12 . 데이터프레임
다른 프로그래밍 언어에서 다루지 않는 독특한 자료구조가 데이터프레임(Dataframe)이다. R도 프로그래밍 언어이기 때문에 다른 언어에서 갖고 있는 자료구조를 대부분 갖추고 있지만, 데이터분석, 시각화, 모형개발 등에 꼭 필요한 기본 자료구조가 데이터프레임이다. 데이터프레임을 본격적으로 살펴보기 전에 통계학에서 다루는 측정에 대해 살펴보고, 측정 척도(scale)에 대한 이론적 배경을 이해한다. 척도의 개념에 대응되는 R 자료구조를 통해 데이터프레임과 추후 프로그래밍 과정에서 많이 다뤄지는 리스트에 대한 차별점도 살펴보자.
12.1 측정 변수의 구분 10 11 12
자료가 갖는 고유한 특성을 숫자료 표현한 측정 척도에 따라, 명목형, 순서형, 구간형, 비율형 네가지로 구분된다. 측정 척도에 따라 유의미한 통계량도 함께 정해진다. 자세한 사항은 Stevens, Stanley Smith. “On the theory of scales of measurement.” (1946). 논문을 참조한다.
- 명목척도(Nominal): 단순히 개체 특성 분류를 위해 숫자나 부호를 부여한 척도로 숫자는 의미가 없음.
- 남자: M, 여자: F 혹은 월: 1, 화: 2, … 일:7 혹은 갑:1, 을:2, 병:3, …
- 서열척도(Ordinal): 명목척도에 부가적으로 “순서(서열)” 정보가 추가된 척도로 측정대상 간 차이는 정보가 없음.
- 군대계급: 사병, 장교, 장군 등
- 소득계층: 1분위, 2분위, 3분위 등
- 등간척도(Interval): 서열척도에 부가적으로 “등간격” 정보가 추가된 척도
- 온도에서 0도는 상대적인 위치로 수학에서 다루는 개념과 차이가 있음.
- 온도가 서울 10도, 제주 20도는 제주가 서울보다 온도가 2배 높지 않음.
- 온도, 시력, IQ 지수, 물가지수 등
- 비율척도(Ratio): 구간척도에 “비율” 비교특성이 추가된 척도로 “비율 등간격” 특성이 포함됨.
- 키나 몸무게에서 0은 수학적 의미 0을 의미함.
- 100m는 200m의 절반 의미.
- 절대 ’0’을 가지고 사칙연산이 가능함.
- 연령, 월소득, TV 시청률 등.
12.2 자료구조 기본
R에서 기본으로 사용하는 벡터 자료형은 원자 벡터(Atomic Vector) 와 리스트(List) 로 나눠진다. 원자 벡터에는 6가지 자료형이 있고, logical, integer, double, character, complex, raw, 총 6 개가 있으며 주로, 논리형, 정수형, 부동소수점형, 문자형, 4가지를 많이 사용한다. 리스트는 재귀 벡터(recursive vector)라고도 불리는데 리스트는 다른 리스트를 포함할 수 있기 때문이다. 13
| 자료형(Type) | 모드(Mode) | 저장모드(Storage Mode) |
|---|---|---|
| logical | logical | logical |
| integer | numeric | integer |
| double | numeric | double |
| complex | complex | complex |
| character | character | character |
| raw | raw | raw |
따라서, 원자벡터는 동질적(homogeneous)이고, 리스트는 상대적으로 이질적(heterogeneous)이다.
모든 벡터는 두가지 성질(Property)을 갖는데, 자료형과 길이로 이를 확인하는데 typeof()와 length() 함수를 사용해서 확인한다.
## [1] "list"
length(a) ## [1] 4모드 함수는 객체의 모드를 반환하고, 클래스 함수는 클래스를 반환한다.
가장 흔하게 만나는 객체 모드는 숫자, 문자, 논리 모드다.
때때로 리스트와 데이터프레임과 같이 하나의 객체안에 여러 모드를 포함하기도 한다.
리스트(List)는 데이터를 저장하는 유연하며 강력한 방법으로 과거 리스트 자료구조를 처리하는 sapply 함수와 함께 가장 빈번하게 사용되는 자료형이다. 현재는 purrr 팩키지 map_*()함수를 사용한다.
리스트형 자료 a를 세가지 숫자형, 문자형, 숫자형, 리스트 네가지 자료형을 포함하게 작성한다.
sapply(), map_chr() 함수를 이용하여 mode와 class 인자를 넣어줌으로써, 각각 자료형의 모드와 자료형을 확인한다.
map_chr(a, mode) # sapply(a, mode)## a b c d
## "numeric" "character" "numeric" "list"
map_chr(a, class) # sapply(a, class)## a b c d
## "integer" "character" "numeric" "list"리스트에서 원소를 뽑아내는 의미를 살펴보자. 시각적으로 표현하면 다음과 같다.
리스트는 이질적인 객체를 담을 수 있다는 점에서 동질적인 것만 담을 수 있어 한계가 있는 원자벡터보다 쓰임새가 다르다.
회귀분석 결과 산출되는 lm 결과값은 다양한 정보를 담을 수 있는 리스트로 표현된다.
- 리스트 생성 :
list() - 하위 리스트 추출 :
[ - 리스트에 담긴 원소값 추출 :
[[,$→ 연산작업을 통해 위계를 갖는 구조를 제거한다.
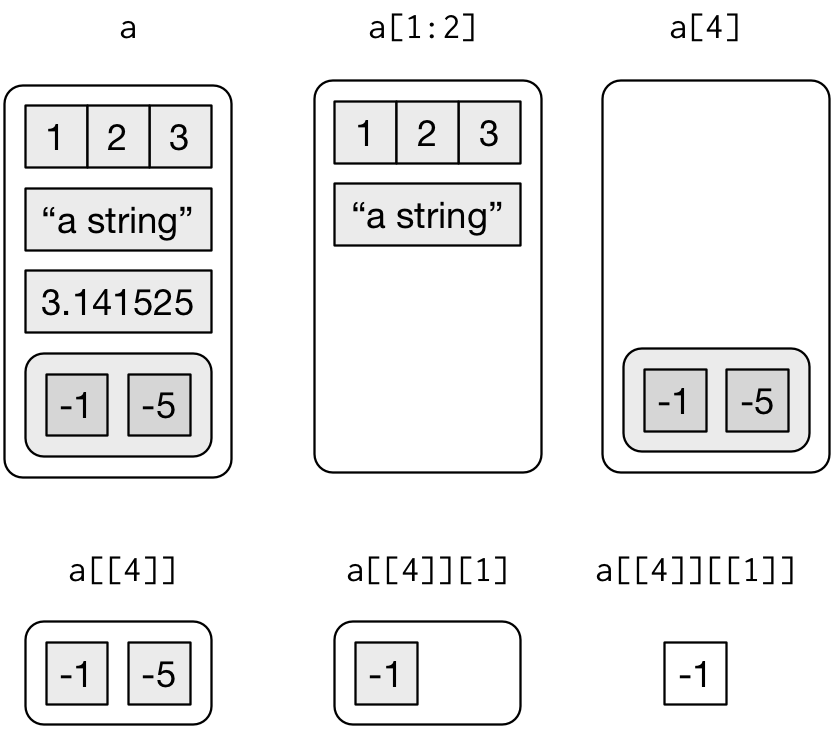
리스트에서 하위 리스트 뽑아내기 - 출처: 해들리 위컴
범주형 자료를 R에 저장하기 위해서 요인(Factor) 클래스를 사용하며 요인 클래스를 사용하여 자료를 저장할 경우 저장공간을 절약할 수 있다. 요인은 내부적으로 숫자(value)로 저장을 하고 레이블(value label)을 사용하여 표시하여 저장공간을 절약한다.
자료형 확인
각각의 데이터 형식에 맞는지를 다양한 테스트 함수(is.)를 이용하여 데이터 형식을 확인할 수 있다.
-
is.list: 리스트 형식인 확인 -
is.factor: 팩터 형식인지 확인 -
is.numeric: 숫자형인지 확인 -
is.data.frame: 데이터 프레임형인지 확인 -
is.character: 문자형인지 확인
12.3 자료형 확장
요인, 텍스트, 날짜와 시간도 중요한 R에서 자주 사용되는 중요한 데이터 자료형으로 별도로 다뤄진다.
이를 위해서 stringr, lubridate, forcats 팩키지를 사용해서 데이터 정제작업은 물론 기계학습 예측모형 개발에 활용한다.

데이터 과학 중요 자료구조
| R 자료형 | 자료형 | 예제 |
|---|---|---|
logical |
부울 | 부도여부(Y/N), 남여 |
integer |
정수 | 코로나19 감염자수 |
factor |
범주 | 정당, 색상 |
numeric |
실수 | 키, 몸무게, 주가, 환율 |
character |
텍스트 | 주소, 이름, 책제목 |
Date |
날짜 | 생일, 투표일 |
12.4 벡터, 행렬, 배열, 데이터프레임
가장 많이 사용되는 논리형, 문자형, 숫자형을 통해 자료분석 및 모형개발을 진행하게 되고, 경우에 따라서 동일한 자료형을 모은 경우 이를 행렬로 표현할 수 있고, 행렬을 모아 RGB 시각 데이터를 위한 배열(Array)로 표현한다. 데이터프레임은 서로 다른 자료형을 모아 넣은 것이다.
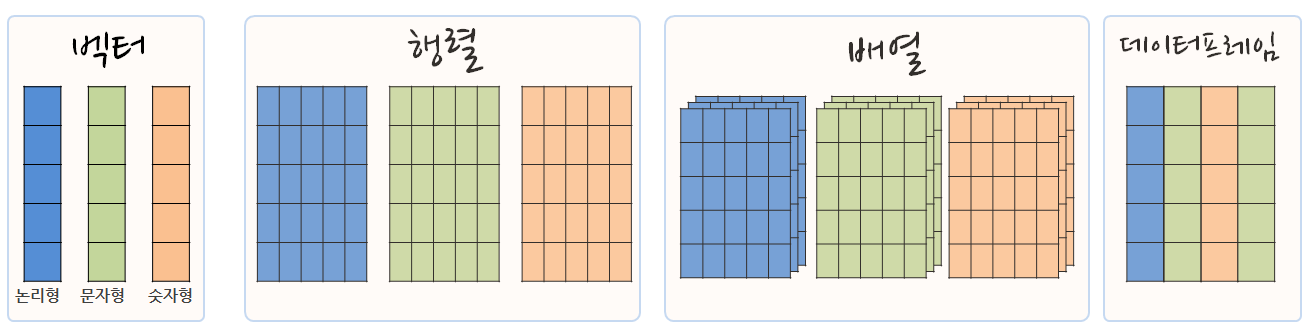
R 자료구조 - 벡터, 행렬, 배열, 데이터프레임
12.5 데이터프레임
R 은 6가지 기본 벡터로 자료를 저장하지만, 이외에 행렬(matrix), 데이터프레임(data.frame), 리스트(list) 자료구조가 있다.
하지만, 자료분석을 위해서 데이터를 데이터셋의 형태로 구성을 해야한다.
데이터셋이 중요한 이유는 자료를 분석하기 위해서 다양한 형태의 개별 자료를 통합적으로 분석하기 위해서다.
이를 위해서 리스트 자료구조로 일단 모으게 된다.
예를 들어 개인 신용분석을 위해서는 개인의 소득, 부채, 성별, 학력 등등의 숫자형, 문자형, 요인(Factor)형 등의 자료를 데이터셋에 담아야 한다.
특히 변수와-관측값 (Variable-Observation) 형식의 자료를 분석하기 위해서는 데이터프레임(data.frame)을 사용한다.
데이터프레임은 모든 변수에 대해서 관측값이 같은 길이를 갖도록 만들어 놓은 것이다.
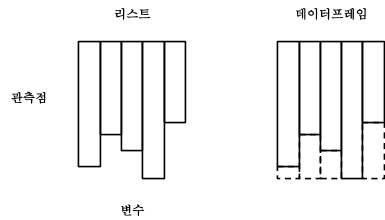
리스트와 데이터프레임
데이터프레임은 data.frame() 함수를 사용해서 생성한다.
R 객체 구조 파악을 위해서는 간단한 자료의 경우 데이터 형식을 확인할 수 있는 1–2줄 정도의 간단한 스크립트와 명령어를 통해서 확인이 가능하지만,
복잡한 데이터의 구조를 파악하기 위해서는 summary 함수와 str 함수를 통해서 확인해야 한다.
# 벡터를 정의한다.
name <- c("Mercury", "Venus", "Earth", "Mars", "Jupiter", "Saturn", "Uranus", "Neptune")
type <- c("Terrestrial planet", "Terrestrial planet", "Terrestrial planet",
"Terrestrial planet", "Gas giant", "Gas giant", "Gas giant", "Gas giant")
diameter <- c(0.382, 0.949, 1, 0.532, 11.209, 9.449, 4.007, 3.883)
rotation <- c(58.64, -243.02, 1, 1.03, 0.41, 0.43, -0.72, 0.67)
rings <- c(FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE, TRUE)
# 벡터를 합쳐서 데이터프레임을 생성
planets_df <-data.frame(name, type, diameter, rotation, rings)12.6 명목척도, 서열척도 범주 자료형
명목척도 범주형, 서열척도 범주 자료형을 생성하는 경우 주의를 기울여야 한다.
factor 함수를 사용해서 요인형 자료형을 생성하는데,
내부적으로 저장공간을 효율적으로 사용하고 속도를 빠르게 하는데 유용한다.
순서를 갖는 범주형의 경우 factor 함수 내부에 levels 인자를 넣어 정의하면 순서 정보가 유지된다.
# 범주형 - 명목척도
animals_vector <- c("Elephant", "Giraffe", "Donkey", "Horse")
factor_animals_vector <- factor(animals_vector)
factor_animals_vector## [1] Elephant Giraffe Donkey Horse
## Levels: Donkey Elephant Giraffe Horse
# 범주형 - 서열 척도
temperature_vector <- c("High", "Low", "High","Low", "Medium")
factor_temperature_vector <- factor(temperature_vector, order = TRUE, levels = c("Low", "Medium", "High"))
factor_temperature_vector## [1] High Low High Low Medium
## Levels: Low < Medium < High범주형 자료의 경우 범주가 갖는 척도 가독성을 높이기 위해 levels() 함수를 사용하기도 한다.
# "M", "F" 수준
survey_vector <- c("M", "F", "F", "M", "M")
factor_survey_vector <- factor(survey_vector)
levels(factor_survey_vector)## [1] "F" "M"
# "Female", "Male" 로 변환
levels(factor_survey_vector) <- c("Female", "Male")
levels(factor_survey_vector)## [1] "Female" "Male"통계 처리와 자료분석에 문자형 벡터와 요인 범주형 벡터를 다른 의미를 갖는 점에 유의한다.
동일한 summary() 함수지만 입력 자료형에 따라 R은 적절한 후속 작업을 자동 수행한다.
# 문자형 벡터와 요인 벡터
survey_vector <- c("M", "F", "F", "M", "M")
factor_survey_vector <- factor(survey_vector)
# 문자형 벡터 요약
summary(survey_vector)## Length Class Mode
## 5 character character
# 요인 벡터 요약
summary(factor_survey_vector)## F M
## 2 3
12.7 NULL과 NA 결측값
결측되었다는 없다는 것을 표시하는 방법이 두가지 필요하다. 하나는 벡터가 없다는 NULL이고,
벡터 내부에 값이 결측되었다는 NA 다. dataframe$variable <- NULL 명령문을 사용하면 데이터프레임(dataframe)에 변수(variable)를 날려보내는 효과가 있다.
예를 들어 책장이 아예 없다는 의미(NULL)와 책장에 책이 없다(NA)는 다른 개념을 지칭하고 쓰임새가 다르다.
NA의 중요한 특징은 전염된다는 것이다. 즉, NA에 연산을 가하면 연산결과는 무조건 NA가 된다.
NA가 7보다 큰지, 7을 더하고 빼고, 부울 연산을 하든 NA와 연산결과는 무조건 NA가 된다.
NA + 7## [1] NA
NA / 7## [1] NA
NA > 7## [1] NA
7 == NA## [1] NA
NA == NA## [1] NA12.8 리스트 칼럼 14 15
레고를 통해 살펴본 R 자료구조는 계산가능한 원자 자료형(논리형, 숫자형, 요인형)으로 크게 볼 수 있다. R에서 정수형과 부동소수점은 그다지 크게 구분을 하지 않는다. 동일 길이를 갖는 벡터를 쭉 붙여넣으면 자료구조형이 데이터프레임으로 되고, 길이가 갖지 않는 벡터를 한 곳에 모아넣은 자료구조가 리스트다.
데이터프레임이 굳이 모두 원자벡터만을 갖출 필요는 없다. 리스트를 데이터프레임 내부에 갖는 것도
데이터프레임인데 굳이 구별하자면 티블(tibble)이고, 이런 자료구조를 리스트-칼럼(list-column)이라고 부른다.

리스트 칼럼
리스트-칼럼 자료구조가 빈번히 마주하는 경우가 흔한데… 대표적으로 다음 사례를 들 수 있다.
- 정규표현식을 통한 텍스트 문자열 처리
- 웹 API로 추출된 JSON, XML 데이터
- 분할-적용-병합(Split-Apply-Combine) 전략
데이터프레임이 티블(tibble) 형태로 되어 있으면 다음 작업을 나름 수월하게 추진할 수 있다.
- 들여다보기(Inspect): 데이터프레임에 무엇이 들었는지 확인.
- 인덱싱(Indexing): 명칭 혹은 위치를 확인해서 필요한 원소를 추출.
- 연산(Compute): 리스트-칼럼에 연산 작업을 수행해서 또다른 벡터나 리스트-칼럼을 생성.
- 간략화(Simplify): 리스트-칼럼을 익숙한 데이터프레임으로 변환.