14 . 네트워크 프로그램
지금까지 책의 많은 예제는 파일을 읽고 파일의 정보를 찾는데 집중했지만, 다양한 많은 정보의 원천이 인터넷에 있다.
이번 장에서는 웹브라우져로 가장하고 HTTP 프로토콜(HyperText Transport Protocol,HTTP)을 사용하여 웹페이지를 검색할 것이다. 웹페이지 데이터를 읽고 파싱할 것이다.
파이썬 튜플과 마찬가지로 R에서 네트워크 프로그래밍을 위해 소켓까지 내려가서 프로그래밍을 할 경우는 많지 않다. 하지만 네트워크 프로그램에 대한 이해와 개념을 잡기 위해 파이썬 소켓 네트워크 프로그래밍을 먼저 살펴본다.
14.1 하이퍼 텍스트 전송 프로토콜
웹에 동력을 공급하는 네트워크 프로토콜(HyperText Transport Protocol - HTTP)은
실제로 매우 단순하다.
파이썬에는 소켓 (sockets)이라고 불리는 내장 지원 모듈이 있다. 파이썬
프로그램에서 소켓 모듈을 통해서 네트워크 연결을 하고, 데이터 검색을 매우
용이하게 한다.
소켓(socket)은 단일 소켓으로 두 프로그램 사이에 양방향 연결을 제공한다는 점을 제외하고 파일과 매우 유사하다. 동일한 소켓에 읽거나 쓸 수 있다. 소켓에 무언가를 쓰게 되면, 소켓의 다른 끝에 있는 응용프로그램에 전송된다. 소켓으로부터 읽게 되면, 다른 응용 프로그램이 전송한 데이터를 받게 된다.
하지만, 소켓의 다른쪽 끝에 프로그램이 어떠한 데이터도 전송하지 않았는데 소켓을 읽으려고 하면, 단지 앉아서 기다리기만 한다. 만약 어떠한 것도 보내지 않고 양쪽 소켓 끝의 프로그램 모두 기다리기만 한다면, 모두 매우 오랜 시간동안 기다리게 될 것이다.
인터넷으로 통신하는 프로그램의 중요한 부분은 특정 종류의 프로토콜을 공유하는 것이다. 프로토콜(protocol)은 정교한 규칙의 집합으로 누가 메시지를 먼저 보내고, 메세지로 무엇을 하며, 메시지에 대한 응답은 무엇이고, 다음에 누가 메세지를 보내고 등등을 포함한다. 이런 관점에서 소켓 끝의 두 응용프로그램이 함께 춤을 추고 있으니, 다른 사람 발을 밟지 않도록 확인해야 한다.
네트워크 프로토콜을 기술하는 문서가 많이 있다. 하이퍼텍스트 전송 프로토콜(HyperText Transport Protocol)은 다음 문서에 기술되어 있다.
http://www.w3.org/Protocols/rfc2616/rfc2616.txt
매우 상세한 176 페이지나 되는 장문의 복잡한 문서다. 흥미롭다면 시간을
가지고 읽어보기 바란다. RFC2616에 36 페이지를 읽어보면, GET
요청(request)에 대한 구문을 발견하게 된다. 꼼꼼히 읽게 되면, 웹서버에
문서를 요청하기 하기 위해서, 80 포트로 www.py4inf.com 서버에 연결을
하고 나서 다음 양식 한 라인을 전송한다.
GET http://www.py4inf.com/code/romeo.txt HTTP/1.0
두번째 매개변수는 요청하는 웹페이지가 된다. 그리고 또한 빈 라인도 전송한다. 웹서버는 문서에 대한 헤더 정보와 빈 라인 그리고 문서 본문으로 응답한다.
14.2 가장 간단한 웹 브라우져
아마도 HTTP 프로토콜이 어떻게 작동하는지 알아보는 가장 간단한 방법은 매우 간단한 파이썬 프로그램을 작성하는 것이다. 웹서버에 접속하고 HTTP 프로토콜 규칙에 따라 문서를 요청하고 서버가 다시 보내주는 결과를 보여주는 것이다.
import socket
mysock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
mysock.connect(('data.pr4e.org', 80))
cmd = 'GET http://data.pr4e.org/romeo.txt HTTP/1.0\r\n\r\n'.encode()
mysock.send(cmd)
while True:
data = mysock.recv(512)
if len(data) < 1:
break
print(data.decode(),end='')
mysock.close()처음에 프로그램은 www.py4e.com 서버에 80 포트로 연결한다. “웹 브라우져” 역할로 작성된 프로그램이 하기 때문에 HTTP 프로토콜은 GET 명령어를 공백 라인과 함께 보낸다.
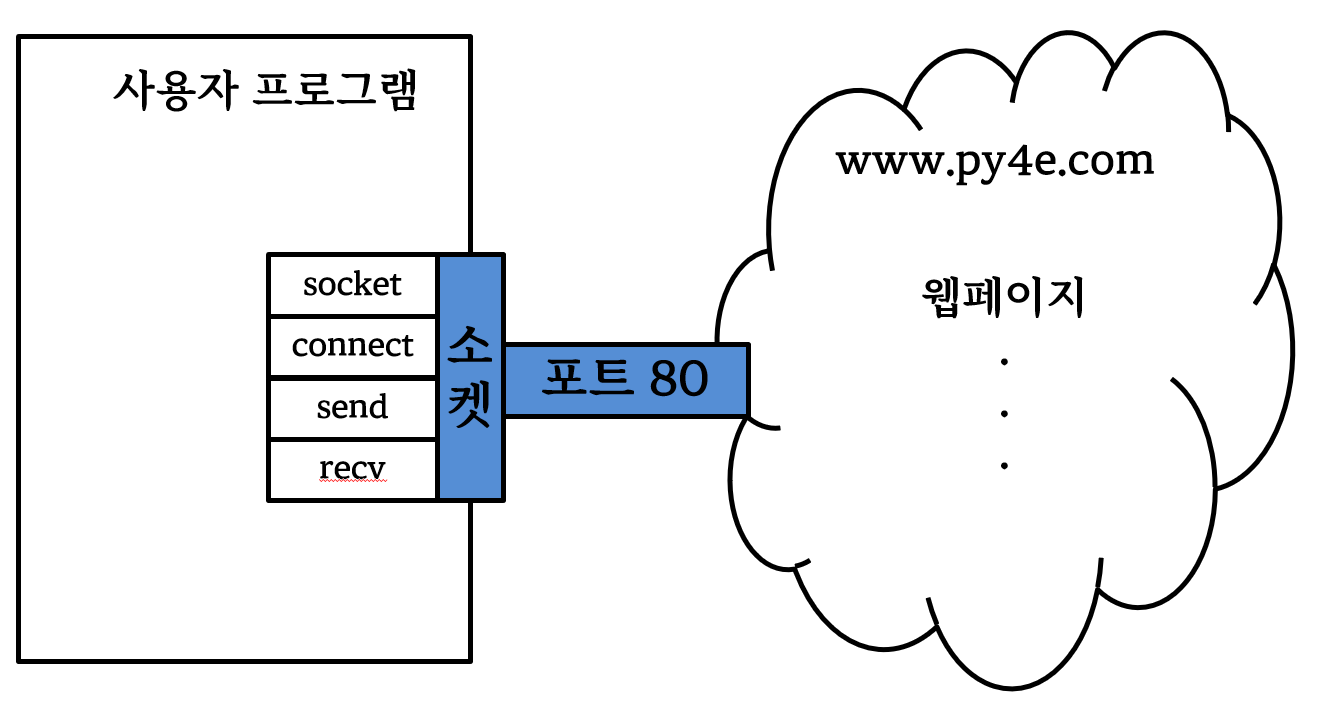
소켓 개념도
공백 라인을 보내자 마자, 512 문자 덩어리의 데이터를 소켓에서 받아 더 이상 읽을 데이터가 없을 때까지(즉, recv()이 빈 문자열을 반환한다.) 데이터를 출력하는 루프를 작성한다.
프로그램 실행결과 다음을 얻을 수 있다.
HTTP/1.1 200 OK
Date: Wed, 11 Apr 2018 18:52:55 GMT
Server: Apache/2.4.7 (Ubuntu)
Last-Modified: Sat, 13 May 2017 11:22:22 GMT
ETag: "a7-54f6609245537"
Accept-Ranges: bytes
Content-Length: 167
Cache-Control: max-age=0, no-cache, no-store, must-revalidate
Pragma: no-cache
Expires: Wed, 11 Jan 1984 05:00:00 GMT
Connection: close
Content-Type: text/plain
But soft what light through yonder window breaks
It is the east and Juliet is the sun
Arise fair sun and kill the envious moon
Who is already sick and pale with grief출력결과는 웹서버가 문서를 기술하기 위해서 보내는 헤더(header)로
시작한다. 예를 들어, Content-Type 헤더는 문서가 일반 텍스트
문서(text/plain)임을 표기한다.
서버가 헤더를 보낸 후에, 빈 라인을 추가해서 헤더 끝임을 표기하고 나서
실제 파일romeo.txt을 보낸다.
이 예제를 통해서 소켓을 통해서 저수준(low-level) 네트워크 연결을 어떻게 하는지 확인할 수 있다. 소켓을 사용해서 웹서버, 메일 서버 혹은 다른 종류의 서버와 통신할 수 있다. 필요한 것은 프로토콜을 기술하는 문서를 찾고 프로토콜에 따라 데이터를 주고 받는 코드를 작성하는 것이다.
하지만, 가장 흔히 사용하는 프로토콜은 HTTP (즉, 웹) 프로토콜이기 때문에, 파이썬에는 HTTP 프로토컬을 지원하기 위해 특별히 설계된 라이브러리가 있다. 이것을 통해서 웹상에서 데이터나 문서를 검색을 쉽게 할 수 있다.
14.3 HTTP 경유 이미지 가져오기
상기 예제에서는 파일에 새줄(newline)이 있는 일반 텍스트 파일을 가져왔다. 그리고 나서, 프로그램을 실행해서 데이터를 단순히 화면에 복사했다. HTTP를 사용하여 이미지를 가져오도록 비슷하게 프로그램을 작성할 수 있다. 프로그램 실행 시에 화면에 데이터를 복사하는 대신에, 데이터를 문자열로 누적하고, 다음과 같이 헤더를 잘라내고 나서 파일에 이미지 데이터를 저장한다.
import socket
import time
HOST = 'data.pr4e.org'
PORT = 80
mysock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
mysock.connect((HOST, PORT))
mysock.sendall(b'GET http://data.pr4e.org/cover3.jpg HTTP/1.0\r\n\r\n')
count = 0
picture = b""
while True:
data = mysock.recv(5120)
if len(data) < 1: break
#time.sleep(0.25)
count = count + len(data)
print(len(data), count)
picture = picture + data
mysock.close()
# Look for the end of the header (2 CRLF)
pos = picture.find(b"\r\n\r\n")
print('Header length', pos)
print(picture[:pos].decode())
# Skip past the header and save the picture data
picture = picture[pos+4:]
fhand = open("stuff.jpg", "wb")
fhand.write(picture)
fhand.close()
# Code: http://www.py4e.com/code3/urljpeg.py프로그램을 실행하면, 다음과 같은 출력을 생성한다.
$ python urljpeg.py
5120 5120
5120 10240
4240 14480
5120 19600
...
5120 214000
3200 217200
5120 222320
5120 227440
3167 230607
Header length 393
HTTP/1.1 200 OK
Date: Wed, 11 Apr 2018 18:54:09 GMT
Server: Apache/2.4.7 (Ubuntu)
Last-Modified: Mon, 15 May 2017 12:27:40 GMT
ETag: "38342-54f8f2e5b6277"
Accept-Ranges: bytes
Content-Length: 230210
Vary: Accept-Encoding
Cache-Control: max-age=0, no-cache, no-store, must-revalidate
Pragma: no-cache
Expires: Wed, 11 Jan 1984 05:00:00 GMT
Connection: close
Content-Type: image/jpeg상기 url에 대해서, Content-Type 헤더가 문서 본문이
이미지(image/jpeg)를 나타내는 것을 볼 수 있다. 프로그램이 완료되면,
이미지 뷰어로 stuff.jpg 파일을 열어서 이미지 데이터를 볼 수 있다.
프로그램을 실행하면, recv() 메쏘드를 호출할 때 마다 5120 문자는
전달받지 못하는 것을 볼 수 있다. recv() 호출하는 순간마다 웹서버에서
네트워크로 전송되는 가능한 많은 문자를 받을 뿐이다. 매번 5120 문자까지
요청하지만, 1460 혹은 2920 문자만 전송받는다.
결과값은 네트워크 속도에 따라 달라질 수 있다. recv() 메쏘드 마지막
호출에는 스트림 마지막인 1681 바이트만 받았고, recv() 다음 호출에는 0
길이 문자열을 전송받아서, 서버가 소켓 마지막에 close() 메쏘드를
호출하고 더이상의 데이터가 없다는 신호를 준다.
주석 처리한 time.sleep()을 풀어줌으로써 recv() 연속 호출을 늦출 수
있다. 이런 방식으로 매번 호출 후에 0.25초 기다리게 한다. 그래서,
사용자가 recv() 메쏘드를 호출하기 전에 서버가 먼저 도착할 수 있어서 더
많은 데이터를 보낼 수가 있다. 정지 시간을 넣어서 프로그램을 다시
실행하면 다음과 같다.
$ python urljpeg.py
5120 5120
5120 10240
5120 15360
...
5120 225280
5120 230400
207 230607
Header length 393
HTTP/1.1 200 OK
Date: Wed, 11 Apr 2018 21:42:08 GMT
Server: Apache/2.4.7 (Ubuntu)
Last-Modified: Mon, 15 May 2017 12:27:40 GMT
ETag: "38342-54f8f2e5b6277"
Accept-Ranges: bytes
Content-Length: 230210
Vary: Accept-Encoding
Cache-Control: max-age=0, no-cache, no-store, must-revalidate
Pragma: no-cache
Expires: Wed, 11 Jan 1984 05:00:00 GMT
Connection: close
Content-Type: image/jpegrecv() 메쏘드 호출의 처음과 마지막을 제외하고, 매번 새로운 데이터를
요청할 때마다 이제 5120 문자가 전송된다.
서버 send() 요청과 응용프로그램 recv() 요청 사이에 버퍼가 있다.
프로그램에 지연을 넣어 실행하게 될 때, 어느 지점엔가 서버가 소켓 버퍼를
채우고 응용프로그램이 버퍼를 비울 때까지 잠시 멈춰야 된다. 송신하는
응용프로그램 혹은 수신하는 응용프로그램을 멈추게 하는 행위를 “흐름
제어(flow control)”이라고 한다.
14.4 httr 웹페이지 가져오기
수작업으로 소켓 라이브러리를 사용하여 HTTP로 데이터를 주고 받을 수
있지만, httr 패키지를 사용하여 R에서 동일한 작업을 수행하는
좀더 간편한 방식이 있다.
httr을 사용하여 파일처럼 웹페이지를 다룰 수가 있다. 단순하게 어느
웹페이지를 가져올 것인지만 지정하면 httr 라이브러리가 모든 HTTP
프로토콜과 헤더 관련 사항을 처리해 준다.
웹에서 romeo.txt 파일을 읽도록 urllib를 사용하여 작성한 상응 코드는
다음과 같다.
library(httr)
fhand <- httr::GET('http://www.py4inf.com/code/romeo.txt')
httr::content(fhand, encoding = "UTF-8")GET() 함수를 사용하여 웹페이지를 열게 되면, 파일처럼 다룰 수 있고
content() 함수를 사용해서 데이터를 읽을 수 있다.
프로그램을 실행하면, 파일 내용 출력결과만을 볼 수 있다. 헤더정보는
여전히 전송되었지만, GET() 함수가 헤더를 받아 내부적으로 처리하고,
사용자에게는 단지 데이터만 반환한다.
## [1] "But soft what light through yonder window breaks\nIt is the east and Juliet is the sun\nArise fair sun and kill the envious moon\nWho is already sick and pale with grief\n"예제로, romeo.txt 데이터를 가져와서 파일의 각 단어 빈도를 계산하는
프로그램을 다음과 같이 작성할 수 있다. 웹페이지를 로컬 텍스트로 변환시킨 후에
공백과 \n 으로 텍스트를 잘게 쪼개고, 단어 빈도수를 table()로 계산한 후
데이터 문법 dplyr을 사용해서 최빈 단어를 상위 3개 뽑는다.
## # A tibble: 3 × 2
## 단어 빈도수
## <chr> <int>
## 1 and 3
## 2 is 3
## 3 the 3다시 한번, 웹페이지를 열게 되면, 로컬 파일처럼 웹페이지를 읽을 수 있다.
14.5 HTML 파싱과 웹 스크래핑
R httr 패키지를 활용하는 일반적인 사례는 웹 스크래핑(scraping)이다.
웹 스크래핑은 웹브라우저를 가장한 프로그램을 작성하는 것이다. 웹페이지를
가져와서, 패턴을 찾아 페이지 내부의 데이터를 꼼꼼히 조사한다. 예로,
구글같은 검색엔진은 웹 페이지의 소스를 조사해서 다른 페이지로 가는
링크를 추출하고, 그 해당 페이지를 가져와서 링크 추출하는 작업을
반복한다. 이러한 기법으로 구글은 웹상의 거의 모든 페이지를
거미(spiders)줄처럼 연결한다.
구글은 또한 발견한 웹페이지에서 특정 페이지로 연결되는 링크 빈도를 사용하여 얼마나 중요한 페이지인지를 측정하고 검색결과에 페이지가 얼마나 높은 순위로 노출되어야 하는지 평가한다.
14.6 정규 표현식 사용 HTML 파싱하기
HTML을 파싱하는 간단한 방식은 정규 표현식을 사용하여 특정한 패턴과 매칭되는 부속 문자열을 반복적으로 찾아 추출하는 것이다.
여기 간단한 웹페이지가 있다.
<h1>The First Page</h1>
<p>
If you like, you can switch to the
<a href="http://www.dr-chuck.com/page2.htm">
Second Page</a>.
</p>모양 좋은 정규표현식을 구성해서 다음과 같이 상기 웹페이지에서 링크를 매칭하고 추출할 수 있다.
href="http://.+?"작성된 정규 표현식은 “href=http://"로 시작하고, 하나 이상의 문자를”.+?” 가지고 큰 따옴표를 가진 문자열을 찾는다. “.+?”에 물음표가 갖는 의미는 매칭이 “욕심쟁이(greedy)” 방식보다 “비욕심쟁이(non-greedy)” 방식으로 수행됨을 나타낸다. 비욕심쟁이(non-greedy) 매칭방식은 가능한 가장 적게 매칭되는 문자열을 찾는 방식이고, 욕심 방식은 가능한 가장 크게 매칭되는 문자열을 찾는 방식이다.
추출하고자 하는 문자열이 매칭된 문자열의 어느 부분인지를 표기하기 위해서 정규 표현식에 괄호를 추가하여 다음과 같이 프로그램을 작성한다.
library(tidyverse)
library(httr)
url <- readline(prompt = "Enter - ")
html <- httr::GET(url)
url_link <- str_extract_all(html, pattern = 'href="(http://.*?)"')
print(url_link)str_extract_all 정규 표현식 함수는 정규 표현식과 매칭되는 모든 문자열
리스트를 추출하여 큰 따옴표 사이에 링크 텍스트만을 반환한다.
쉘에서 Rscript.exe 프로그램으로 실행하기 위해 다음과 같이 사용자 입력을 받는 부분을
다음과 같이 수정한다.
# urlregex.R 프로그램 코드
library(httr)
typeline <- function(msg = "Enter - ") {
if (interactive() ) {
url <- readline(msg)
} else {
cat(msg);
url <- readLines("stdin",n=1);
}
return(url)
}
url <- typeline()
html <- httr::GET(url)
url_link <- stringr::str_extract_all(html, pattern = 'href="(http://.*?)"')
print(url_link)프로그램을 실행하면, 다음 출력을 얻게된다.
$ Rscript.exe ./script/urlregex.R
During startup - Warning message:
Setting LC_CTYPE=ko_KR.UTF-8@cjknarrow failed
Enter - http://www.dr-chuck.com/page1.htm
No encoding supplied: defaulting to UTF-8.
Warning message:
In stri_extract_all_regex(string, pattern, simplify = simplify, :
argument is not an atomic vector; coercing
[[1]]
[1] "href=\"http://www.dr-chuck.com/page2.htm\""
$ Rscript.exe ./script/urlregex.R
During startup - Warning message:
Setting LC_CTYPE=ko_KR.UTF-8@cjknarrow failed
Enter - http://www.py4inf.com/book.htm
No encoding supplied: defaulting to UTF-8.
Warning message:
In stri_extract_all_regex(string, pattern, simplify = simplify, :
argument is not an atomic vector; coercing
[[1]]
[1] "href=\"http://amzn.to/1KkULF3\""
[2] "href=\"http://www.py4e.com/book\""
[3] "href=\"http://amzn.to/1KkULF3\""
[4] "href=\"http://amzn.to/1hLcoBy\""
[5] "href=\"http://amzn.to/1KkV42z\""
[6] "href=\"http://amzn.to/1fNOnbd\""
[7] "href=\"http://amzn.to/1N74xLt\""
[8] "href=\"http://do1.dr-chuck.net/py4inf/EN-us/book.pdf\""
[9] "href=\"http://do1.dr-chuck.net/py4inf/ES-es/book.pdf\""
[10] "href=\"http://do1.dr-chuck.net/py4inf/PT-br/book.pdf\""
[11] "href=\"http://www.xwmooc.net/python/\""
[12] "href=\"http://fanwscu.gitbooks.io/py4inf-zh-cn/\""
[13] "href=\"http://itunes.apple.com/us/book/python-for-informatics/id554638579?mt=13\""
[14] "href=\"http://www-personal.umich.edu/~csev/books/py4inf/ibooks//python_for_informatics.ibooks\""
[15] "href=\"http://www.py4inf.com/code\""
[16] "href=\"http://www.greenteapress.com/thinkpython/thinkCSpy/\""
[17] "href=\"http://allendowney.com/\""정규 표현식은 HTML이 예측가능하고 잘 구성된 경우에 멋지게 작동한다. 하지만, “망가진” HTML 페이지가 많아서, 정규 표현식만을 사용하는 솔류션은 유효한 링크를 놓치거나 잘못된 데이터만 찾고 끝날 수 있다.
이 문제는 강건한 HTML 파싱 라이브러리를 사용해서 해결될 수 있다.
14.7 `rvest`` 사용한 HTML 파싱
HTML을 파싱하여 페이지에서 데이터를 추출할 수 있는 R 패키지는 많이 있다. 패키지 각각은 강점과 약점이 있어서 사용자 필요에 따라 취사선택한다.
예로, 간단하게 HTML 입력을 파싱하여 rvest 라이브러리를 사용하여 링크를 추출할 것이다.
HTML이 XML 처럼 보이고 몇몇 페이지는 XML로 되도록 꼼꼼하게 구축되었지만, 일반적으로 대부분의 HTML이 깨져서 XML 파서가 HTML 전체 페이지를 잘못 구성된 것으로 간주하고 받아들이지 않는다. `rvest`` 패키지는 결점 많은 HTML 페이지에 내성이 있어서 사용자가 필요로하는 데이터를 쉽게 추출할 수 있게 한다.
httr 패키지를 사용하여 페이지를 읽어들이고, rvest를 사용해서 앵커
태그 (a)로부터 href 속성을 추출한다.
library(httr)
library(rvest)
html <- httr::GET('http://www.dr-chuck.com/page1.htm')
webpage <- rvest::read_html(html)
a_href <- webpage %>%
html_elements("a") %>%
html_attr("href")
print(a_href)프로그램이 웹 주소를 입력받고, 웹페이지를 열고, 데이터를 읽어서
BeautifulSoup 파서에 전달하고, 그리고 나서 모든 앵커 태그를 불러와서 각
태그별로 href 속성을 출력한다.
쉘에서 Rscript.exe 프로그램으로 실행하기 위해 다음과 같이 사용자 입력을 받는 부분을
다음과 같이 수정한다.
## urllinks.R 스크립트
library(httr)
library(rvest)
typeline <- function(msg = "Enter - ") {
if (interactive() ) {
url <- readline(msg)
} else {
cat(msg);
url <- readLines("stdin",n=1);
}
return(url)
}
url <- typeline()
html <- httr::GET(url)
webpage <- rvest::read_html(html)
a_href <- webpage %>%
html_elements("a") %>%
html_attr("href")
print(a_href)프로그램을 실행하면, 아래와 같다.
$ Rscript.exe ./script/urllinks.R
During startup - Warning message:
Setting LC_CTYPE=ko_KR.UTF-8@cjknarrow failed
Enter - http://www.dr-chuck.com/page1.htm
[1] "http://www.dr-chuck.com/page2.htm"
$ Rscript.exe ./script/urllinks.R
During startup - Warning message:
Setting LC_CTYPE=ko_KR.UTF-8@cjknarrow failed
Enter - http://www.py4inf.com/book.htm
[1] "http://amzn.to/1KkULF3"
[2] "http://www.py4e.com/book"
[3] "http://amzn.to/1KkULF3"
[4] "http://amzn.to/1hLcoBy"
[5] "http://amzn.to/1KkV42z"
[6] "http://amzn.to/1fNOnbd"
[7] "http://amzn.to/1N74xLt"
[8] "http://do1.dr-chuck.net/py4inf/EN-us/book.pdf"
[9] "http://do1.dr-chuck.net/py4inf/ES-es/book.pdf"
[10] "https://twitter.com/fertardio"
[11] "http://do1.dr-chuck.net/py4inf/PT-br/book.pdf"
[12] "https://twitter.com/victorjabur"
[13] "translations/KO/book_009_ko.pdf"
[14] "http://www.xwmooc.net/python/"
[15] "http://fanwscu.gitbooks.io/py4inf-zh-cn/"
[16] "book_270.epub"
[17] "translations/ES/book_272_es4.epub"
[18] "https://www.gitbook.com/download/epub/book/fanwscu/py4inf-zh-cn"
[19] "html-270/"
[20] "html_270.zip"
[21] "http://itunes.apple.com/us/book/python-for-informatics/id554638579?mt=13"
[22] "http://www-personal.umich.edu/~csev/books/py4inf/ibooks//python_for_informatics.ibooks"
[23] "http://www.py4inf.com/code"
[24] "http://www.greenteapress.com/thinkpython/thinkCSpy/"
[25] "http://allendowney.com/"`rvest``을 사용하여 다음과 같이 각 태그별로 다양한 부분을 뽑아낼 수 있다.
library(httr)
library(rvest)
typeline <- function(msg = "Enter - ") {
if (interactive() ) {
url <- readline(msg)
} else {
cat(msg);
url <- readLines("stdin",n=1);
}
return(url)
}
url <- typeline()
html <- httr::GET(url)
webpage <- rvest::read_html(html)
a_href <- webpage %>%
html_elements("a") %>%
html_attr("href")
a_text <- webpage %>%
html_elements("a") %>%
html_text() %>%
stringr::str_remove("\n")
cat("URL: ", a_href, "\n")
cat("Content:", a_text)상기 프로그램은 다음을 출력합니다.
$ Rscript.exe ./script/urllinks2.R
During startup - Warning message:
Setting LC_CTYPE=ko_KR.UTF-8@cjknarrow failed
Enter - http://www.dr-chuck.com/page1.htm
URL: http://www.dr-chuck.com/page2.htm
Content: Second PageHTML을 파싱하는데 rvest가 가진 강력한 기능을 예제로 보여줬다.
좀더 자세한 사항은 https://rvest.tidyverse.org/ 에서 문서와 예제를
살펴보세요.
14.8 바이너리 파일 읽기
이미지나 비디오 같은 텍스트가 아닌 (혹은 바이너리) 파일을 가져올 때가
종종 있다. 일반적으로 이런 파일 데이터를 출력하는 것은 유용하지 않다.
하지만, download.file() 함수를 사용하여, 하드 디스크 로컬 파일에 URL 사본을 쉽게
만들 수 있다.
download.file() 함수 내부에 인터넷에 공개된 이미지 url을 적고,
destfile 에는 로컬파일에 저장할 파일명을 적어준다.
중요한 것은 텍스트가 아니라 바이너리 이미지라 mode = "wb"를 지정한다.
download.file(url = "http://www.py4inf.com/cover.jpg",
destfile = "assets/images/fox.jpeg", mode="wb")작성된 프로그램은 네트워크로 모든 데이터를 한번에 읽어서 컴퓨터
cover.jpg 파일을 다운로드 받아 로컬 디스크에 지정한 디렉토리 파일명으로
데이터를 쓴다. 이 방식은 파일 크기가 사용자 컴퓨터의 메모리 크기보다
작다면 정상적으로 작동한다.

바이너리 파일 다운로드
UNIX 혹은 매킨토시 컴퓨터를 가지고 있다면, 다음과 같이 상기 동작을 수행하는 명령어가 운영체제 자체에 내장되어 있다.
curl -O http://www.py4inf.com/cover.jpg14.9 용어정의
- BeautifulSoup: 파이썬 라이브러리로 HTML 문서를 파싱하고 브라우저가 일반적으로 생략하는 HTML의 불완전한 부분을 보정하여 HTML 문서에서 데이터를 추출한다. www.crummy.com 사이트에서 BeautifulSoup 코드를 다운로드 받을 수 있다.
-
**rvest**: 파이썬 BeautifulSoup에 대응되는 R 크롤링 패키징
- 포트(port): 서버에 소켓 연결을 만들 때, 사용자가 무슨 응용프로그램을 연결하는지 나타내는 숫자. 예로, 웹 트래픽은 통상 80 포트, 전자우편은 25 포트를 사용한다.
- 스크래핑(scraping): 프로그램이 웹브라우저를 가장하여 웹페이지를 가져와서 웹 페이지의 내용을 검색한다. 종종 프로그램이 한 페이지의 링크를 따라 다른 페이지를 찾게 된다. 그래서, 웹페이지 네트워크 혹은 소셜 네트워크 전체를 훑을 수 있다.
- 소켓(socket): 두 응용프로그램 사이 네트워크 연결. 두 응용프로그램은 양 방향으로 데이터를 주고 받는다.
- 스파이더(spider):검색 색인을 구축하기 위해서 한 웹페이지를 검색하고, 그 웹페이지에 링크된 모든 페이지 검색을 반복하여 인터넷에 있는 거의 모든 웹페이지를 가져오기 위해서 사용되는 검색엔진 행동.
14.10 연습문제
소켓 프로그램
socket1.py을 변경하여 임의 웹페이지를 읽을 수 있도록 URL을 사용자가 입력하도록 바꾸세요.split(’/’)을 사용하여 URL을 컴포턴트로 쪼개서 소켓connect호출에 대해 호스트 명을 추출할 수 있다. 사용자가 적절하지 못한 형식 혹은 존재하지 않는 URL을 입력하는 경우를 처리할 있도록try,except를 사용하여 오류 검사기능을 추가하세요.소켓 프로그램을 변경하여 전송받은 문자를 계수(count)하고 3000 문자를 출력한 후에 그이상 텍스트 출력을 멈추게 하세요. 프로그램은 전체 문서를 가져와야 하고, 전체 문자를 계수(count)하고, 문서 마지막에 문자 계수(count)결과를 출력해야 합니다.
httr패키지를 사용하여 이전 예제를 반복하세요. (1) 사용자가 입력한 URL에서 문서 가져오기 (2) 3000 문자까지 화면에 보여주기 (3) 문서의 전체 문자 계수(count)하기. 이 연습문제에서 헤더에 대해서는 걱정하지 말고, 단지 문서 본문에서 첫 3000 문자만 화면에 출력하세요.urllinks.R프로그램을 변경하여 가져온 HTML 문서에서 문단 (p) 태그를 추출하고 프로그램의 출력물로 문단을 계수(count)하고 화면에 출력하세요. 문단 텍스트를 화면에 출력하지 말고 단지 숫자만 셉니다. 작성한 프로그램을 작은 웹페이지 뿐만 아니라 조금 큰 웹 페이지에도 테스트해 보세요.(고급) 소켓 프로그램을 변경하여 헤더와 빈 라인 다음에 데이터만 보여지게 하세요.
recv는 라인이 아니라 문자(새줄(newline)과 모든 문자)를 전송받는다는 것을 기억하세요.