1 . R vs 파이썬
1.1 R 역사
Revolutions3에서 정리한 최근 R 역사는 1992년 처음 뉴질랜드 오클랜드에서 Robert Gentleman, Ross Ihaka 교수가 개발을 시작한 후에 GPL 라이선스를 장착하여 소스코드를 공개한 후에 R 코어 그룹이 만들어지고, 팩키지 배포 CRAN이 순차적으로 공개되고 나서, R 웹사이트가 만들어지고, 처음으로 2000년에 R 1.0.0 으로 배포되고 R 저널, UseR! 컨퍼런스, R 재단, R 컨소시엄이 전세계 수많은 재능있고 열정있는 수많은 사람에 의해서 만들어졌습니다.

R 연대기 및 한국 R 사용자회
1.2 R 우수성
한국 R 사용자회 일원으로 코딩 바람이 시작하던 2015년 세브란스 교수의
“정보교육을 위한 파이썬(Python for informatics)”를
번역하여 오픈 전자책으로 GitHub과
웹사이트 공개하면서 많은 경험을 하게 되었다.
파이썬이 좋은 프로그래밍 언어이기는 하지만 곧이어 접한 tidyverse 체계를 따르는 R 언어와는 비교가
불가능한 것 같다. 예를 들어 판다스 데이터프레임 구문은 과거 Base R 구문을
그대로 따르고 있다. 하지만 R은 과거 Base R의 경험을 바탕으로 한단계
업그레이된 tidyverse 체계로 진화했기 때문이다. 관련 자세한 사항은
데이터 사이언스 운영체제 - tidyverse, 한국통계학회 소식지 2019년 10월호에 정리되어 있다.
tidyverse R을 접하면서 저자는 파이썬을 손을 놓고 딥러닝 관련 새로운
기술이 나올 때 종종 필요에 따라 사용하고 있으며 대부분의 데이터 작업은 R을 사용하고 있다.
이런 경험은 저자에게만 국한된 것이 아니고 Alfonso R. Reyes의 경험과도 일치하고
관련 내용을 촘촘하게 정리하였기에 출처를 밝히고 번역하여 함께 합니다.4
저자는 10년이상 파이썬 응용프로그램을 작성했지만, 지금은 R을 사용하고 있다. R을 사용하진 2년이 지난 시점에서 파이썬 보다 R의 우수성에 대해서 10가지로 요약하고 있다.
간략히 요약하면, R은 데이터 과학과 기계학습 프로젝트에 이례적인 도구라고 볼 수 있다. R로 개발할 때 생산성은 훨씬 더 크게 느껴진다. 하지만, R을 익숙하게 다루는데는 시간이 다소 소요되기 때문에 시간에 대한 투자도 당근 고려되어야 한다. 특히, 파이썬이 근접할 수 없는 분야는 프로토타입을 개발할 때 재현성을 비롯한 상당한 매력과 장점이 있다. 파이썬은 다용도 언어로 데이터 과학 선택지로서 입지를 다져가고 있다.
- R은 과학, 통계학, 수학, 공학에 집중한다. 따라서 과학과 공학에 R로 접근하는 것이 엄청 필요하다.
- 지원에 대해서는 세계적이다. 어디를 가나 StackOverflow, 포럼, 트위터, 링크트인, 팟캐스트 등을 쉽게 접할 수 있고, R 커뮤니티 자체가 매우 이타적이라 모두 기꺼이 도움을 주고 받고 해서 R 실력이 더 향상되도록 한다.
- 재현성(reproducibility)이 황우석 사태 이후 큰 주목을 받고 있다. 재현성을 구현하는데 팩키지가 이미 다수 개발되어 있고 진화를 거듭하고 있다. 작업한 결과물은 팀뿐만 아니라, 외부에서도 재현되어야 하는데, 데이터 과학의 궁극의 목적으로 재현성을 최극단까지 도달할 수 있도록 R 커뮤니티가 노력을 경주하고 있다.
- 로마시절에 라틴어가 만인의 언어이고, 현재 영어가 전세계 공용어이듯이, R마크다운은 R에서 공용 의사소통언어로 자리 잡았다. R마크다운으로 보고서, 슬라이드, 학위논문, 논문, 책을 집필할 수 있다. R마크다운을 쥬피터 노트북과 비교하면 생산성이 1000:1 정도 될 것이다. 하지만, 반대로 R을 학습하는데 상당한 시간을 투여해야 되는 것도 사실이다.
- 정말 빠른 배포. RStudio 회사 직원이 어떻게 하는지 모르겠지만, 어쨌든 제품을 단 1,2년만에 뚝딱 만들어 냈다. Shiny를 말하고 싶은데, 파이썬으로 몇주 몇달 걸리는 것과 비교하여 단지, 몇분, 몇시간이면 뚝딱 웹앱을 배포할 수 있다. 다른 말로, 파이썬으로 개발한 것은 실무적으로 공유하기 힘들다(non-shareable).
- 가장 단순하면서도 최상의 통합개발환경(IDE)가 발명되었다. RStudio는 매우 단순하지만, 동시에 개발에 확장이 가능한 개발환경을 제공하고 있다. 처음에 믿을 수가 없겠지만, 작은 창 4개를 가지고 어마어마한 작업을 수행할 수 있다. 단순하지만 더 단순할 수 없도록 만들었다.
- 팩키지 품질관리. CRAN(the Comprehensive R Archive Network)에 팩키지를 올리려면 상당한 품질 기준을 만족해야 된다. 문서가 없는 팩키지는 승인되지 않는데, 이런 점이 현재 R을 만들었다. 현시점 기준 13,000개가 넘는 팩키지가 있는데 갯수가 중요한 것이 아니라, R을 강하고 확장가능하게 만든 것은 문서의 품질이라고 본다.
- 확장성(extendable). 팩키지 품질관리로 통해서 품질 좋은 팩키지가 만들어져서 이후 만들어지는 팩키지는 이런 토대위에 제작되어 더 좋은 팩키지로 거듭남. 누가 가장 혜택을 볼 수 있을까? 바로 사용자.
- 고품질 그래프.
matplotlib에 관해 무엇을 언급하든, Base 그래프, 그래프 문법 ggplot2 그래프에는 근접하지 못한다. Alfonso R. Reyes는 matplotlib을 오랜동안 사용했지만, 비표준 그래프는 뭐든지 맨땅에서부터 작성해야 했다. 반대로 R은 ggplot2를 비롯한 방대한 기능을 아직도 모두 소진해본적은 없는듯 싶다. 물론, 그래프에 대해 지켜야할 몇가지 기본 규칙이 부수적으로 따라온다: 다중 y축을 사용하지 말고, 원그래프는 피하고, 3D 그래프를 과사용하지 말고, 특별한 이유가 없다면 맨 처음부터 그래프 작성을 시작한다. - 함수(function) 중심. 파이썬과 R을 기본적으로 다르게 만드는 것 중 하나다. 클래스는 파아썬에서 남용에 가깝게 사용되곤 한다. 때로는 특별한 이유도 없다. 클래스와 객체형 프로그래밍을 배우려고 한다면, 파이썬을 추천한다. 세상에서 가장 배우기 쉬운 것 중 하나다. 이런 관점에 반대하여 R 세상은 다르다; 함수가 R세상에서는 첫째 시민(first class citizen)이다. 다른 언어와 달리 R에서 클래스는 함수 아래서 동작한다. S3와 S4는 자바와 파이썬 클래스와는 근본적으로 다르게 동작한다; 가장 가까운 친적이 R6가 될 듯 싶다.
1.3 자료구조
우리나라에서 대부분 프로그래밍은 컴퓨터 과학 언플러그드, 리보그, 파이썬을 통해 학습을 하기 때문에 파이썬이 친숙할 것이다. 변수 선언, 제어, 함수, 반복 등은 동일한 개념을 표기법을 달리하기 때문에 R을 처음 접할 때 기본 프로그래밍 개념만 있다면 큰 어려움이 없지만 아마도 자료구조에 대해서 대응관계를 파악하게 되면 이후 학습 과정은 수월할 듯 싶다.
다행히 2018년부터 reticulate 패키지가 개발되면서 사실 데이터 문제를 R, 파이썬 혹은 “R과 파이썬”으로
각자 장점을 살펴 데이터 괴물을 처치하는 것이 가능해졌다.
R Interface to Python에 R과 파이썬 자료구조가 잘 정리되어 있다.
| R | 파이썬 | 사례 |
|---|---|---|
| 단일 원소 벡터 | 스칼라 | 1, 1L, TRUE, “문자열” |
| 다중 원소 벡터 | 리스트 | c(1.0, 2.0, 30.), c(1L, 2L, 3L) |
| 다양한 자료형을 갖는 리스트 | 튜플 | list(1L, TRUE, “foo”) |
| 명칭갖는 리스트 | 딕셔너리 |
list(a = 1L, b = 2.0), dict(x = x_data)
|
| 행열/배열 | 넘파이 ndarrary | matrix(c(1,2,3,4), nrow = 2, ncol = 2) |
| 데이터프레임 | 판다스 데이터프레임 | data.frame(x = c(1,2,3), y = c(“a”, “b”, “c”)) |
| 함수 | 파이썬 함수 | function(x) x + 1 |
| NULL, TRUE, FALSE | None, True, False |
NULL, TRUE, FALSE
|
1.4 통계패키지 구성요소 5
R은 현존하는 가장 강력한 통계 컴퓨팅 언어로, 그래픽과 자료분석을 위해 언어 + 팩키지 + 환경이 하나로 묶여있다. 특히, 컴퓨터 주기억장치 한계가 존재하지만, 오픈 소스로 모든 코드가 공개되어 있어 자유로이 이용이 가능하다. R은 John Chambers가 주축이 되어 벨연구소에서 개발된 유닉스와 역사를 함께하는 S을 Ross Ihaka 와 Robert Gentleman이 1996년 구현하여 대중에게 공개하였다.
자료분석을 위해 대중에게 널리 알려진 통계팩키지에는 SAS, SPSS, Stata, Minitab 등 상업용으로 많이 판매되고 있다. 어떤 통계팩키지도 다음과 같은 공통된 5가지 구성요소를 포함하고 있다.
- 데이터 입력과 조작 언어
- 통계와 그래픽 명령어
- 출력물 관리 시스템
- 매크로 언어
- 행렬 언어(SAS IML/SPSS Matrix/Stata Mata)
이와 비교하여 R은 5가지 구성요소가 언어 + 팩키지 + 환경 으로 구성된다는 점에서 차이가 크다.
1.5 두 언어 문제 6
두 언어 문제로 인해 편리함을 위해 R, 파이썬, Matlab을 사용하고 C/C++, 포트란 시스템 언어로 속도가 중요한 작업을 수행했다. 근본적으로 중국집에서 짜장이냐 짬뽕을 선택하느냐에 따라 두 언어가 갖는 장점이 너무나도 명확하다. 하지만, 시스템 언어와 스크립트 언어의 두가지 문제점을 해결하기 위해서 두가지 다른 언어의 장점을 취하고 이를 보완하려는 노력이 지속적으로 경주되고 있다.
ODSC East 2016 - Stefan Karpinski - “Solving the Two Language Problem”
| 시스템 언어 | Ousterhout 이분법 | 스크립트 언어 |
|---|---|---|
| 정적 | – | 동적 |
| 컴파일 | – | 인터프리터 |
| 사용자정의 자료형 | – | 표준 자료형 |
| 빠른 속도 | – | 늦은 속도 |
| 어려움 | – | 쉬움 |
R Tidyverse 생태계에서 바라보는 또다른 관점은 기계처리시간(Machine time)과 사람생각시간(Human time)으로 나눠 바라보는 것이다. 기계관점을 바라보는 것이 파이썬이라면 사람 관점으로 바라보는 것이 R이라는 점에서 크게 대비된다.
1.6 데이터 과학 도구함
소프트웨어 개발과 통계 데이터 분석이 구분되어 독자적으로 발전되어 오다가 2000년대부터 데이터 사이언스의 원형이 되는 다양한 제품과 서비스들이 개발되면서 각 영역마다 특화된 도구들이 발전해나갔다. 선형대수는 매트랩, 통계 및 시각화는 R, 속도가 필요한 경우 C/C++, 통합작업을 위해 루비를 사용했다. 하지만, 2010년대에는 R과 파이썬에서 데이터를 기반으로 가치를 창출하는 소프트웨어 개발에 필요한 다양한 라이브러리와 패키지가 개발되면서 R 혹은 파이썬으로 전체 개발과정을 전담하고자 하는 노력이 생겨나면서 커다란 경쟁구도가 생겨났다. 하지만 2010년대 말부터 데이터 사이언스 문제를 가장 효율적인 도구를 통해 풀고자하면서 서로 다른 스킬셋을 갖춘 개발자들이 함께 개발하고 협업할 수 있는 환경과 경험이 축적되면서 이제는 R 과 파이썬을 모두 사용하는 방향으로 전환되었다.
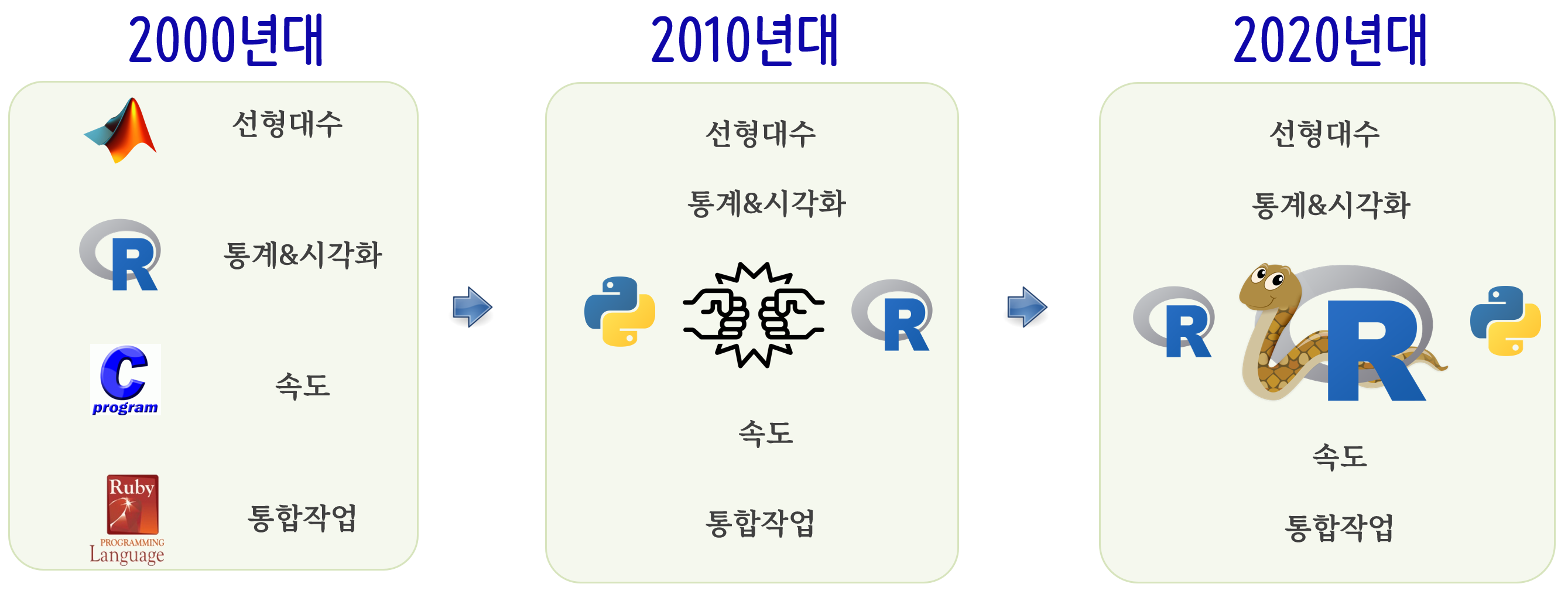
데이터 과학 툴체인