



flowchart TB
subgraph A["사용자 인터페이스"]
direction LR
CLI["CLI<br>Command Line Interface<br> 1950~"] --> GUI["GUI <br> Graphic User Inferface<br> 1970~"]
GUI --> WI["Web Interface <br> 1994~"]
WI --> MI["Mobile Interface <br> 2007~"]
MI --> NUI["LUI <br> Language User Interface <br> 2023~"]
end
class A nodeStyle
classDef nodeStyle fill:#fcfbfa,stroke:#000000,stroke-width:0.7px,font-weight:bold,font-size:14px;
챗GPT
챗GPT 실무교육
2023년 5월 30일
강사소개 & 강의 개요
AI 아바타

주요경력 및 학력
(현) 비영리법인 한국 R 사용자회: 기술 이사
(현) 국가교육위원회 전문위원: 과학/기술 분과
(전) TCS: GS 칼텍스 디지털 아카데미 강사
(전) 삼정 KPMG: Lighthouse AI 기술총괄
(전) 웹젠: 데이터 과학자 TD
(전) 현대자동차: 차량용 반도체 개발구매
KAIST, CMU, 연세대 응용통계 및 컴퓨터 과학 전공
RStudio Instructor - Tidyverse

강의상세
- 날짜 : 2023. 5. 30.(화) 01:30~04:30
- 장소 : 안양시 정보화 교육장
- 대상 : 안양시 공무원 30명
- 내용
- (텍스트) 챗GPT 프롬프트 엔지니어링
- (코딩) 엑셀
- (그리기) Text-to-Image
서울 R 미트업




구글 검색의 종말(?)
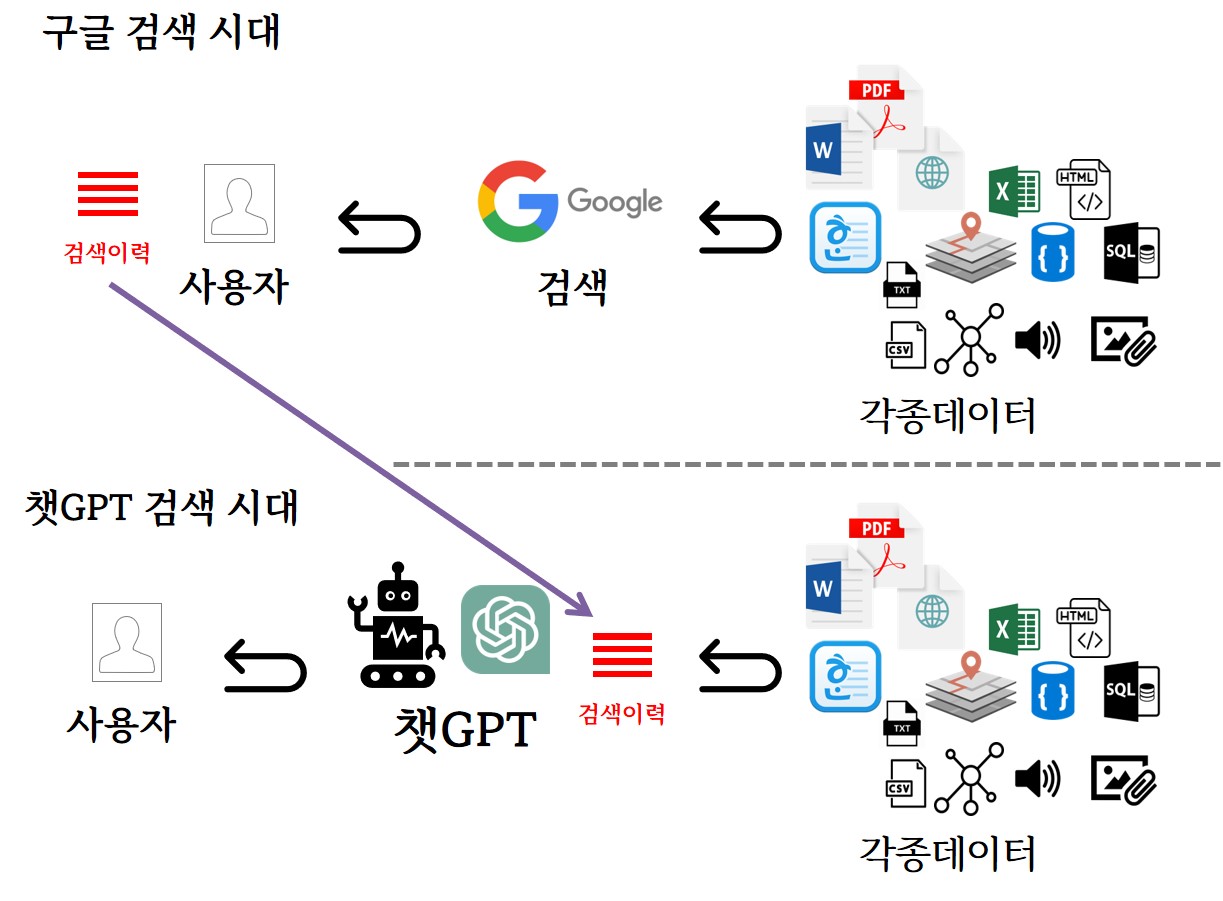
글쓰기 역사

오피스 전쟁: 패러다임 충돌

챗GPT 시대 사무실
챗GPT가 이룬 대통합
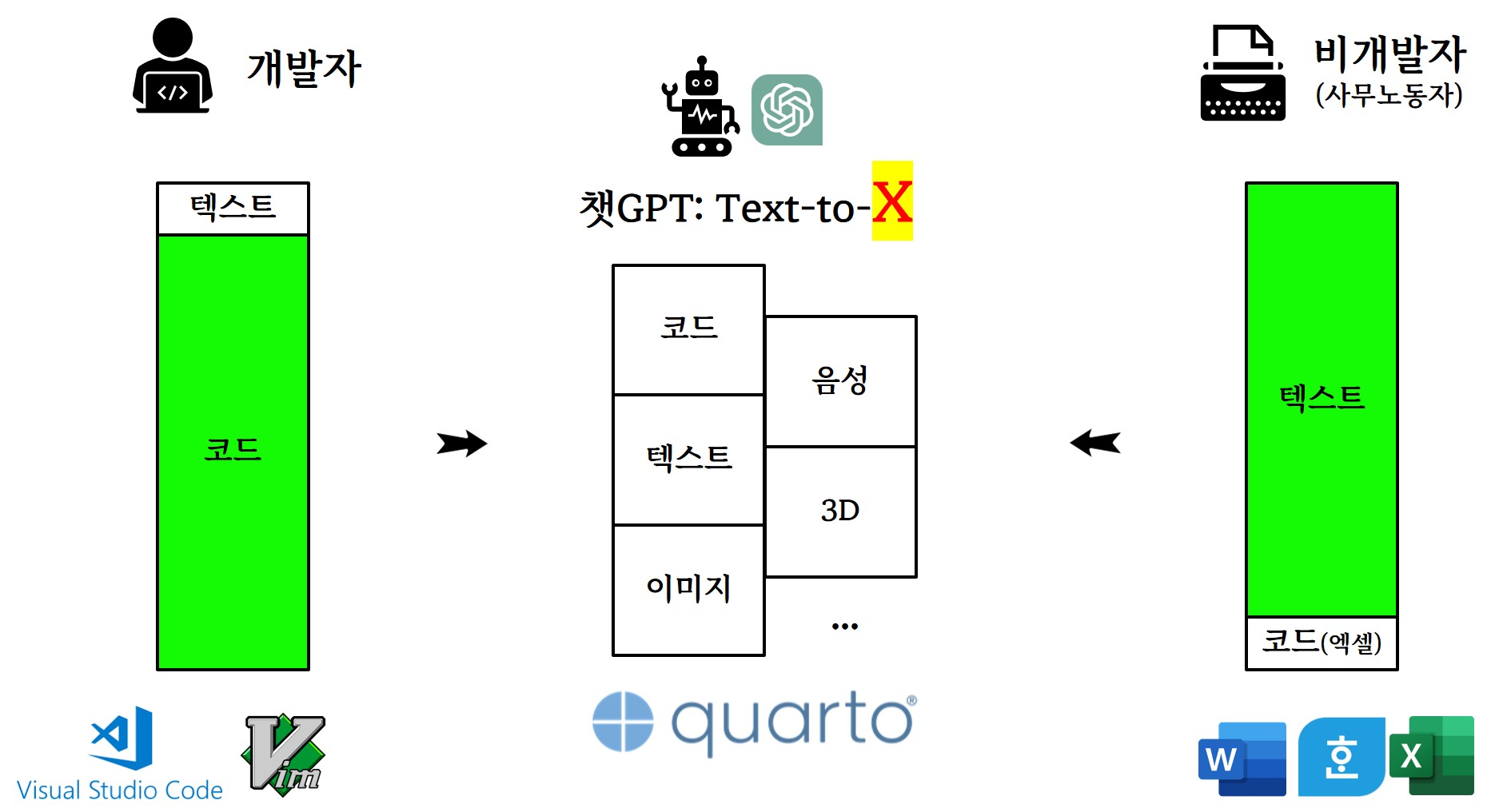
인터페이스 (Interface)




챗GPT NUI
- 챗GPT (ChatGPT)

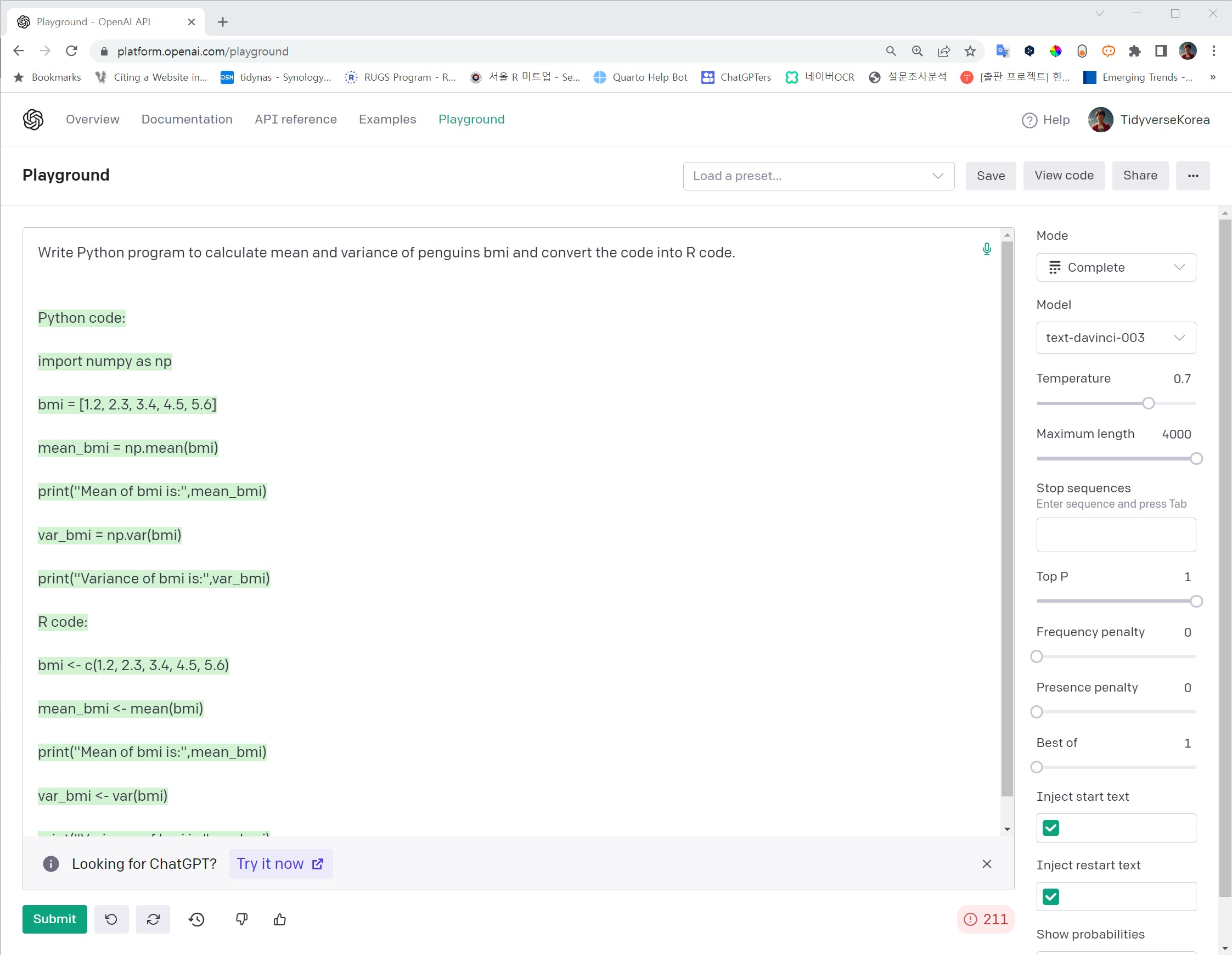
- OpenAI Playground
- GitHub Copilot



Command Palette 역사
- 60년대로 거슬러 올라가는 명령 팔레트는 최근 기술 업계에서 다시 인기를 얻고 있으며 사용자 중심 소프트웨어의 필수적인 부분으로 간주됨.
- CLI는 개인용 컴퓨터가 대중화되기 전 초기 컴퓨팅을 지배했으며 사용자가 시스템을 작동하기 위해 특정 명령을 알아야 했다. 1984년 Apple의 매킨토시와 함께 도입된 그래픽 사용자 인터페이스(GUI)는 중요한 혁신으로 여겨졌지만, 소프트웨어의 복잡성이 증가함에 따라 GUI만으로는 탐색하기가 점점 더 어려워졌다.
- 사용자가 항목 이름의 짧은 약어입력하여 앱과 파일을 검색할 수 있는 런처가 점점 더 보편화 되었다. 예를 들어 2001년에 출시된 Mac OS X용 LaunchBar, Quicksilver, 2005년에 출시된 Apple의 시스템 전체 Spotlight가 있다. 검색과 CLI의 결합은 Command Palette의 탄생으로 이어졌다.
- 오늘날 우리가 알고 있는 현대식 명령 팔레트는 2011년 Sublime Text 2 베타 Joe Skinner가 처음 소개. 명령줄 사용에 익숙한 프로그래머들이 단축키를 모두 외울 필요 없이 더 빠르게 작업할 수 있어 중요한 발전이 됨.
소프트웨어 3.0

Andrej Karpathy
- 소프트웨어 1.0: 코드 작성을 통한 프로그래밍
- 소프트웨어 2.0: 데이터셋 큐레이팅을 통한 프로그래밍
- 소프트웨어 3.0: 프롬프트 엔지니어링을 통한 프로그래밍 (LLM에 입력으로 제공, GPT 스타일)
프롬프트 공학



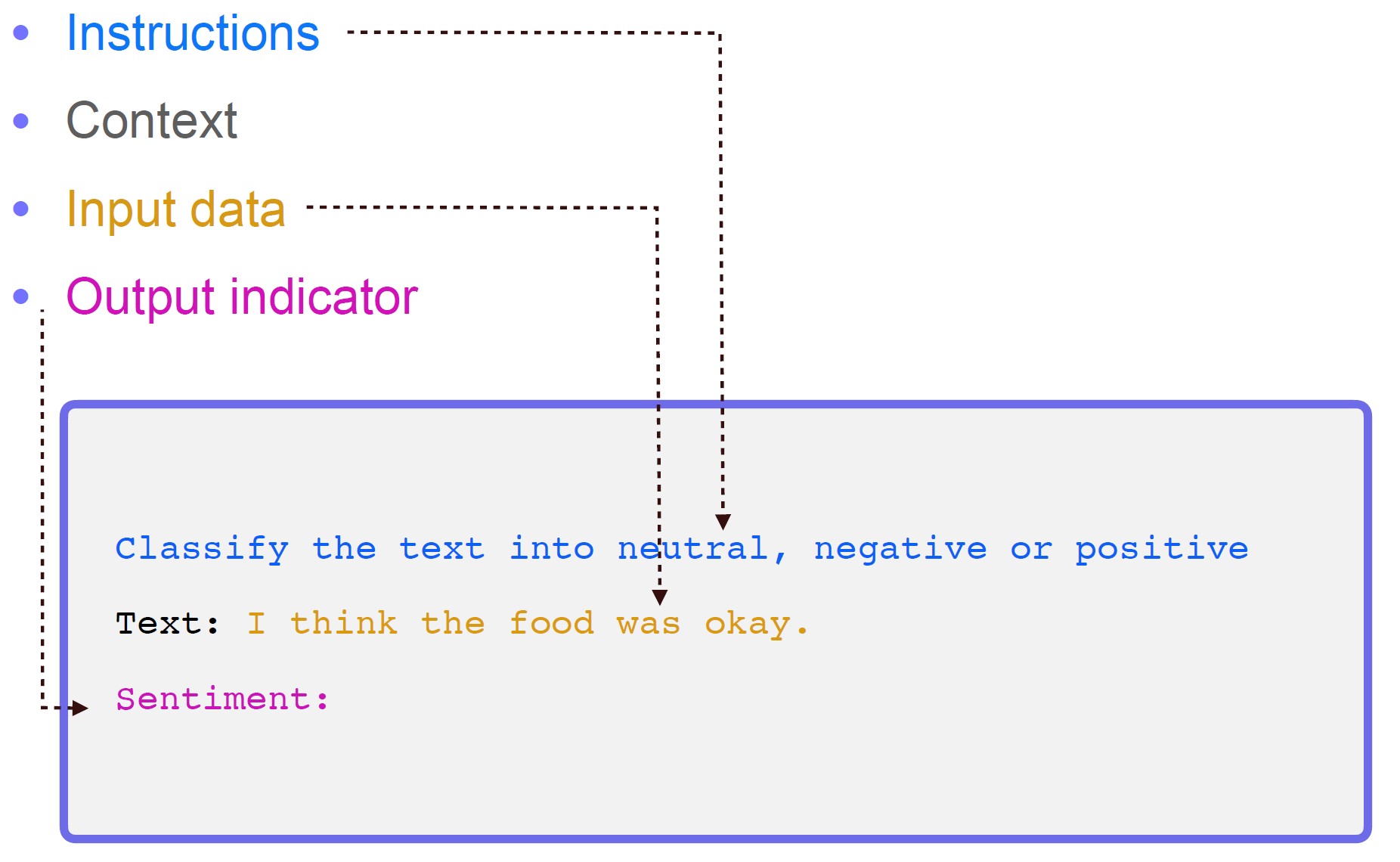
배경 - 프롬프트 엔지니어링


프롬프트 엔지니어링 (Context Stuffing)
보안사고
삼성전자
삼성전자 DS 부문 임직원 A씨는 반도체 설비 계측 데이터베이스(DB) 다운로드 프로그램의 소스 코드를 실행 중 오류를 확인했다. 문제가 된 소스 코드 전부를 복사해 챗GPT에 입력, 해결 방법을 문의했다. 삼성전자 설비 계측과 관련한 소스 코드가 오픈AI 학습 데이터로 입력된 셈이다.
임직원 B씨는 수율·불량 설비 파악을 위해 작성한 프로그램 코드를 챗GPT에 입력하는 사고를 냈다. 관련 소스 전체를 챗GPT에 입력하고 코드 최적화를 요청했다. 임직원 C씨는 스마트폰으로 녹음한 회의 내용을 네이버 클로바 애플리케이션(앱)을 통해 문서 파일로 변환한 뒤 챗GPT에 입력했다. 회의록 작성 요청이 목적이다.
이탈리아
로이터 통신 등에 따르면 이탈리아 데이터 보호청은 “챗GPT가 이탈리아의 개인정보 보호 기준과 규정을 충족할 때까지 서비스 접속을 일시적으로 차단할 것”이라고 밝혔다.
접속 차단 이유는 개인정보 침해 우려 때문이다. 이탈리아 당국은 챗GPT가 알고리즘 학습을 이유로, 개인정보를 대량으로 수집하고 저장하는 행위를 정당화할 법적 근거가 없다고 지적했다. 보호청은 챗GPT 개발사 오픈AI가 20일 이내에 해결책을 내놓지 않으면 전 세계 매출액의 최대 4%에 달하는 벌금을 물게 될 것이라고 경고하기도 했다.
보안 vs 효율 을 높고 많은 공공기관을 비롯한 기업들이 고민을 하고 있다. 거대언어모형(LLM)에 기반하여 모든 것을 자체 개발하면 상관이 없으나 현실적으로 GPT-3/3.5/4 모형을 갖춘 조직이 전무하지만, 이미 대다수의 사람이 오픈AI 챗GPT를 맛보았기 때문에 생산성 향상을 그냥 두고 넘어가기도 어려운 상황이다. 이런 점에서 챗GPT 제한적 사용이 현재시점(’23년 3월) 최선으로 보이며 점차 오픈소스 거대언어모형(LLM)과 전략적 제휴를 통한 챗GPT 사용이 중장기적 추진방향으로 자리 잡고 있다.

스프레드쉬트
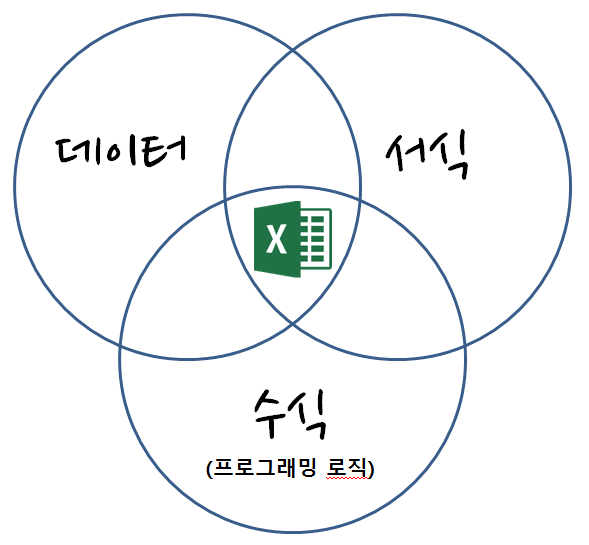
참고문헌
"ChatGPT활용연구TFT. (2023). [업무활용편] ChatGPT 활용사례 및 활용 팁. 서울디지털재단. https://sdf.seoul.kr/research-report/2003
ChatGPT활용연구TFT. (2023). [일상생활·창작활동·교육분야편] ChatGPT 활용사례 및 팁. 서울디지털재단. https://sdf.seoul.kr/research-report/2059
Skrabut, S. (2023). 80 Ways to Use ChatGPT in the Classroom: Using AI to Enhance. Stan Skrabut.