flowchart LR
A["🏗️ 프로젝트 시작<br/>연구 환경 준비"] --> B["📁 mkdir<br/>디렉토리 생성"]
B --> C["📝 touch/nano<br/>파일 생성"]
C --> D["🔄 mv<br/>파일 이동 & 이름변경"]
D --> E["💾 cp<br/>파일 복사 & 백업"]
E --> F["🗑️ rm<br/>안전한 파일 정리"]
F --> G["🎯 와일드카드<br/>*,?,[] 패턴 매칭"]
G --> H["🚀 대량 파일 처리<br/>1,520개 NENE 데이터"]
I["🤖 AI 도구 통합<br/>Claude Code, Gemini"] -.-> B
I -.-> C
I -.-> D
I -.-> E
I -.-> G
style A fill:#e1f5fe,stroke:#01579b,stroke-width:2px
style B fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
style C fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
style D fill:#f3e5f5,stroke:#7b1fa2,stroke-width:2px
style E fill:#e0f2f1,stroke:#00695c,stroke-width:2px
style F fill:#ffebee,stroke:#c62828,stroke-width:2px
style G fill:#f9fbe7,stroke:#827717,stroke-width:2px
style H fill:#e8eaf6,stroke:#303f9f,stroke-width:2px
style I fill:#fce4ec,stroke:#ad1457,stroke-width:2px
3 파일과 디렉토리 작업
앞서 Nelle 박사는 파일 시스템을 탐색하고 디렉토리 내용을 살펴보는 법을 마스터했다. 이제 연구 프로젝트를 본격적으로 시작하기 위해 더 능동적인 파일 관리 기법을 배울 차례다. 현대의 연구 환경에서는 전통적인 Unix 명령어와 AI 도구를 결합하여 더욱 효율적으로 작업할 수 있다.
이 장에서는 연구 환경을 체계적으로 구성하는 방법을 다룬다. Nelle 박사가 북태평양 환류 연구를 위한 프로젝트 구조를 설계하고, 1,520개의 데이터 파일을 체계적으로 관리하는 과정을 따라가며 실용적인 파일 관리 능력을 기른다. 전통적인 방법과 AI 도구를 활용한 현대적 방법을 모두 학습하여, 상황에 따라 가장 효율적인 방법을 선택할 수 있게 된다.
먼저 작업 환경을 준비해보자. 바탕화면의 shell-lesson-data 디렉토리로 이동하여 현재 위치를 확인한다.
$ pwd
/Users/nelle/Desktop/shell-lesson-data현재 디렉토리의 내용을 살펴본 다음, 연습용 데이터가 들어있는 exercise-data/writing 디렉토리로 이동하자. 여기가 바로 Nelle 박사가 새로운 파일과 디렉토리를 만들어 연구 프로젝트를 정리할 작업 공간이다.
$ cd exercise-data/writing/
$ ls -F
haiku.txt LittleWomen.txt3.1 프로젝트 디렉토리 생성
Nelle 박사가 박사학위 논문을 작성하기 위한 전용 디렉토리를 만들어보자. mkdir 명령어를 사용하여 thesis 디렉토리를 생성한다. 성공적으로 실행되면 아무 메시지도 출력되지 않는다.
$ mkdir thesismkdir은 “make directory”의 약자로, 말 그대로 디렉토리를 생성하는 명령어다. Nelle 박사가 사용한 thesis는 상대 경로이다(앞에 /가 없음). 따라서 새로운 디렉토리는 현재 작업 디렉토리 바로 아래에 생성된다.
$ ls -F
haiku.txt LittleWomen.txt thesis/방금 만들어진 thesis 디렉토리는 아무것도 없다.
$ ls -F thesisNelle 박사가 연구 프로젝트를 진행하다 보니, 데이터와 결과를 체계적으로 정리할 필요가 생겼다. mkdir은 한 번에 하나의 디렉토리만 만들 수 있지만, -p 옵션을 사용하면 여러 단계의 디렉토리를 한 번에 생성할 수 있다:
힌트🤖 AI로 더 스마트하게
복잡한 프로젝트 구조를 만들 때 AI 도구를 활용하면 더 효율적이다.
# Claude Code로 데이터 과학 프로젝트 구조 생성
$ claude "북태평양 환류 연구를 위한 표준 데이터 과학 프로젝트 구조를 만들어줘"
# AI가 자동으로 다음과 같은 구조 생성:
# project/
# ├── data/
# │ ├── raw/
# │ ├── processed/
# │ └── external/
# ├── notebooks/
# ├── src/
# ├── reports/
# └── README.md$ mkdir -p ../project/data ../project/results이제 ls -R 옵션을 사용해서 방금 만든 디렉토리 구조를 재귀적으로 확인해보자. -R 옵션은 모든 하위 디렉토리의 내용을 표시해준다:
$ ls -FR ../project
data/ results/
../project/data:
../project/results:
노트동일한 작업을 수행하는 두가지 방법
쉘을 사용해서 디렉토리를 생성하는 것이나 (윈도우) 파일 탐색기를 사용하는 것과 별반 차이가 없다. 운영체제 그래픽 파일 탐색기를 사용해서 현재 디렉토리를 열게 되면, thesis 디렉토리가 마찬가지로 나타난다. 파일과 상호작용하는 두가지 다른 방식이 존재하지만, 파일과 디렉토리는 동일하다.
노트파일과 디렉토리를 위한 좋은 명칭
연구 프로젝트를 체계적으로 관리하려면 파일과 디렉토리의 이름을 신중하게 지어야 한다. 부적절한 이름은 명령줄에서 작업할 때 많은 문제를 일으킬 수 있다. 다음은 파일 명명에 대한 실무적인 가이드라인이다.
공백(whitespaces)을 사용하지 않는다. 공백은 이름을 의미있게 할 수도 있지만, 공백이 명령라인 인터페이스에서 인자를 구별하는데 사용되기에, 파일과 디렉토리 명에서는 피하는 것이 상책이다. 공백 대신에
-혹은_문자를 사용한 다. (예를 들어,north pacific gyre/대신north-pacific-gyre/을 사용))대쉬(
-)로 명칭을 시작하지 않는다. 명령어가-으로 시작되는 명칭을 선택옵션으로 처리하기 때문이다.명칭에 문자, 숫자,
.(마침표),-(대쉬),_(밑줄)을 고수한다.
명령라인 인터페이스에서 그외 다른 많은 문자는 특별한 의미를 갖는다. 일부 특수 문자가 잘못 사용되면 명령어가 기대했던 대로 동작하지 못하게 하거나, 심한 경우 데이터 유실을 야기할 수도 있다.
공백을 포함하거나 알파벳이 아닌 문자를 갖는 파일명이나 디렉토리명을 굳이 지정할 필요가 있다면, 인용부호("")로 파일명이나 디렉토리명을 감싸야 한다.
3.2 텍스트 파일 생성
cd 명령어를 사용하여 thesis로 작업 디렉토리를 변경하자. Nano 텍스트 편집기를 실행해서 draft.txt 파일을 생성하자:
$ cd thesis
$ nano draft.txt
노트왜 편집기가 필요할까?
연구 작업에서 파일 생성과 편집은 핵심적인 작업이다. 데이터 분석 스크립트, 연구 노트, 설정 파일 등을 작성하기 위해서는 텍스트 편집기가 절대 필요하다.
텍스트 편집기 는 순수한 문자 데이터만을 다루는 도구다. 표, 이미지, 서식 등은 포함할 수 없지만, 코드, 데이터 파일, 설정 파일 등 연구에 필수적인 대부분의 파일을 수정할 수 있다.
연구자가 선택할 수 있는 편집기는 다양하다. 초보자라면 nano나 VS Code와 같은 직관적인 편집기부터 시작하는 것이 좋다. nano는 별도의 학습 없이도 바로 사용할 수 있으며, VS Code는 그래픽 인터페이스로 사용자 친화적이면서도 다양한 확장 기능을 제공한다.
더 전문적인 작업을 원한다면 Vim이나 Emacs를 고려해볼 만하다. Vim은 강력한 텍스트 조작 기능을 제공하며, 일단 마스터하고 나면 엄청나게 빠른 작업이 가능하다. Emacs는 확장성이 뛰어나고 사용자에 따라 세세한 상세설정이 가능하다.
현대에 들어서는 AI 기능이 통합된 편집기들이 주목받고 있다. Cursor는 AI 기능이 내장된 현대적인 편집기이고, VS Code에 GitHub Copilot을 설치하면 AI 코드 자동 완성 기능을 누릴 수 있다. 데이터 과학 연구자라면 Posit(구 RStudio) Positron, JetBrains의 PyCharm 같은 전용 IDE도 고려해볼 만하다.
운영체제에 따라서도 선택의 폭이 달라진다. macOS나 Linux 사용자라면 VS Code, Vim, Emacs 모두 우수하게 동작하며, nano는 기본적으로 설치되어 있다. Windows 사용자라면 VS Code나 Notepad++를 추천하며, PowerShell에서는 nano도 사용할 수 있다.
어떤 편집기를 선택하든 3가지 핵심 기능은 숙지해야 한다. 파일을 열고 저장하는 기능은 기본 중의 기본이고, 대량의 텍스트를 다룰 때는 검색과 바꾸기 기능이 필수적이다. 코드를 작성한다면 구문 하이라이팅 기능이 많은 도움이 된다.
힌트🤖 AI 편집기 혁신
Claude Code와 같은 AI 도구는 편집기의 개념을 바꾸고 있다.
# 자연어로 코드 작성 요청
$ claude "데이터를 CSV로 읽어서 기본 통계 계산하는 파이썬 스크립트 작성"
# AI가 이해하고 실행 가능한 코드 생성Nelle 박사가 논문 아이디어를 적기 위해 그림 3.2 처럼 텍스트 몇 줄을 입력해보자.
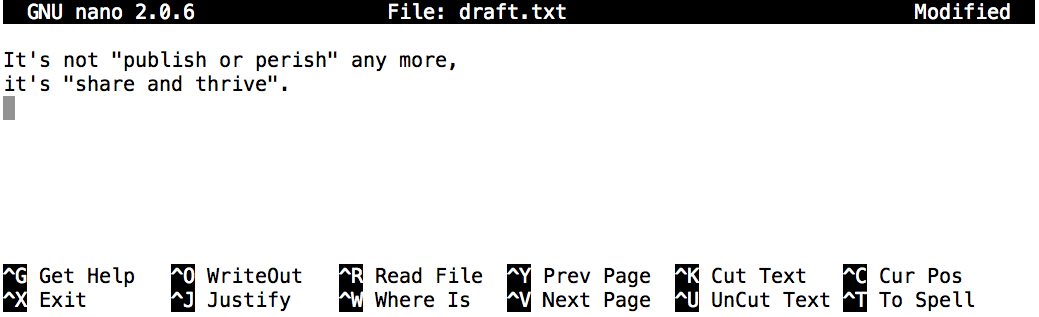
타이핑한 텍스트가 만족스럽다면, 컨트롤+O (Control-O)를 눌러서 데이터를 디스크에 저장한다. 저장하고자 하는 파일명을 입력하도록 독촉받게 되면 기본값인 draft.txt를 받아들이고 엔터키를 친다.
파일이 저장되면 컨트롤+X (Ctrl-X)를 사용하여 편집기를 끝내고 쉘로 돌아간다.
노트Control, Ctrl, ^ Key
컨트롤 키를 줄여서 “Ctrl” 키라고도 부른다. 컨트롤 키를 기술하는 몇가지 방식이 있다. 예를 들어, “컨트롤 키를 누르면서 X 키를 친다”라는 표현은 Control-X, Control+X, Ctrl-X, Ctrl+X, ^X, C-x 등으로 기술된다.
nano 편집기에서 화면 하단에 ^G Get Help ^O WriteOut를 볼 수 있다. Control-G를 눌러 도움말을 얻고, Control-O를 눌러 파일을 저장한다는 의미다.
nano는 화면에 아무 출력도 보여주지 않고 끝나지만, ls 명령어로 draft.txt 파일이 생성된 것을 확인할 수 있다.
$ ls
draft.txt텍스트 편집기를 사용하지 않고도 빈 파일을 생성할 수 있다. touch 명령어는 크기가 0인 빈 파일을 즉시 생성한다.
힌트🤖 AI와 함께 템플릿 생성
# Gemini CLI로 연구 노트 템플릿 생성
$ gemini "연구 일지 마크다운 템플릿 만들어줘" > research_log_template.md
# Claude Code로 여러 파일 한 번에 생성
$ claude "2024년 1월부터 12월까지 월별 보고서 파일 생성"
# 자동으로 report_2024_01.md ~ report_2024_12.md 생성$ cd # 홈 디렉토리로 이동하기
$ touch draft_backup.txt
$ ls -l draft_backup.txt
-rw-r--r--@ 1 rstudio staff 0 8 9 18:03 draft_backup.txttouch 명령어로 생성된 파일은 완전히 비어있으며 크기가 0바이트이다. 이러한 빈 파일 생성 방식은 몇 가지 상황에서 매우 유용하다.
- 프로그램 요구사항: 일부 프로그램은 실행 전에 출력 파일이 미리 존재해야 한다
- 스크립트 초기화: 데이터 처리 파이프라인에서 결과 파일을 미리 생성해둘 때
- 빠른 파일 생성: 내용은 나중에 추가하고 우선 파일 구조만 만들 때
ls -l 명령어로 파일을 확인하면 파일 크기가 0임을 확인할 수 있다. GUI 파일 탐색기로도 새로 생성된 파일을 볼 수 있다.
나중에 혼동을 피하려면 진도를 더 나가기 전에 방금 만든 파일을 제거하는 것이 좋다. 그렇지 않으면 향후 실행결과와 다를 수 있다. 이를 위해서 다음 명령을 실행한다.
$ rm draft_backup.txt
노트파일 확장자 중요성
지금까지 만든 파일들이 모두 “파일명.확장자” 형태인 것을 눈치챘을 것이다. 예를 들어 draft.txt, research_log_template.md 같은 식이다.
파일 확장자(filename extension)는 점(.) 이후의 부분으로, 파일에 담긴 데이터의 종류를 나타낸다.
.txt: 일반 텍스트 파일.md: 마크다운 문서
.pdf: PDF 문서.png: PNG 이미지.csv: CSV 데이터 파일
확장자는 단순한 관례처럼 보이지만 실제로는 매우 중요하다. 파일 자체는 바이트 정보일 뿐이며, 그 바이트를 어떻게 해석할지는 확장자를 통해 결정된다. 고래 이미지 파일의 이름을 whale.mp3로 바꾼다고 해서 음성 파일이 되는 것은 아니다. 하지만 운영체제는 확장자를 보고 음악 재생기로 열려고 시도할 것이다.
3.3 파일 정리와 이름 변경
연구 데이터가 쌓이면서 파일들을 체계적으로 정리해야 할 필요가 생긴다. Nelle 박사도 draft.txt라는 이름이 너무 일반적이라 생각하여 더 구체적인 이름으로 변경하기로 했다. 먼저 작업 디렉토리로 돌아가자.
$ cd ~/Desktop/shell-lesson-data/exercise-data/writingmv 명령어는 “move”의 줄임말로, 파일 이동과 이름 변경 모두에 사용된다. 기본 문법은 mv 원본 목적지이다.
$ mv thesis/draft.txt thesis/quotes.txt
$ ls thesis
quotes.txt파일 이름이 성공적으로 변경되었다. 이제 이 파일을 현재 작업 디렉토리로 이동해보자. 목적지에 디렉토리 이름을 지정하면 파일명은 유지된 채 위치만 바뀐다.
$ mv thesis/quotes.txt .
$ ls thesis # thesis 디렉토리는 이제 비어있음
$ ls quotes.txt # 파일이 현재 디렉토리로 이동됨
quotes.txt주의사항: mv 명령어는 목적지에 같은 이름의 파일이 있으면 경고 없이 덮어쓴다. 안전하게 사용하려면 -i 옵션을 사용하여 덮어쓰기 전에 확인을 받자.
$ mv -i old_file.txt new_file.txt # 덮어쓰기 전 사용자 확인mv 명령어는 파일뿐만 아니라 디렉토리에도 동일하게 작동한다.
힌트🤖 AI로 대량 파일 이동 자동화
대량의 파일을 체계적으로 이동해야 할 때 AI 도구가 큰 도움이 된다.
# Claude Code로 파일 분류 및 이동
$ claude "2024*.csv 파일을 월별 폴더로 분류해서 이동해줘"
# AI가 자동으로 월별 폴더 생성 및 파일 이동 스크립트 실행
# Gemini CLI로 파일명 패턴 분석 후 자동 정리
$ gemini "experiment_*.dat 파일들을 날짜와 실험 타입별로 정리"Nelle 박사가 해양 생태계 연구를 진행하던 중 데이터 정리에서 문제를 발견했다. 당분 분석 실험 데이터를 확인하던 중 일부 원시 데이터가 실수로 분석 완료 디렉토리에 저장되어 있었다.
$ ls -F
analyzed/ raw/
$ ls -F analyzed
fructose.dat glucose.dat maltose.dat sucrose.datmaltose.dat과 sucrose.dat은 아직 분석되지 않은 원시 데이터이므로 raw 디렉토리로 이동해야 한다. raw 디렉토리로 이동한 후 상대 경로를 사용하여 파일들을 가져오자.
$ cd raw/
$ mv ../analyzed/sucrose.dat ../analyzed/maltose.dat .이 명령어에서 ../analyzed/는 현재 디렉토리(raw)의 상위 디렉토리에 있는 analyzed 폴더를 의미하고, 마지막 .은 현재 디렉토리로 파일을 이동하라는 뜻이다. 이렇게 하면 원시 데이터가 올바른 위치에 배치되어 연구 워크플로우를 정상적으로 진행할 수 있다.
힌트🤖 AI 파일 분류 자동화
# 잘못된 위치에 있는 파일들을 AI가 자동 탐지
$ claude "이 프로젝트의 파일 구조를 분석해서 잘못된 위치에 있는 파일들을 찾아줘"3.4 파일 복사와 백업
연구를 진행하다 보면 중요한 파일을 안전하게 보관해야 할 필요가 생긴다. Nelle 박사도 논문 초안을 백업하기로 했다. cp 명령어는 mv와 문법이 같지만 원본 파일을 그대로 두고 복사본을 만든다는 점이 다르다.
$ cp quotes.txt quotes_backup.txt
$ ls
quotes.txt quotes_backup.txtmv 명령어와 달리 원본 파일(quotes.txt)이 그대로 남아 있고, 복사본(quotes_backup.txt)이 새로 생성되었다. 이제 더 안전한 위치에 백업본을 저장해보자.
$ cp quotes.txt thesis/quotations.txt
$ ls thesis/
quotations.txt3.4.1 디렉토리 전체 백업하기
개별 파일뿐만 아니라 디렉토리 전체를 복사할 수도 있다. 이때는 -r(recursive) 옵션을 사용한다.
$ cp -r thesis thesis_backup
$ ls thesis thesis_backup
thesis:
quotations.txt
thesis_backup:
quotations.txt-r 옵션 없이 디렉토리를 복사하려고 하면 오류가 발생한다. 이유는 디렉토리 내부에 파일이 존재하기 때문이다.
$ cp thesis thesis_backup
cp: -r not specified; omitting directory 'thesis'3.4.2 연구 데이터 체계적 백업
Nelle 박사가 해양 생태계 연구 데이터를 분석하기 전에 안전한 백업 전략을 수립했다. 원본 데이터를 분석용 디렉토리로 복사하고, 별도 위치에 보안 백업을 만드는 방식이다.
$ ls
north-pacific-gyre/
$ cp -r north-pacific-gyre/ analysis-workspace/
$ cp -r north-pacific-gyre/ ../backup/pacific-data-$(date +%Y%m%d)/여기서 $(date +%Y%m%d)는 현재 날짜를 YYYYMMDD 형식으로 자동 생성하는 명령어다. 예를 들어 2024년 8월 9일에 실행하면 pacific-data-20240809라는 이름의 백업 폴더가 만들어진다. 이렇게 하면 날짜별로 구분된 백업을 자동으로 생성할 수 있어 매우 편리하다.
이렇게 하면 분석 작업 중 실수로 데이터가 손상되더라도 안전하게 복구할 수 있다.
힌트🤖 AI 스마트 백업 전략
현대적인 연구 환경에서는 AI 도구를 활용하여 백업을 자동화할 수 있다.
# Claude Code로 백업 스크립트 자동 생성
$ claude "날짜별 백업 디렉토리를 만들고 프로젝트 파일들을 타입별로 분류해서 백업하는 스크립트 작성해줘"
# Gemini CLI로 백업 상태 점검
$ gemini "현재 디렉토리의 백업 상태를 분석하고 누락된 백업이 있는지 확인해줘"AI 도구는 파일 중요도를 분석하고, 백업 주기를 제안하며, 자동화된 백업 전략을 구성해줄 수 있다.
3.5 안전한 파일 정리
연구 프로젝트를 진행하다 보면 임시 파일, 중간 결과물, 테스트 파일 등 정리가 필요한 파일들이 쌓인다. Nelle 박사도 논문 작업을 마치면서 불필요한 파일들을 정리하기로 했다. rm 명령어는 “remove”의 줄임말로 파일을 삭제할 때 사용한다.
3.5.1 안전한 파일 삭제 절차
먼저 어떤 파일들이 있는지 확인해보자.
$ ls -la
-rw-r--r-- 1 nelle staff 1234 Aug 9 10:30 quotes_backup.txt
-rw-r--r-- 1 nelle staff 1234 Aug 9 09:15 quotes.txt
-rw-r--r-- 1 nelle staff 100 Aug 8 14:20 temp_notes.txt임시 메모 파일인 temp_notes.txt를 삭제해보자. 안전을 위해 -i 옵션을 사용하여 대화형으로 삭제한다.
$ rm -i temp_notes.txt
rm: remove regular file 'temp_notes.txt'? y
$ ls
quotes_backup.txt quotes.txt-i 옵션은 삭제 전에 확인을 요청한다. y를 입력하면 삭제되고, n을 입력하면 취소된다.
노트삭제는 영원하다
Unix 명령줄에는 삭제된 파일을 복구할 수 있는 휴지통이 없다. (하지만 대부분의 그래픽 인터페이스는 휴지통 기능이 있다) 파일을 삭제하면 파일시스템의 관리대상에서 제외되고 디스크 저장공간이 다시 재사용된다.
삭제된 파일을 찾아 되살리는 도구가 존재하지만, 어느 상황에서나 동작한다는 보장은 없다. 왜냐하면 파일이 저장되었던 공간을 컴퓨터가 바로 재사용할지 모르기 때문이다.
3.5.2 여러 파일 동시 정리
패턴을 사용하여 여러 임시 파일을 한 번에 정리할 수도 있다.
$ ls
analysis_v1.txt analysis_v2.txt analysis_final.txt temp1.log temp2.log
$ rm -i temp*.log
rm: remove regular file 'temp1.log'? y
rm: remove regular file 'temp2.log'? y
$ ls
analysis_v1.txt analysis_v2.txt analysis_final.txt3.5.3 디렉토리 정리
빈 디렉토리는 rmdir 명령어로, 내용이 있는 디렉토리는 rm -r 옵션으로 삭제할 수 있다.
$ ls -F
old_drafts/ thesis_backup/
$ rm -r -i old_drafts/
rm: descend into directory 'old_drafts/'? y
rm: remove regular file 'old_drafts/draft_v1.txt'? y
rm: remove directory 'old_drafts/'? y-r 옵션은 디렉토리와 그 내용을 재귀적으로 삭제한다. -i 옵션과 함께 사용하면 각 단계마다 확인할 수 있어 안전하다.
힌트현대적 파일 관리 전략: 삭제 전 안전장치
Unix 명령줄에는 휴지통이 없지만, 다음과 같은 안전장치를 활용할 수 있다.
Git을 활용한 버전 관리
$ git add .
$ git commit -m "Before cleanup"
$ rm old_files.txt # Git 히스토리에 남음백업과 연계한 안전 삭제
$ cp important_file.txt ../backup/
$ rm important_file.txt # 백업 후 안전하게 삭제AI 도구로 정리 대상 식별
$ claude "현재 디렉토리에서 안전하게 삭제할 수 있는 임시 파일들을 찾아줘"
$ gemini "프로젝트 정리를 위한 파일 삭제 체크리스트 만들어줘"
경고⚠️ 주의사항
- 삭제된 파일은 복구가 어렵다. 중요한 파일은 반드시 백업 후 삭제하자.
rm -r은 매우 강력한 명령어이므로 신중하게 사용해야 한다.- 실수를 방지하려면 항상
-i옵션을 사용하는 습관을 기르자.
3.6 와일드카드와 패턴 매칭
Nelle 박사가 북태평양 환류 연구에서 수집한 1,520개의 데이터 파일을 효율적으로 관리해야 한다. 하나씩 처리하기엔 너무 많은 파일이므로 와일드카드(wildcards)를 활용한 패턴 매칭이 필요하다. 와일드카드는 특정 패턴에 맞는 여러 파일을 한 번에 선택할 수 있는 특수 문자다.
3.6.1 와일드카드 기본 개념
북태평양 데이터 디렉토리로 이동해서 파일들을 살펴보자.
$ cd north-pacific-gyre/2012-07-03/
$ ls
NENE01729A.txt NENE01729B.txt NENE01736A.txt NENE01751A.txt NENE01751B.txt
NENE01812A.txt NENE01843A.txt NENE01843B.txt NENE01978A.txt NENE01978B.txt
NENE02018B.txt NENE02040A.txt NENE02040B.txt NENE02040Z.txt NENE02043A.txt
goostats goodiff모든 데이터 파일이 NENE으로 시작하고 .txt로 끝나는 패턴을 가지고 있다. 와일드카드를 사용하면 이런 패턴을 활용할 수 있다.
노트🎯 와일드카드 기본 문법
주요 와일드카드
*: 0개 이상의 임의 문자 (가장 자주 사용)?: 정확히 1개의 임의 문자
[...]: 괄호 안의 문자 중 하나[!...]: 괄호 안의 문자가 아닌 문자
사용 예시
*.txt: 모든 텍스트 파일NENE*A.txt: NENE로 시작하고 A로 끝나는 txt 파일NENE????A.txt: NENE + 4글자 + A.txt 패턴*[AB].txt: A 또는 B로 끝나는 txt 파일
3.6.2 패턴으로 파일 선택
모든 데이터 파일을 선택해보자.
$ ls NENE*.txt
NENE01729A.txt NENE01729B.txt NENE01736A.txt NENE01751A.txt NENE01751B.txt
NENE01812A.txt NENE01843A.txt NENE01843B.txt NENE01978A.txt NENE01978B.txt
NENE02018B.txt NENE02040A.txt NENE02040B.txt NENE02040Z.txt NENE02043A.txtNENE*.txt 패턴이 모든 데이터 파일을 선택했다. 이제 더 구체적인 패턴을 사용해보자.
$ ls NENE*A.txt
NENE01729A.txt NENE01736A.txt NENE01751A.txt NENE01812A.txt NENE01843A.txt NENE01978A.txt NENE02040A.txt NENE02043A.txtA 시리즈 파일만 선택되었다. 이제 이 파일들을 분석용 디렉토리로 복사해보자.
$ mkdir ../analysis
$ cp NENE*A.txt ../analysis/
$ ls ../analysis/
NENE01729A.txt NENE01736A.txt NENE01751A.txt NENE01812A.txt NENE01843A.txt NENE01978A.txt NENE02040A.txt NENE02043A.txt3.6.3 고급 패턴 매칭
더 정교한 선택도 가능하다. 특정 번호 범위의 파일들만 선택해보자.
$ ls NENE0174*
NENE01743A.txt NENE01751A.txt NENE01751B.txt
$ ls NENE????A.txt # 정확히 4자리 숫자 + A
NENE01729A.txt NENE01736A.txt NENE01751A.txt NENE01812A.txt NENE01843A.txt NENE01978A.txt NENE02040A.txt NENE02043A.txt문자 집합을 사용한 선택도 가능하다.
$ ls NENE*[AB].txt # A 또는 B로 끝나는 파일들
$ ls NENE*[!Z].txt # Z가 아닌 문자로 끝나는 파일들 (Z 파일 제외)3.6.4 대량 파일 처리 전략
연구 데이터를 타입별로 분류해보자. 여기서 새로운 패턴인 중괄호 확장(brace expansion)을 사용한다.
$ mkdir -p classified/{typeA,typeB,other}
$ cp NENE*A.txt classified/typeA/
$ cp NENE*B.txt classified/typeB/
$ cp NENE*Z.txt classified/other/{typeA,typeB,other} 패턴은 쉘이 자동으로 다음과 같이 확장한다.
$ mkdir -p classified/typeA classified/typeB classified/other이런 중괄호 확장은 여러 유사한 명령을 한 번에 실행할 때 매우 유용하다. 결과를 확인해보자.
$ ls classified/*/
classified/typeA/:
NENE01729A.txt NENE01736A.txt NENE01751A.txt NENE01812A.txt NENE01843A.txt NENE01978A.txt NENE02040A.txt NENE02043A.txt
classified/typeB/:
NENE01729B.txt NENE01751B.txt NENE01843B.txt NENE01978B.txt NENE02018B.txt NENE02040B.txt
classified/other/:
NENE02040Z.txt
힌트🤖 AI 스마트 패턴 분석
대량 파일 처리에서 AI 도구가 강력한 도움을 준다.
# Claude Code로 복잡한 파일 분류 자동화
$ claude "NENE 데이터 파일들을 날짜와 측정 타입별로 자동 분류하는 스크립트 만들어줘"
# Gemini CLI로 패턴 분석
$ gemini "현재 디렉토리 파일명 패턴을 분석해서 최적의 와일드카드 표현 제안해줘"
# 데이터 무결성 검증
$ claude "각 분류별로 예상 파일 개수와 실제 개수를 비교해서 누락 파일 찾아줘"AI는 복잡한 패턴을 자동으로 인식하고, 분류 규칙을 제안하며, 대량 처리 스크립트를 생성해준다.
3.7 직교 설계
Unix는 직교 설계(orthogonal design) 철학을 바탕으로 만들어졌다. 이는 1970년대 벨 연구소에서 개발된 설계 원칙으로, 각 도구가 한 가지 일을 매우 잘 하면서도 다른 도구와 완벽하게 조합될 수 있도록 설계되었다는 뜻이다.
이러한 철학의 핵심은 “작은 도구들의 조합으로 복잡한 작업을 해결한다”는 것이다. 마치 레고 블록처럼 각각의 명령어는 단순하지만, 이들을 조합하면 무한히 복잡하고 강력한 시스템을 만들 수 있다. 현대의 데이터 과학과 AI 워크플로우에서도 이 원칙은 여전히 강력한 위력을 발휘한다. 특히 Nelle 박사와 같은 연구자들이 수천 개의 데이터 파일을 처리할 때, 이런 도구 조합의 유연성은 필수적이다.
3.7.1 명령어 조합의 힘
지금까지 배운 기본 명령어들을 조합하면 훨씬 더 복잡하고 정교한 작업을 수행할 수 있다. 단순한 mkdir, cp, mv 명령어들이 find나 다른 도구들과 결합되면, 마치 전문 프로그래머가 작성한 것 같은 자동화 스크립트가 완성된다.
예를 들어, 연구 프로젝트에서 자주 발생하는 “오래된 임시 파일 정리” 작업을 생각해보자. 수동으로 하나씩 찾아 삭제하는 것은 비효율적이다. 하지만 여러 명령어를 조합하면 이런 작업을 자동화할 수 있다. 또한 대량의 실험 데이터를 날짜별, 타입별로 분류하는 작업도 명령어 조합으로 간단해진다.
# 7일 이상 된 임시 파일들 찾아서 삭제
$ find /tmp -name "*.tmp" -mtime +7 -exec rm {} \;
# 특정 패턴의 파일들을 날짜별로 분류
$ find . -name "NENE*.txt" -exec sh -c 'mkdir -p $(date -r "$1" +%Y-%m); cp "$1" $(date -r "$1" +%Y-%m)/' _ {} \;
# 파일 크기별로 정렬해서 큰 파일들만 보기
$ ls -la | grep -E '\.(txt|data)$' | sort -k5 -nr | head -103.7.2 고급 와일드카드 패턴
앞서 배운 기본 와일드카드(*, ?)를 넘어서서, 더욱 정교하고 강력한 패턴 매칭이 가능하다. 현대의 쉘들은 확장된 글로빙(extended globbing) 기능을 제공하여, 복잡한 파일 선택 작업을 한 번의 명령으로 처리할 수 있게 해준다.
특히 대규모 연구 데이터를 다룰 때, 이런 고급 패턴은 매우 유용하다. 예를 들어, 특정 실험 타입은 포함하되 백업 파일은 제외하거나, 여러 층의 디렉토리에서 특정 확장자 파일들만 선택하는 등의 복잡한 조건을 간단한 패턴으로 표현할 수 있다. 이는 Nelle 박사처럼 1,520개의 파일을 관리해야 하는 상황에서 특히 빛을 발한다.
# 중첩 패턴 사용
$ ls data/**/*.{txt,csv,json} # 모든 하위 디렉토리의 데이터 파일들
# 제외 패턴과 조합
$ cp !(backup|temp)/* processed/ # backup, temp 제외하고 모든 파일 복사
# 조건부 패턴
$ ls NENE*[0-9][0-9][0-9][0-9]* # 정확히 4자리 숫자가 포함된 파일들3.7.3 성능 최적화 팁
대량 파일 처리에서는 단순히 작업이 완료되는 것만으론 부족하다. 성능과 효율성을 고려한 접근법이 필요하다. 잘못된 방법으로 수천 개의 파일을 처리하면 몇 분이면 끝날 작업이 몇 시간이 걸릴 수도 있다.
핵심은 프로세스 생성 비용을 최소화하는 것이다. Unix에서는 새로운 프로세스를 생성할 때마다 상당한 시스템 리소스가 소모된다. 따라서 각 파일마다 새 프로세스를 실행하는 대신, 여러 파일을 한 번에 처리하는 배치 처리 방식을 사용하는 것이 훨씬 효율적이다. 또한 최신 멀티코어 시스템에서는 병렬 처리를 활용하여 처리 속도를 크게 향상시킬 수 있다.
# 비효율적: 각 파일마다 새 프로세스 생성
$ find . -name "*.txt" -exec wc -l {} \;
# \; 의미: 세미콜론(;)을 백슬래시(\)로 이스케이프 처리
# 쉘이 명령어 구분자로 해석하지 않도록 함
# 파일 100개 → wc 명령어 100번 실행 (매우 비효율적)
# 더 나은 방법: {} \+ 사용 (한 번에 여러 파일 처리)
$ find . -name "*.txt" -exec wc -l {} \+
# 파일 100개 → wc 명령어 1번 실행 (wc -l file1.txt file2.txt ...)
# 가장 효율적: xargs로 배치 처리
$ find . -name "*.txt" -print0 | xargs -0 wc -l
# print0과 -0: 파일명에 공백이 있어도 안전하게 처리
# 병렬 처리로 더욱 빠르게 (4개 프로세스 동시 실행)
$ find . -name "*.txt" -print0 | xargs -0 -P 4 wc -l
중요🔧 직교 설계 (Orthogonal Design)
Unix의 핵심 철학 중 하나인 직교적 설계는 각 도구가 독립적이면서도 완벽하게 조합 가능하도록 설계되었다는 뜻이다.
직교적 설계는 네 가지 핵심 원칙을 바탕으로 한다. 첫째, 단일 책임 원칙에 따라 각 도구는 한 가지 일만을 담당하되 그 일을 매우 잘 수행한다. 예를 들어 wc는 오직 단어나 줄을 세는 일만 하고, sort는 오직 정렬만 담당한다. 둘째, 조합 가능성 원칙으로 이런 단순한 도구들을 파이프나 리디렉션을 통해 자유롭게 연결할 수 있다.
셋째, 예측 가능성 원칙에 의해 모든 Unix 도구들은 일관된 인터페이스와 동작 방식을 따른다. 명령행 옵션 체계, 입력과 출력 방식, 에러 처리 등이 표준화되어 있어 새로운 도구를 배우기 쉽다. 마지막으로 확장 가능성 원칙으로 시스템에 새로운 도구를 추가하더라도 기존 도구들과 완벽하게 호환되며 조합할 수 있다.
# 각 도구의 역할이 명확하게 구분됨
$ find . -name "*.txt" # 파일 찾기만 담당
$ wc -l # 줄 수 세기만 담당
$ sort -nr # 숫자 역순 정렬만 담당
$ head -5 # 상위 5개만 보여주기 담당
# 조합하면 강력한 기능 완성
$ find . -name "*.txt" | xargs wc -l | sort -nr | head -5이런 설계 덕분에 무수히 많은 조합이 가능하며, 새로운 상황에 유연하게 대응할 수 있다.
힌트🤖 AI 고급 파일 관리 자동화
직교적 설계 원리와 AI 도구를 결합하면 복잡한 파일 관리 작업을 자동화할 수 있다.
스마트 명령어 생성
# 복잡한 find 명령어를 자연어로 요청
$ claude "7일 이전에 수정된 .log 파일들 중 1MB 이상인 것만 찾아서 압축해줘"
# 고급 정규식 패턴을 AI가 생성
$ gemini "YYYY-MM-DD_실험명_버전.txt 형태의 파일들을 날짜별로 분류하는 명령어"자동 스크립트 생성
# 파일 관리 워크플로우 자동화
$ claude "연구 데이터 백업 스크립트를 만들어줘:
- 매주 금요일 자동 실행
- 중요 파일만 선별적 백업
- 압축 후 클라우드 업로드
- 로그 기록 및 에러 알림"
# 성능 최적화된 대량 처리
$ ai-shell "10만개 이미지 파일을 해상도별로 분류하고 썸네일 생성하는 병렬 처리 스크립트"지능형 파일 분석
# 파일 구조 최적화 제안
$ claude "현재 프로젝트 구조를 분석해서 데이터 과학 표준에 맞게 재구성 방안 제시해줘"
# 중복 파일 및 용량 분석
$ gemini "디스크 사용량을 분석해서 정리가 필요한 디렉토리와 방법을 추천해줘"AI 도구는 복잡한 Unix 명령어 조합을 자동 생성하고, 최적화된 워크플로우를 제안하며, 반복 작업을 자동화해준다.
3.7.4 파이프라인으로의 발전
지금까지 배운 파일 관리 명령어들과 직교적 설계 원리는 다음 장에서 다룰 파이프와 리디렉션의 튼튼한 기반이 된다. 각 명령어가 독립적이면서도 서로 완벽하게 연결 가능하다는 특성 덕분에, 마치 공장의 생산 라인처럼 복잡한 데이터 처리 파이프라인을 구축할 수 있다.
이 장에서 배운 mkdir, cp, mv, rm 등의 명령어들이 파이프(|)와 리디렉션(>, >>)을 통해 연결되면, 단순한 파일 조작을 넘어서 진정한 데이터 처리 워크플로우가 완성된다. 예를 들어, 파일을 찾고, 개수를 세고, 결과를 파일에 저장하는 일련의 과정이 하나의 명령행으로 연결될 수 있다.
# 이번 장에서 배운 내용들이 파이프로 연결되는 예시
$ find . -name "NENE*.txt" | wc -l | tee file_count.txt
$ ls -la *.txt | grep -v backup | sort -k5 -nr > largest_files.txt다음 장에서는 이런 명령어 조합을 더욱 체계적이고 강력하게 만들어주는 파이프와 리디렉션을 자세히 살펴볼 것이다. 특히 Nelle 박사의 1,520개 데이터 파일을 효율적으로 분석하고 처리하는 실전 기법들을 배우게 될 것이다. 파일 생성과 관리는 시작일 뿐이고, 진짜 데이터 과학의 힘은 이런 파이프라인에서 나온다.