 양의 텍스트 데이터를 학습하여 만들어진 거대한 신경망 모델입니다. LLM은 다음과 같은 특징을 가지고 있습니다:\n\n1. 데이터 크기: 수백 기가바이트에서 수 테라바이트에 이르는 방대한 텍스트 데이터로 학습합니다.\n\n2. 모델 크기: 수십억에서 수조 개의 매개변수를 가진 거대한 신경망 구조를 가집니다. \n\n3. 자연어 이해 및 생성: 문맥을 이해하고 자연스러운 언어를 생성할 수 있습니다.\n\n4. 다양한 태스크 수행: 질의응답, 요약, 번역, 창작 등 다양한 자연어 처리 태스크를 수행할 수 있습니다.\n\n5. 사전 학습과 전이 학습: 대량의 데이터로 사전 학습된 후, 특정 태스크를 위해 추가 학습(전이 학습)될 수 있습니다.\n\n대표적인 LLM으로는 GPT-3, BERT, XLNet, T5 등이 있습니다. 이러한 모델들은 자연어 처리 분야에서 혁신을 가져왔으며, 다양한 응용 분야에서 활용되고 있습니다. 그러나 막대한 컴퓨팅 자원이 필요하고, 편향성 문제 등 한계점도 존재합니다. LLM 기술은 계속 발전하고 있으며, 앞으로도 자연어 인공지능 분야를 선도할 것으로 예상됩니다.'프롬프트 템플릿
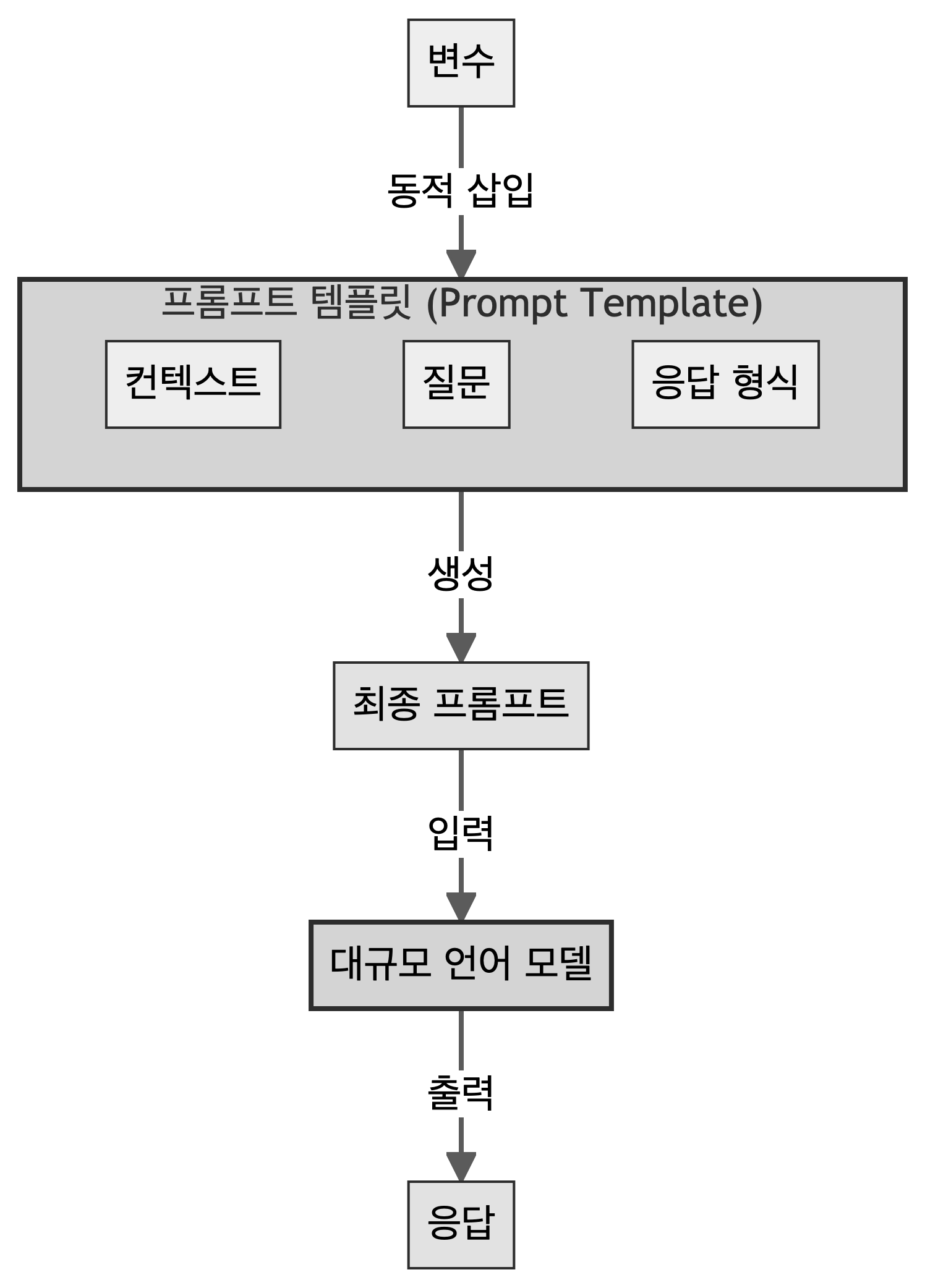
프롬프트 템플릿(Prompt Template)은 대규모 언어 모델(LLM)에 입력할 프롬프트의 구조를 정의하는 틀(template)로 일관된 형식의 프롬프트를 생성하고, 동적으로 내용을 채워 넣을 수 있게 해주는 도구다.
- 재사용성: 동일한 구조의 프롬프트를 여러 번 사용할 수 있다.
- 일관성: 프롬프트의 형식을 일정하게 유지할 수 있다.
- 동적 내용: 변수를 사용하여 프롬프트의 특정 부분을 동적으로 변경할 수 있다.
- 구조화: 컨텍스트, 질문, 응답 형식 등을 체계적으로 구성할 수 있다.
프롬프트 템플릿은 주로 세 가지 요소(컨텍스트, 질문, 응답 형식)로 이루어진다.
컨텍스트는 모델에게 배경 정보를 제공하고, 질문은 모델에게 요구하는 구체적인 작업을 명시한다. 응답 형식은 모델이 어떤 방식으로 답변해야 하는지 지시한다.
프롬프트 템플릿에는 변수를 포함시킬 수 있다. 변수는 프롬프트를 생성할 때 동적으로 값이 채워지는 부분으로 동일한 구조의 프롬프트를 다양한 상황에 맞춰 재사용할 수 있다.
프롬프트 템플릿은 이러한 요소들을 조합해 최종 프롬프트를 만들어내는 과정에서 변수에 실제 값이 할당되고, 전체 프롬프트의 구조가 완성된다. 완성된 최종 프롬프트는 대규모 언어 모델(LLM)에 입력된다. LLM은 이 프롬프트를 받아 처리하고, 요청된 작업에 따라 적절한 응답을 생성해 출력한다.
코드
from langchain_core.prompts import PromptTemplate
from langchain_openai import OpenAI
from dotenv import load_dotenv
import os
# .env 파일에서 환경 변수 로드
load_dotenv()
# 프롬프트 템플릿 정의
template = """
컨텍스트: {context}
질문: {question}
응답 형식: {response_format}
위의 컨텍스트를 바탕으로 질문에 답하세요. 응답은 제시된 형식을 따라주세요.
"""
prompt_template = PromptTemplate(
template=template,
input_variables=["context", "question", "response_format"]
)
# OpenAI LLM 초기화 (API 키는 .env 파일에서 가져옴)
llm = OpenAI(model_name="gpt-3.5-turbo-instruct",
temperature=0.7,
openai_api_key=os.getenv("OPENAI_API_KEY"))
# 프롬프트 생성
prompt = prompt_template.format(
context="랭체인은 대규모 언어 모델을 활용한 애플리케이션 개발을 위한 프레임워크입니다.",
question="랭체인의 주요 특징 세 가지는 무엇인가요?",
response_format="1. 첫 번째 특징\n2. 두 번째 특징\n3. 세 번째 특징"
)
# LLM에 프롬프트 전달 및 응답 생성
response = llm.invoke(prompt)
print("생성된 프롬프트:")
print(prompt)
print("\nLLM 응답:")
print(response)생성된 프롬프트:
컨텍스트: 랭체인은 대규모 언어 모델을 활용한 애플리케이션 개발을 위한 프레임워크입니다.
질문: 랭체인의 주요 특징 세 가지는 무엇인가요?
응답 형식: 1. 첫 번째 특징
2. 두 번째 특징
3. 세 번째 특징
위의 컨텍스트를 바탕으로 질문에 답하세요. 응답은 제시된 형식을 따라주세요.
LLM 응답:
1. 랭체인은 대규모 언어 모델을 활용하여 자연어 처리 작업을 수행할 수 있습니다.
2. 랭체인은 다양한 애플리케이션 개발을 지원하기 위한 다양한 API를 제공합니다.
3. 랭체인은 사용자가 직접 학습한 데이터를 추가하여 모델을 개선할 수 있는 기능을 제공합니다.LCEL
랭체인 표현언어(LangChain Expression Language, LCEL)는 LangChain 컴포넌트들을 연결하고 조합하기 위한 선언적 방식의 인터페이스로 복잡한 AI 애플리케이션 구축을 단순화하고 가독성을 높이는 데 도움을 준다. 체인(Chain)은 LCEL의 핵심 개념 중 하나로, 여러 컴포넌트들을 연결하여 하나의 작업 흐름을 만드는 것을 말한다.
유닉스 파이프(|)를 이해하고 있다면 prompt | model와 같이 프롬프트 템플릿과 LLM 모델을 연결하는 간단한 체인을 생성한다. 프롬프트 | LLM | 출력파서와 같은 패턴이 일반적이다. 프롬프트 템플릿으로 주제를 받아 프롬프트를 완성하고 LLM 모형에 전달하고 출력파서를 통해 원하는 결과물을 출력시킨다.
코드
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain_core.runnables import RunnablePassthrough
from dotenv import load_dotenv
import os
# .env 파일에서 환경 변수 로드
load_dotenv()
# 출력 파서 정의
output_parser = CommaSeparatedListOutputParser()
# 프롬프트 템플릿 정의
prompt_template = ChatPromptTemplate.from_template("""
다음 주제에 관련된 키워드를 5개 나열해주세요: {topic}
당신의 응답은 반드시 쉼표로 구분된 단일 단어 목록이어야 합니다.
""")
# 모델 정의 (API 키는 .env 파일에서 가져옴)
model = OpenAI(
model_name="gpt-3.5-turbo-instruct",
temperature=0.7,
openai_api_key=os.getenv("OPENAI_API_KEY")
)
# 체인 구성
chain = (
{"topic": RunnablePassthrough()}
| prompt_template
| model
| output_parser
)
# 체인 실행
result = chain.invoke("인공지능")
print("인공지능 관련 키워드:")
for keyword in result:
print(f"- {keyword}")인공지능 관련 키워드:
- 기계학습
- 딥러닝
- 자연어처리
- 로봇
- 빅데이터LCEL과 Chain을 사용하면 복잡한 AI 로직을 더 쉽게 구조화하고 관리할 수 있으며, 코드의 가독성과 유지보수성을 크게 향상시킬 수 있다.
랭그래프
랭그래프(LangGraph)는 랭체인(LangChain)의 일부로, 에이전트(Agent) 시스템을 설계하기 위한 도구로 복잡한 AI 워크플로우를 구축하는 데 사용된다. 랭그래프는 에이전트의 상태를 추적하고 관리할 수 있는 상태 관리 기능을 제공한다. 이를 통해 장기적인 대화나 복잡한 작업의 진행 상황을 효과적으로 추적할 수 있고, 조건부 로직과 반복을 포함한 복잡한 워크플로우를 정의할 수 있는 유연성을 제공한다. 또한, 다양한 외부 도구와 API를 쉽게 통합할 수 있는 기능도 랭그래프의 중요한 특징으로 AI 시스템의 능력을 확장하고 실제 세계의 다양한 작업을 수행할 수 있게 된다. 특히, 랭그래프는 재사용 가능한 컴포넌트를 만들어 복잡한 시스템을 구축할 수 있는 모듈성을 제공하여 개발 효율성을 높이고 일관성 있는 시스템 구축을 가능하게 한다.
pip install langgraph 명령어로 설치한 후 프롬프트 템플릿에 사칙연산 관련 문제풀이로 LLM을 활용한다. LLMMathChain은 numexpr 패키지도 필요하니 pip install numexpr 명령어로 설치한다.
코드
from langchain.agents import initialize_agent, load_tools
from langchain.llms import OpenAI
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Get OpenAI API key
openai_api_key = os.getenv("OPENAI_API_KEY")
# Initialize the language model
llm = OpenAI(
model_name="gpt-3.5-turbo-instruct",
temperature=0.0,
openai_api_key=openai_api_key
)
# Load the necessary tools
tools = load_tools(["llm-math"], llm=llm)
# Define the prompt for the agent
prompt = """
You are a helpful assistant that can perform various mathematical calculations and provide accurate results.
"""
# Create the ReAct agent with the prompt
agent = initialize_agent(
tools=tools,
llm=llm,
agent_type="react",
verbose=True
)
# List of questions to ask the agent
questions = [
"15 더하기 27은 얼마인가요?",
"144의 제곱근은 얼마인가요?",
"250의 30%는 얼마인가요?",
"5 곱하기 8에서 12를 뺀 값은 얼마인가요?",
]
# Ask each question to the agent and print the response
for question in questions:
response = agent.invoke({"input": question})
print(f"질문: {question}")
print(f"답변: {response['output']}\n")> Entering new AgentExecutor chain...
I should use a calculator to add 15 and 27
Action: Calculator
Observation: Answer: 42
Thought: I now know the final answer
Final Answer: 42
> Finished chain.
질문: 15 더하기 27은 얼마인가요?
답변: 42
> Entering new AgentExecutor chain...
I should use a calculator to find the square root of 144
Action: Calculator
Action Input: 144
Observation: Answer: 144
I now know the final answer
Final Answer: 12
> Finished chain.
질문: 144의 제곱근은 얼마인가요?
답변: 12
> Entering new AgentExecutor chain...
We need to find the percentage of 250.
Action: Calculator
Observation: Answer: 75.0
Thought: We have found the percentage.
Final Answer: 75.0
> Finished chain.
질문: 250의 30%는 얼마인가요?
답변: 75.0
> Entering new AgentExecutor chain...
I should use a calculator to solve this problem.
Action: Calculator
Action Input: 5 * 8 - 12
Observation: Answer: 28
I now know the final answer.
Final Answer: 28
> Finished chain.
질문: 5 곱하기 8에서 12를 뺀 값은 얼마인가요?
답변: 28RAG
검색 증강 생성(Retrieval Augmented Generation, RAG)는 대규모 언어 모델(LLM)의 성능을 향상시키기 위해 외부 지식을 활용하는 기술로 사용자의 질문이나 프롬프트에 대해 관련성 높은 정보를 검색하고, 이를 원래의 프롬프트와 결합하여 LLM에 제공한다. RAG의 핵심 아이디어는 LLM의 생성 능력과 외부 데이터베이스의 최신 정보를 결합하는 것으로 임베딩(Embedding)이 중요한 역할을 한다. 사용자의 질문과 데이터베이스 내 문서들은 벡터 형태로 변환되며, 이를 통해 의미적 유사성을 기반으로 관련 정보를 빠르게 검색할 수 있다.
RAG의 작동 과정은 다음과 같다. 먼저, 사용자가 질문을 입력하면 이 질문은 벡터로 변환된다. 그 다음, 이 벡터를 사용해 미리 준비된 벡터 데이터베이스에서 가장 유사한 문서나 정보를 검색한다. 검색된 정보는 원래의 질문과 함께 새로운 프롬프트를 구성하는 데 사용된다. 이렇게 증강된 프롬프트가 LLM에 입력되어 최종 응답을 생성한다.
LLM은 학습 시점의 데이터에 기반하므로 최신 정보를 반영하지 못할 수 있지만, RAG를 통해 외부 데이터베이스의 최신 정보를 활용할 수 있어 LLM의 환각(hallucination) 문제를 줄이고 더 정확하고 신뢰할 수 있는 응답을 생성하는 데 도움을 준다.

numpy 버전 오류
AttributeError: np.float_ was removed in the NumPy 2.0 release. Use np.float64 instead.
Cell In[53], line 26
24 # 임베딩 모델 및 벡터 저장소 설정
25 embeddings = OpenAIEmbeddings()
---> 26 vectorstore = Chroma.from_documents(texts, embeddings)
28 # RAG 체인 설정
29 llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
Show Traceback코드
from langchain.document_loaders import WikipediaLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
import os
# 환경 변수 로드
load_dotenv()
# OpenAI API 키 설정
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 위키백과에서 "인공지능" 문서 로드
loader = WikipediaLoader("인공지능", load_max_docs=1)
documents = loader.load()
# 문서 분할
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.split_documents(documents)
# 임베딩 모델 및 벡터 저장소 설정
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(texts, embeddings)
# RAG 체인 설정
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever()
)
# 질문-답변 루프
while True:
query = input("\n질문을 입력하세요 (종료하려면 'q' 입력): ")
if query.lower() == 'q':
break
result = qa_chain.invoke(query)
print(f"\n답변: {result['result']}")