7 . 문자열
7.1 문자열은 순열이다.
문자열은 여러 문자들의 순열(sequence)이다. 꺾쇠 연산자로 한번에 하나씩 문자에 접근한다.
fruit <- 'banana'
fruit_letter <- strsplit(fruit, "")
letter <- fruit_letter[[1]][1]두 번째 문장은 변수 fruit_letter에서 1번 위치 문자를 추출하여 변수 letter에 대입한다.
꺾쇠 표현식을 인덱스(index)라고 부른다.
인덱스는 순서(sequence)에서 사용자가 어떤 문자를 원하는지 표시한다.
하지만, 여러분이 기대한 것은 출력됨이 확인된다.
letter## [1] "b"파이썬 사용자에게 ’banana’의 첫 분자는 a가 아니라 b다. 하지만, 파이썬 인텍스는 문자열 처음부터 오프셋(offset)8이다. 첫 글자 오프셋은 0 이다.
하지만, R은 사람 친화적이기 때문에 b가 ’banana’의 첫번째 문자가 되고 a가 두번째, n이 세번째 문자가 된다.
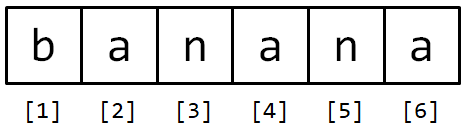
바나나 문자열
인덱스로 문자와 연산자를 포함하는 어떤 표현식도 사용가능지만, 인덱스 값은 정수일 필요는 없다.
정수가 아닌 경우 다음과 같은 결과를 얻게 된다. 문제는 R에서 1.5를 내려서 1로 처리한다는 점이다.
경우에 따라서는 반올림으로 판단해서 2가 될 수도 있어 오해의 소지가 있기 때문에 무조건 정수로 표현한다.
fruit_letter[[1]][1.5]## [1] "b"
7.2 length() 함수 사용 문자열 길이
length() 함수는 문자열의 문자 갯수를 반환하는 내장함수다.
## [1] 6문자열의 가장 마지막 문자를 얻기 위해서, 아래와 같이 시도하려 싶을 것이다.
len <- length(fruit_letter[[1]])
fruit_letter[[1]][len]## [1] "a"파이썬에서는 인덱스 오류 (IndexError)가 발생하는데 이유는 ‘banana’ 에 6번 인텍스 문자가 없기 때문이다. 0 에서부터 시작했기 때문에 6개 문자는 0 에서부터 5 까지 번호가 매겨졌다. 마지막 문자를 얻기 위해서 length에서 1을 빼야 한다. 하지만, R에서는 사람이 생각하는 방식대로 마지막 문자가 얻어진다.
7.3 루프를 사용한 문자열 순회
연산의 많은 경우에 문자열을 한번에 한 문자씩 처리한다.
종종 처음에서 시작해서, 차례로 각 문자를 선택하고, 선택된 문자에 임의 연산을 수행하고, 끝까지 계속한다.
이런 처리 패턴을 순회법(traversal)라고 한다.
순회법을 작성하는 한 방법이 while 루프다.
index <- 1
while(index <= length(fruit_letter[[1]])){
letter <- fruit_letter[[1]][index]
print(letter)
index <- index + 1
}## [1] "b"
## [1] "a"
## [1] "n"
## [1] "a"
## [1] "n"
## [1] "a"while 루프가 문자열을 운행하여 문자열을 한줄에 한 글자씩 화면에 출력한다.
루프 조건이 index <= length(fruit_letter[[1]])이여서, index가 문자열 길이와 같을 때,
조건은 거짓이 되고, 루프의 몸통 부문은 실행이 되지 않는다.
R이 접근한 마지막 length(fruit_letter[[1]]) 인텍스 문자로, 문자열의 마지막 문자다.
연습문제: 문자열의 마지막 문자에서 시작해서,
문자열 처음으로 역진행하면서 한줄에 한자씩 화면에 출력하는 while 루프를 작성하세요.
운행법을 작성하는 또 다른 방법은 for 루프다.
for(char in fruit_letter[[1]]) {
print(char)
}## [1] "b"
## [1] "a"
## [1] "n"
## [1] "a"
## [1] "n"
## [1] "a"루프를 매번 반복할 때, 문자열 다음 문자가 변수 char에 대입된다.
루프는 더 이상 남겨진 문자가 없을 때까지 계속 실행된다.
7.4 문자열 슬라이스
문자열의 일부분을 슬라이스(slice)라고 한다. 문자열 슬라이스를 선택하는 것은 문자를 선택하는 것과 유사하다.
## [1] "Monty"
paste(s[[1]][7:12], collapse="")## [1] "Python"[n:m] 연산자는 n번째 문자부터 m번째 문자까지의 문자열 부분을 반환한다.
파이썬 fruit[:3]와 같이 콜론 앞 첫 인텍스를 생략하면, 문자열 슬라이스는 문자열 처음부터 시작한다.
파이썬 fruit[3:]와 같이 두 번째 인텍스를 생략하면, 문자열 슬라이스는 문자열 끝까지 간다.
이와 동일한 역할을 수행하는 방법은 head(fruit_letter[[1]], 3), tail(fruit_letter[[1]], 3)와 같이
head(), tail() 함수를 활용한다.
## [1] "b" "a" "n"
tail(fruit_letter[[1]], 3)## [1] "a" "n" "a"만약 첫번째 인텍스가 두번째보다 크거나 같은 경우 파이썬에는 결과가 인용부호로 표현되는 빈 문자열(empty string)이 된다. 하지만, R에서는 해당 인덱스에 해당되는 문자가 추출된다.
fruit_letter[[1]][3:3]## [1] "n"
fruit_letter[[1]][2:1]## [1] "a" "b"빈 문자열은 어떤 문자도 포함하지 않아서 길이가 0 이 되지만, 이것을 제외하고 다른 문자열과 동일하다.
7.5 루프 돌기 계수
다음 프로그램은 문자열에 문자 a가 나타나는 횟수를 계수(counting)한다.
word <- strsplit('banana', "")
count <- 0
for(letter in word[[1]]) {
if(letter == 'a'){
count <- count + 1
}
}
count## [1] 3상기 프로그램은 계수기(counter)라고 부르는 또다른 연산 패턴을 보여준다.
변수 count는 0 으로 초기화 되고, 매번 a를 찾을 때마다 증가한다.
루프를 빠져나갔을 때, count는 결과 값 즉, a가 나타난 총 횟수를 담고 있다.
연습문제 : 문자열과 문자를 인자(argument)로 받도록 상기 코드를 count라는 함수로 캡슐화(encapsulation)하고 일반화하세요.
7.6 %in% 연산자
연산자 in 은 부울 연산자로 두 개의 문자열을 받아,
첫 번째 문자열이 두 번째 문자열의 일부이면 참(TRUE)을 반환한다.
## [1] TRUE## [1] FALSE7.7 문자열 비교
비교 연산자도 문자열에서 동작한다. 두 문자열이 같은지를 살펴보다.
word <- 'banana'
if(word == 'banana') {
print('All right, bananas.')
}## [1] "All right, bananas."다른 비교 연산자는 단어를 알파벳 순서로 정렬하는데 유용하다.
word <- 'Pineapple'
if(word < 'banana') {
cat('Your word', word, ' comes before banana.')
} else if (word > 'banana') {
cat('Your word', word, ' comes after banana.')
} else {
cat('All right, bananas.')
}## Your word Pineapple comes after banana.이러한 문제를 다루는 일반적인 방식은 비교 연산을 수행하기 전에 문자열을 표준 포맷으로 예를 들어 모두 소문자, 변환하는 것입니다. 경우에 따라서 “Pineapple”로 무장한 사람들로부터 여러분을 보호해야하는 것을 명심하세요.
7.8 문자열 함수
R은 객체지향언어의 특성을 갖고 있지만 함수형 프로그래밍 언어의 특성도 갖고 있다. 문자열을 R 객체(objects)로 객체를 데이터(실제 문자열 자체)와 메쏘드(methods)를 담고 있는 것으로 바라볼 수도 있다. 메쏘드는 객체에 내장되고 어떤 객체의 인스턴스(instance)에도 사용되는 사실상 함수다.
하지만, 함수형 프로그래밍 패러다임으로 문자열을 객체로 두고 함수를 적용시켜 다양한 작업을 하는 것이 일반적이다.
tidyverse 팩키지를 설치하게 되면 stringr 팩키지가 구성요소로 포함되어 있다.
str_로 시작되는 다양한 함수가 지원된다.
예를 들어, stringr 팩키지 str_to_upper() 함수는 문자열을 받아 모두 대문자로 변환된 새로운 문자열을 반환한다.
library(stringr)
word <- 'banana'
new_word <- stringr::str_to_upper(word)
new_word ## [1] "BANANA"동일한 작업을 함수형 패러다임으로 str_to_upper(word)와 같이 표현하는데 반해,
객체지향으로 구현하면 파이썬 같은 경우 word.upper() 메쏘드 구문이 사용된다.
예를 들어, 문자열안에 문자열의 위치를 찾는 str_locate(), str_locate_all()라는 문자열 함수가 있다.
str_locate()는 매칭되는 첫번째만 반환하는 반면에 str_locate_all()는 매칭되는 전부를 반환하는 차이가 있다.
str_locate(word, 'a')## start end
## [1,] 2 2상기 예제에서, word 문자열에 str_locate_all() 함수를 호출하여 매개 변수로 찾고자 하는 문자를 넘긴다.
str_locate_all() 함수로 문자뿐만 아니라 부속 문자열(substring)도 찾을 수 있다.
str_locate_all(word, 'na')## [[1]]
## start end
## [1,] 3 4
## [2,] 5 6한 가지 자주 있는 작업은 str_trim() 함수를 사용해서 문자열 시작과 끝의 공백(공백 여러개, 탭, 새줄)을 제거하는 것이다.
line <- ' Here we go '
str_trim(line)## [1] "Here we go"str_detect() 함수와 나중에 다룰 정규표현식을 섞어 표현하게 되면 참, 거짓 같은 부울 값(boolean value)을 반환한다. '^Please'에서 ^은 문자열 시작을 지정한다.
line <- 'Please have a nice day'
str_detect(line, '^Please')## [1] TRUE대소문자를 구별하는 것을 요구하기 때문에 str_to_lower() 함수를 사용해서 검증을 수행하기 전에,
한 줄을 입력받아 모두 소문자로 변환하는 것이 필요하다.
line <- 'Please have a nice day'
str_detect(line, '^p')## [1] FALSE
str_to_lower(line)## [1] "please have a nice day"
str_detect(str_to_lower(line), '^p')## [1] TRUE마지막 예제에서 문자열이 문자 “p”로 시작하는지를 검증하기 위해서,
str_to_lower() 함수를 호출하고 나서 바로 str_detect() 함수를 사용한다.
주의깊게 순서만 다룬다면, 한 줄에 다수 함수를 괄호에 넣어 호출할 수 있다.
연습문제: 앞선 예제와 유사한 함수인 str_count()로 불리는 문자열 메쏘드가 stringr 팩키지 내부에 있다.
? str_count() 도움말로 str_count() 함수에 대한 문서를 읽고,
문자열 ’banana’의 문자가 몇 개인지 계수하는 메쏘드 호출 프로그램을 작성하세요.
7.9 문자열 파싱
종종, 문자열을 들여다 보고 특정 부속 문자열(substring)을 찾고 싶다. 예를 들어, 아래와 같은 형식으로 작성된 일련의 라인이 주어졌다고 가정하면,
From stephen.marquard@uct.ac.zaSat Jan 5 09:14:16 2008
각 라인마다 뒤쪽 전자우편 주소(즉, uct.ac.za)만 뽑아내고 싶을 것이다.
str_locate() 함수와 문자열 슬라이싱(string sliceing)을 사용해서 작업을 수행할 수 있다.
우선, 문자열에서 골뱅이(@, at-sign) 기호의 위치를 찾는다.
그리고, 골뱅이 기호 뒤 첫 공백 위치를 찾는다.
그리고 나서, 찾고자 하는 부속 문자열을 뽑아내기 위해서 문자열 슬라이싱을 사용한다.
data <- 'From stephen.marquard@uct.ac.za Sat Jan 5 09:14:16 2008'
atpos <- str_locate(data, '@')
atpos## start end
## [1,] 22 22
sppos <- str_locate_all(data, ' ')
sppos## [[1]]
## start end
## [1,] 5 5
## [2,] 32 32
## [3,] 36 36
## [4,] 40 40
## [5,] 42 42
## [6,] 51 51
str_sub(data, start=atpos[1,1]+1, end=sppos[[1]][2,2]-1)## [1] "uct.ac.za"str_locate() 함수를 사용해서 찾고자 하는 문자열의 시작 위치를 명세한다.
문자열 슬라이싱(slicing)할 때, 골뱅기 기호 뒤부터 빈 공백을 포함하지 않는 위치까지 문자열을 뽑아낸다.
7.10 서식 연산자
서식 연산자(format operator) Base R의 sprintf() 함수에 C언어 스타일로 %를 사용하기도 하지만
glue: Interpreted String Literals 팩키지도 최근에 많이 사용된다.
glue 팩키지 {}는 문자열 일부를 변수에 저장된 값으로 바꿔 문자열을 구성한다.
정수에 서식 연산자가 적용될 때, {}는 나머지 연산자가 된다.
하지만 첫 피연산자가 문자열이면, {}은 서식 연산자가 된다.
첫 피연산자는 서식 문자열(format string)로 두번째 피연산자가 어떤 형식으로 표현되는지를 명세하는 하나 혹은 그 이상의 서식 순서(format sequence)를 담고 있다. 결과값은 문자열이다.
예를 들어, 형식 순서 ’%d’의 의미는 두번째 피연산자가 정수 형식으로 표현됨을 뜻한다. (d는 “decimal”을 나타낸다.)
camels <- 42
sprintf('%d', camels)## [1] "42"
glue::glue("{camels}")## 42결과는 문자열 ’42’로 정수 42와 혼동하면 안 된다.
서식 순서는 문자열 어디에도 나타날 수 있어서 문장 중간에 값을 임베드(embed)할 수 있다.
camels <- 42
sprintf('I have spotted %d camels.', camels)## [1] "I have spotted 42 camels."
glue::glue('I have spotted {camels} camels.')## I have spotted 42 camels.만약 문자열 서식 순서가 하나 이상이라면, 두번째 인자는 튜플(tuple)이 된다. 서식 순서 각각은 순서대로 튜플 요소와 매칭된다.
다음 예제는 정수 형식을 표현하기 위해서 ‘%d’, 부동 소수점 형식을 표현하기 위해서 ‘%g’, 문자열 형식을 표현하기 위해서 ‘%s’을 사용한 사례다. 여기서 왜 부동 소수점 형식이’%f’대신에 ’%g’인지는 질문하지 말아주세요.
> camels <- 42
> glue('I have spotted {camels} camels.')
I have spotted 42 camels.
> sprintf('I have spotted %d camels & %d camels', camels)
Error in sprintf("I have spotted %d camels & %d camels", camels) :
too few arguments
> camels <- "king"
> sprintf('I have spotted %d camels.', camels)
Error in sprintf("I have spotted %d camels.", camels) :
invalid format '%d'; use format %s for character objects문자열 서식 순서와 갯수는 일치해야 하고, 요소의 자료형(type)도 서식 순서와 일치해야 한다.
상기 첫 예제는 충분한 요소 개수가 되지 않고, 두 번째 예제는 자료형이 맞지 않는다.
서식 연산자는 강력하지만, 사용하기가 까다로운 점이 있으니, glue를 사용하는 것도 권장된다.
7.11 디버깅
프로그램을 작성하면서 배양해야 하는 기술은 항상 자신에게 질문을 하는 것이다. “여기서 무엇이 잘못 될 수 있을까?” 혹은 “내가 작성한 완벽한 프로그램을 망가뜨리기 위해 사용자는 무슨 엄청난 일을 할 것인가?”
예를 들어 앞장의 반복 while 루프를 시연하기 위해 사용한 프로그램을 살펴봅시다.
while(TRUE) {
line <- readline(prompt = '> ')
if(substr(line,1,1) == "#") {
next
}
if(line == 'done') {
break
}
print(line)
}사용자가 입력값으로 빈 공백 줄을 입력하게 될 때 무엇이 발생하는지 살펴봅시다.
> hello there
[1] hello there
> # don't print this
> print this!
[2] print this!
>
[1] ""
> done빈 공백줄이 입력될 때까지 코드는 잘 작동합니다. 그리고 나서, 파이썬의 경우 0 번째 문자가 없어서 트레이스백(traceback)이 발생한다. R의 경우 정상 실행되지만 원하는 바는 아니다. 입력줄이 비어있을 때, 코드 3번째 줄을 “안전”하게 만드는 두 가지 방법이 있다.
하나는 빈 문자열이면 거짓(FALSE)을 반환하도록 str_detect() 함수를 사용하는 것이다.
if(str_detect(line, '^#'))
가디언 패턴(guardian pattern)을 사용한 if문으로 문자열에 적어도 하나의 문자가 있는 경우만 두번째 논리 표현식이 평가되도록 코드를 작성한다.
if(str_length(line) > 0 & str_detect(line, '^#'))
7.12 용어정의
계수기(counter): 무언가를 계수하기 위해서 사용되는 변수로 일반적으로 0 으로 초기화하고 나서 증가한다. 빈 문자열(empty string): 두 인용부호로 표현되고, 어떤 문자도 없고 길이가 0 인 문자열. 서식 연산자(format operator): 서식 문자열과 튜플을 받아, 서식 문자열에 지정된 서식으로 튜플 요소를 포함하는 문자열을 생성하는 연산자, . 서식 순서(format sequence): d처럼 어떤 값의 서식으로 표현되어야 하는지를 명세하는 “서식 문자열” 문자 순서. 서식 문자열(format string): 서식 순서를 포함하는 서식 연산자와 함께 사용되는 문자열. 플래그(flag): 조건이 참인지를 표기하기 위해 사용하는 불 변수(boolean variable) 호출(invocation): 메쏘드를 호출하는 명령문. 불변(immutable): 순서의 항목에 대입할 수 없는 특성. 인덱스(index): 문자열의 문자처럼 순서(sequence)에 항목을 선택하기 위해 사용되는 정수 값. 항목(item): 순서에 있는 값의 하나. 메쏘드(method): 객체와 연관되어 점 표기법을 사용하여 호출되는 함수. 객체(object): 변수가 참조하는 무엇. 지금은 “객체”와 “값”을 구별없이 사용한다. 검색(search): 찾고자 하는 것을 찾았을 때 멈추는 운행법 패턴. 순서(sequence): 정돈된 집합. 즉, 정수 인텍스로 각각의 값이 확인되는 값의 집합. 슬라이스(slice): 인텍스 범위로 지정되는 문자열 부분. 운행법(traverse): 순서(sequence)의 항목을 반복적으로 훑기, 각각에 대해서는 동일한 연산을 수행.
7.13 연습문제
- 다음 문자열에서 숫자를 뽑아내는 R 코드로 작성하세요.
str <- 'X-DSPAM-Confidence: 0.8475'
str_locate() 함수와 문자열 슬라이싱을 사용하여 str_sub() 문자 뒤 문자열을 뽑아내고
as.numeric() 함수를 사용하여 뽑아낸 문자열을 부동 소수점 숫자로 변환하세요.