벡터 데이터베이스

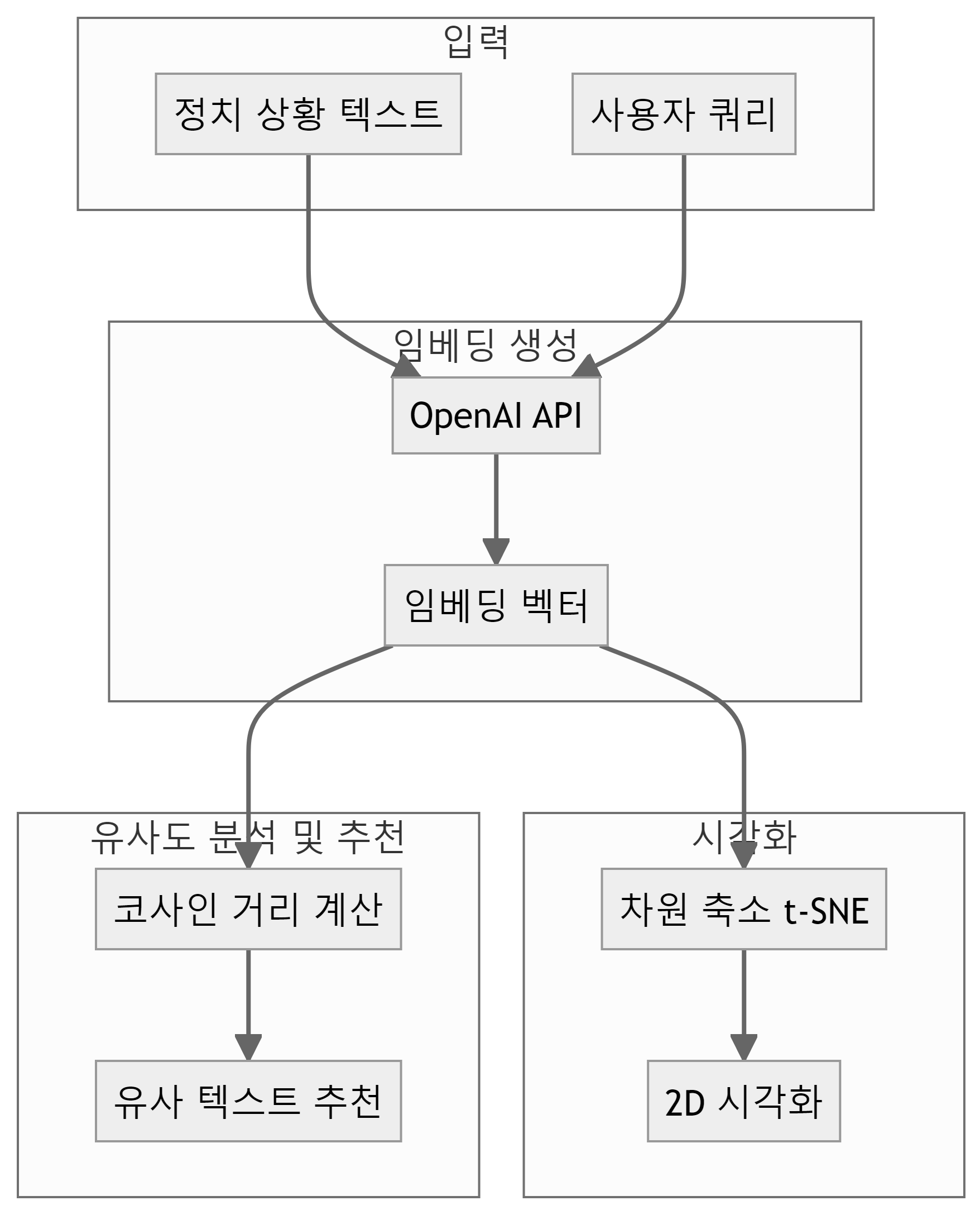
임베딩
자연어 처리(NLP) 분야에서 나온 개념으로, 텍스트의 맥락과 의도를 포착하는데 유용한 임베딩(Embedding)은 텍스트를 다차원 벡터 공간에 매핑한 수치적 표현으로 텍스트의 의미를 포착하는 숫자 벡터로 변환하는 과정이다. 텍스트의 의미적 유사성을 수학적으로 계산할 수 있기 때문에 유사한 의미를 가진 단어나 문장은 벡터 공간에서 서로 가깝게 위치하게 된다. 의미 검색, 추천 시스템, 분류 작업 등 다양한 AI 응용 프로그램에 활용된다.
코드
from openai import OpenAI
import numpy as np
import matplotlib.pyplot as plt
from scipy.spatial.distance import cosine
from sklearn.manifold import TSNE
from dotenv import load_dotenv
import os
import matplotlib.font_manager as fm
load_dotenv()
# 텍스트 데이터 (정치 상황)
texts = [
"A당은 경제 성장을 최우선 과제로 삼고 있다",
"B당은 복지 정책 확대를 주장하고 있다",
"A당은 규제 완화를 통한 기업 활성화를 추진한다",
"B당은 환경 보호를 위한 정책을 강조한다",
"A당은 국방력 강화에 중점을 두고 있다",
"B당은 교육 개혁을 통한 인재 양성을 중시한다",
"양당은 부동산 정책에서 첨예하게 대립하고 있다"
]
client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
# 임베딩 생성 함수
def get_embedding(text):
response = client.embeddings.create(
model="text-embedding-ada-002",
input=text
)
return response.data[0].embedding
# 텍스트를 임베딩으로 변환
embeddings = [get_embedding(text) for text in texts]
# 임베딩 리스트를 NumPy 배열로 변환
embeddings_array = np.array(embeddings)
# 시각화를 위한 차원 축소 (t-SNE)
tsne = TSNE(n_components=2, random_state=42, perplexity=5)
reduced_embeddings = tsne.fit_transform(embeddings_array)
# 한글 폰트 경로 설정 (Windows 기준)
font_path = r'C:\Windows\Fonts\malgun.ttf' # 맑은 고딕 폰트 경로
# 폰트 프로퍼티 설정
font_prop = fm.FontProperties(fname=font_path, size=10)
# matplotlib 폰트 설정
plt.rcParams['font.family'] = font_prop.get_name()
# 그래프 그리기
plt.figure(figsize=(10, 8))
for i, (x, y) in enumerate(reduced_embeddings):
plt.scatter(x, y)
plt.annotate(texts[i], (x, y), xytext=(5, 5), textcoords='offset points', fontproperties=font_prop)
plt.title("정치 상황 텍스트 임베딩 시각화", fontproperties=font_prop)
# 그래프를 PNG 파일로 저장
plt.savefig('images/embeddings_visualization.png', dpi=300, bbox_inches='tight')
plt.show()
# 거리 측정 및 추천
def recommend(query, texts, embeddings, top_n=3):
query_embedding = get_embedding(query)
distances = [cosine(query_embedding, emb) for emb in embeddings]
sorted_indices = np.argsort(distances)
return [texts[i] for i in sorted_indices[:top_n]]
# 추천 예시
query = "기후 위기"
recommendations = recommend(query, texts, embeddings)
print(f"'{query}'와 가장 유사한 텍스트:")
for i, rec in enumerate(recommendations, 1):
print(f"{i}. {rec}")텍스트 → 벡터
텍스트를 OpenAI 임베딩 모형(text-embedding-ada-002)을 통해 1,536 차원 벡터로 변환시킨다.
코드
print(embeddings[1][:10])
[-0.021668272092938423, -0.018942788243293762, 0.013783353380858898, 0.0006076404242776334, -0.03229901194572449, 0.010813796892762184, -0.022183537483215332, 0.01155957579612732, -0.031404078006744385, 0.004132294096052647]벡터 시각화
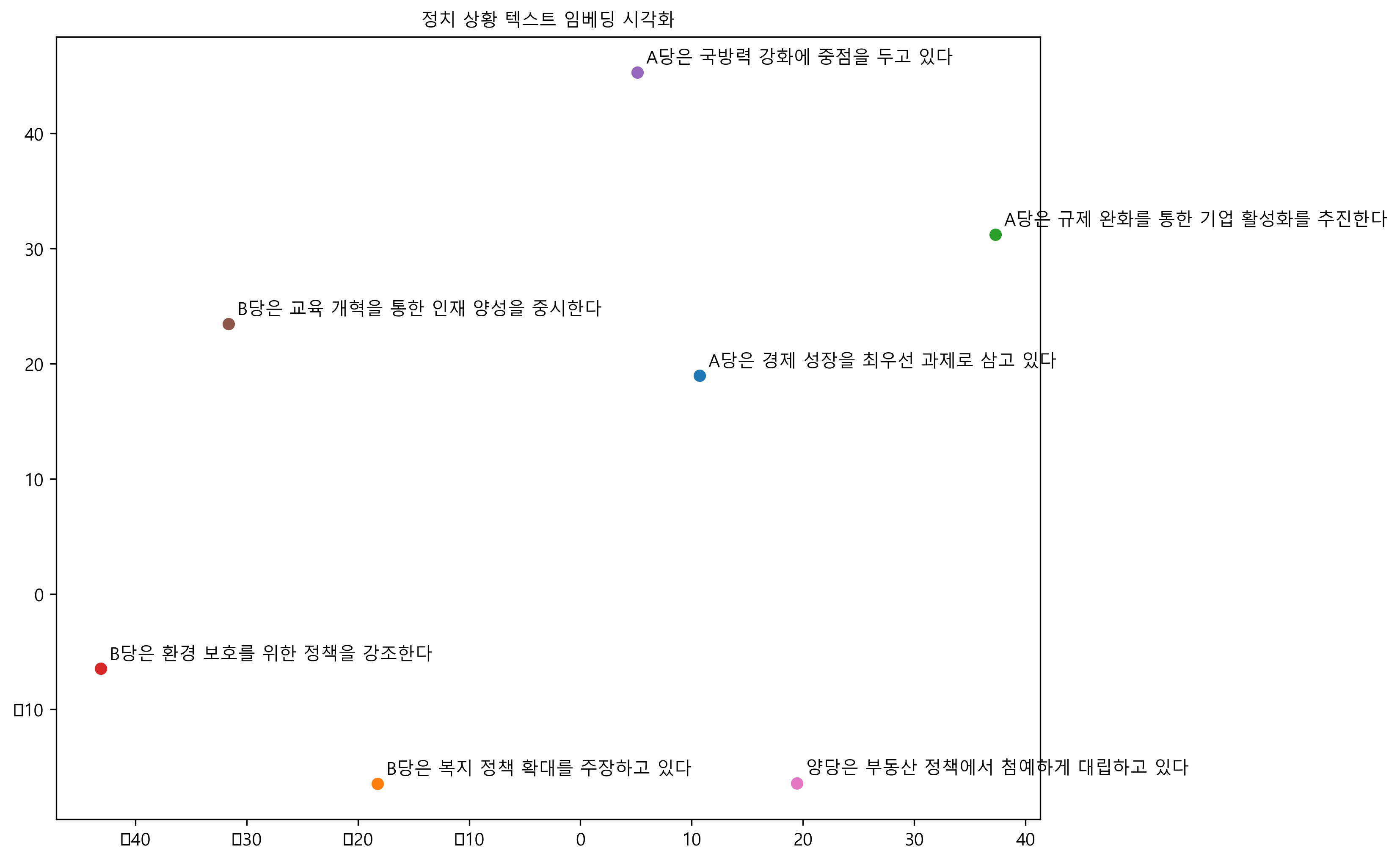
텍스트를 OpenAI 임베딩 모형(text-embedding-ada-002)을 통해 1,536 차원 벡터로 변환을 했는데 총 7개 문장에 대해 각 당의 정책적 차이를 시각적으로 확인하기 위해 차원축소기법으로 TSNE를 사용하여 2차원 공간을 축소하여 시각화하여 A당과 B당의 정책이 몰려있고 서로 다른 차이를 갖는 것을 확인할 수 있다.
벡터 검색
기후 위기와 가장 관련된 정책을 검색하는데 벡터 검색을 사용하여 가장 거리가 가까운 순으로 3개를 추출한다. 먼저 검색어를 get_embedding() 함수로 벡터로 변환하고 코사인 유사도(cosign()) 함수를 사용해서 거리를 계산하고 가장 거리가 가까운 정책을 출력한다.
'기후 위기'와 가장 유사한 텍스트:
1. B당은 환경 보호를 위한 정책을 강조한다
2. A당은 경제 성장을 최우선 과제로 삼고 있다
3. A당은 국방력 강화에 중점을 두고 있다감성분류
Zero-shot 임베딩 기반 감성분류
각 감정에 대한 예시 문장 대신, 감정을 설명하는 문장을 사용한다. 감정의 일반적인 개념을 사용하기 때문에 특정 예시에 의존하지 않하거나 휘둘리지 않는 장점이 있다. 특히 scipy 패키지 distance.cosine() 함수를 사용해서 거리를 사용한다는 점에서 차이가 있다.
코드
import numpy as np
from openai import OpenAI
from scipy.spatial import distance
from dotenv import load_dotenv
import os
load_dotenv()
# OpenAI 클라이언트 설정
client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
# 텍스트를 임베딩으로 변환하는 함수
def get_embedding(text):
response = client.embeddings.create(
model="text-embedding-ada-002",
input=text
)
return response.data[0].embedding
# 감정 레이블 정의
sentiments = ["긍정적인", "중립적인", "부정적인"]
# 감정 레이블에 대한 설명 텍스트
sentiment_descriptions = [
"이 문장은 긍정적인 감정이나 태도를 표현합니다.",
"이 문장은 중립적이거나 특별한 감정을 표현하지 않습니다.",
"이 문장은 부정적인 감정이나 태도를 표현합니다."
]
# 감정 설명의 임베딩 계산
sentiment_embeddings = [get_embedding(desc) for desc in sentiment_descriptions]
# 새로운 문장의 감정 분류 함수
def classify_sentiment(text):
text_embedding = get_embedding(text)
distances = [distance.cosine(text_embedding, sentiment_emb) for sentiment_emb in sentiment_embeddings]
closest_sentiment_index = np.argmin(distances)
return sentiments[closest_sentiment_index]
# 테스트
test_sentences = [
"오늘은 정말 행복한 날이에요!",
"그저 그런 하루였어요.",
"이 상황이 너무 힘들어요.",
"새로운 기회를 얻게 되어 기뻐요.",
"별로 특별한 감정은 없어요."
]
for sentence in test_sentences:
sentiment = classify_sentiment(sentence)
print(f"문장: '{sentence}'")
print(f"감정 분류: {sentiment}\n")문장: '오늘은 정말 행복한 날이에요!'
감정 분류: 긍정적인
문장: '그저 그런 하루였어요.'
감정 분류: 긍정적인
문장: '이 상황이 너무 힘들어요.'
감정 분류: 부정적인
문장: '새로운 기회를 얻게 되어 기뻐요.'
감정 분류: 긍정적인
문장: '별로 특별한 감정은 없어요.'
감정 분류: 중립적인Few-shot 임베딩 기반 감성분류
일반적인 개념이 아닌 몇가지 감성분류 사례를 제시하고 제시된 텍스트에 대한 감성을 분류한다.
코드
import numpy as np
from openai import OpenAI
from sklearn.metrics.pairwise import cosine_similarity
from dotenv import load_dotenv
import os
load_dotenv()
# OpenAI 클라이언트 설정
client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
# 텍스트를 임베딩으로 변환하는 함수
def get_embedding(text):
response = client.embeddings.create(
model="text-embedding-ada-002",
input=text
)
return response.data[0].embedding
# 감정 레이블과 예시 문장
sentiment_examples = {
"긍정": ["정말 좋은 하루였어요!", "이 영화 최고예요!", "새 직장이 너무 마음에 들어요."],
"중립": ["오늘 날씨는 평범해요.", "특별한 일은 없었어요.", "그냥 그래요."],
"부정": ["정말 최악의 경험이었어요.", "실망스러워요.", "오늘 기분이 좋지 않아요."]
}
# 각 감정 레이블에 대한 평균 임베딩 계산
sentiment_embeddings = {}
for sentiment, examples in sentiment_examples.items():
embeddings = [get_embedding(ex) for ex in examples]
sentiment_embeddings[sentiment] = np.mean(embeddings, axis=0)
# 새로운 문장의 감정 분류 함수
def classify_sentiment(text):
text_embedding = get_embedding(text)
similarities = {
sentiment: cosine_similarity([text_embedding], [emb])[0][0]
for sentiment, emb in sentiment_embeddings.items()
}
return max(similarities, key=similarities.get)
# 테스트
test_sentences = [
"오늘은 정말 행복한 날이에요!",
"그저 그런 하루였어요.",
"이 상황이 너무 힘들어요.",
"새로운 기회를 얻게 되어 기뻐요.",
"별로 특별한 감정은 없어요."
]
for sentence in test_sentences:
sentiment = classify_sentiment(sentence)
print(f"문장: '{sentence}'")
print(f"감정 분류: {sentiment}\n")문장: '오늘은 정말 행복한 날이에요!'
감정 분류: 긍정
문장: '그저 그런 하루였어요.'
감정 분류: 중립
문장: '이 상황이 너무 힘들어요.'
감정 분류: 부정
문장: '새로운 기회를 얻게 되어 기뻐요.'
감정 분류: 긍정
문장: '별로 특별한 감정은 없어요.'
감정 분류: 중립뉴스기사 분류
뉴스 기사의 토픽을 분류하는 기능구현도 가능하다. 먼저 7개의 주요 뉴스 토픽인 정치, 경제, 사회, 문화, 과학기술, 스포츠, 국제를 정의하고, 각 토픽에 대해 간단한 설명을 제공하여 Zero-shot 학습을 준비한다. OpenAI의 API를 사용하여 이 토픽 설명과 분류할 뉴스 기사 텍스트의 임베딩을 생성하고ㅡ, 토픽 분류는 주어진 뉴스 기사의 임베딩과 각 토픽 설명의 임베딩 간의 코사인 거리를 계산하여 수행한다. 가장 거리가 가까운, 즉 가장 유사한 토픽을 해당 기사의 토픽으로 선택한다.
코드
import numpy as np
from openai import OpenAI
from scipy.spatial import distance
from dotenv import load_dotenv
import os
load_dotenv()
# OpenAI 클라이언트 설정
client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
# 텍스트를 임베딩으로 변환하는 함수
def get_embedding(text):
response = client.embeddings.create(
model="text-embedding-ada-002",
input=text
)
return response.data[0].embedding
# 뉴스 토픽 정의
topics = ["정치", "경제", "사회", "문화", "과학기술", "스포츠", "국제"]
# 토픽에 대한 설명 텍스트
topic_descriptions = [
"정치와 관련된 뉴스로, 정부, 정책, 선거, 정당 등에 대한 내용을 다룹니다.",
"경제와 관련된 뉴스로, 금융, 주식, 기업, 무역 등에 대한 내용을 다룹니다.",
"사회와 관련된 뉴스로, 교육, 범죄, 환경, 복지 등 사회 전반의 이슈를 다룹니다.",
"문화와 관련된 뉴스로, 예술, 엔터테인먼트, 라이프스타일 등에 대한 내용을 다룹니다.",
"과학기술과 관련된 뉴스로, 연구, 발명, IT, 우주 등에 대한 내용을 다룹니다.",
"스포츠와 관련된 뉴스로, 각종 경기, 선수, 팀 등에 대한 내용을 다룹니다.",
"국제 뉴스로, 외교, 세계 각국의 주요 사건 등에 대한 내용을 다룹니다."
]
# 토픽 설명의 임베딩 계산
topic_embeddings = [get_embedding(desc) for desc in topic_descriptions]
# 뉴스 기사의 토픽 분류 함수
def classify_news_topic(news_text):
news_embedding = get_embedding(news_text)
distances = [distance.cosine(news_embedding, topic_emb) for topic_emb in topic_embeddings]
closest_topic_index = np.argmin(distances)
return topics[closest_topic_index]
# 테스트용 뉴스 기사 샘플
test_news_articles = [
"국회는 오늘 새로운 법안을 통과시켰다. 이번 법안은 청년 일자리 창출을 위한 것으로...",
"중앙은행은 기준금리를 0.25%p 인상했다고 발표했다. 이는 인플레이션 압력에 대응하기 위한 조치로...",
"올해 열린 칸 영화제에서 한국 영화가 대상을 수상했다. 이 영화는 사회적 불평등을 다룬...",
"NASA의 새로운 화성 탐사선이 성공적으로 발사되었다. 이 탐사선은 화성의 지질학적 특성을 연구할 예정이다...",
"월드컵 예선에서 한국 대표팀이 극적인 승리를 거뒀다. 경기 종료 직전 터진 골로..."
]
# 테스트 실행
for article in test_news_articles:
topic = classify_news_topic(article)
print(f"뉴스 기사: '{article[:50]}...'")
print(f"분류된 토픽: {topic}\n")뉴스 기사: '국회는 오늘 새로운 법안을 통과시켰다. 이번 법안은 청년 일자리 창출을 위한 것으로......'
분류된 토픽: 정치
뉴스 기사: '중앙은행은 기준금리를 0.25%p 인상했다고 발표했다. 이는 인플레이션 압력에 대응하기 위...'
분류된 토픽: 경제
뉴스 기사: '올해 열린 칸 영화제에서 한국 영화가 대상을 수상했다. 이 영화는 사회적 불평등을 다룬.....'
분류된 토픽: 사회
뉴스 기사: 'NASA의 새로운 화성 탐사선이 성공적으로 발사되었다. 이 탐사선은 화성의 지질학적 특성을...'
분류된 토픽: 과학기술
뉴스 기사: '월드컵 예선에서 한국 대표팀이 극적인 승리를 거뒀다. 경기 종료 직전 터진 골로......'
분류된 토픽: 스포츠데이터베이스
벡터 데이터베이스가 앞서 제시된 임베딩 방식 대신 필요한 이유는 이전 관계형 데이터베이스, 비정형 데이터베이스가 필요한 이유와 유사하다. 대규모 데이터셋을 효율적으로 처리할 수 있을 뿐만 아니라, 임베딩 벡터를 메모리에 모두 로드하는 기존 방식과 달리, 벡터 데이터베이스는 디스크 기반 저장과 인덱싱을 통해 대용량 데이터를 효과적으로 관리하는데 기여한다. 빠른 유사도 검색이 가능하여 특수한 인덱싱 기법을 사용하여 고차원 벡터 간의 유사도 계산을 최적화한다. 확장성이 뛰어나, 분산 아키텍처를 지원하여 데이터 규모가 커져도 성능을 유지할 수 있을 뿐만 아니라 실시간 업데이트와 쿼리가 가능하다.
다양한 벡터 데이터베이스 중 선택 시 고려할 점은 다음과 같다. 오픈소스 솔루션을 원한다면 커뮤니티 지원이 활발하고 무료로 사용할 수 있다는 장점이 있는 Chroma, Vespa, Milvus 등을 고려할 수 있다. 관리형 서비스를 제공하여 운영 부담을 줄일 수 있는 상용 솔루션을 고려한다면 Pinecone이나 Weaviate가 좋은 선택일 수 있다.
기존 관계형 데이터베이스와의 통합이 필요하다면 PostgreSQL의 벡터 검색 확장을 고려할 수 있다. 대규모 분산 시스템을 구축해야 한다면 Vespa나 Milvus가 적합할 수 있다. 검색 엔진 기능도 함께 필요하다면 Elasticsearch를 고려할 수 있다.
결국, 프로젝트 규모, 예산, 필요한 기능, 운영 능력 등을 종합적으로 고려하여 적절한 벡터 데이터베이스를 선택해야 한다. 소규모 프로젝트라면 Chroma나 LanceDB와 같은 가벼운 솔루션으로 시작하고, 대규모 프로덕션 환경이라면 Pinecone이나 Vespa 같은 성숙한 솔루션이 추천된다.
크로마DB
코드
import chromadb
from chromadb.config import Settings
from chromadb.utils import embedding_functions
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
# OpenAI 클라이언트 설정
openai_client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
# 임베딩 함수 정의
def get_embedding(texts):
# texts가 문자열인 경우 리스트로 변환
if isinstance(texts, str):
texts = [texts]
response = openai_client.embedding.create(
model="text-embedding-ada-002",
input=texts
)
return [item['embedding'] for item in response['data']]
# ChromaDB 임베딩 함수 생성
embedding_function = embedding_functions.OpenAIEmbeddingFunction(get_embedding)
# 지속성 저장소 경로 설정
persist_directory = "./data/chroma_db"
# ChromaDB 클라이언트 생성
client = chromadb.Client(Settings(
chroma_db_impl="duckdb+parquet",
persist_directory=persist_directory
))
# 컬렉션 생성 또는 기존 컬렉션 로드
collection_name = "persistent_news_articles"
if collection_name in client.list_collections():
collection = client.get_collection(name=collection_name, embedding_function=embedding_function)
print(f"기존 컬렉션 '{collection_name}'을 로드했습니다.")
else:
collection = client.create_collection(name=collection_name, embedding_function=embedding_function)
print(f"새 컬렉션 '{collection_name}'을 생성했습니다.")
# 문서 추가 (이미 존재하지 않는 경우에만)
if collection.count() == 0:
collection.add(
documents=[
"정부, 신재생에너지 정책 발표",
"중앙은행, 기준금리 동결 결정",
"AI 기술, 의료 분야 혁신 이끌어"
],
metadatas=[
{"category": "정치"},
{"category": "경제"},
{"category": "기술"}
],
ids=["1", "2", "3"]
)
print("문서를 추가했습니다.")
else:
print("기존 문서가 존재합니다.")
# 유사도 검색
results = collection.query(
query_texts=["최신 기술 동향"],
n_results=2
)
print("\n검색 결과:")
for i, (id, distance) in enumerate(zip(results['ids'][0], results['distances'][0])):
print(f"{i+1}. ID: {id}, 거리: {distance}")
print(f" 문서: {collection.get(ids=[id])['documents'][0]}")
print(f" 메타데이터: {collection.get(ids=[id])['metadatas'][0]}")
print()
# 메타데이터 필터링
filtered_results = collection.query(
query_texts=["경제 정책"],
where={"category": "경제"},
n_results=1
)
print("필터링된 검색 결과:")
print(f"문서: {filtered_results['documents'][0][0]}")
print(f"메타데이터: {filtered_results['metadatas'][0][0]}")
# 변경사항 저장
client.persist()
print("\n변경사항을 디스크에 저장했습니다.")
# 현재 컬렉션의 문서 수 출력
print(f"\n현재 컬렉션의 문서 수: {collection.count()}")