flowchart TB
subgraph A["사용자 인터페이스"]
direction LR
CLI["CLI 1950~<br>Command Line Interface<br> GUI 1970~<br> Graphic User Inferface"] --> WIMI
WIMI["Web Interface <br> 1994~ <br> Mobile Interface <br> 2007~"] --> NUI["LUI 2023~<br> Language <br> User Interface"]
end
classDef default fill:#f9f7f7,stroke:#333,stroke-width:2px;
classDef A font-size:16px;
9 챗GPT 데이터 과학
1950년대부터 본격적으로 컴퓨터가 도입되면서 CLI를 필두로 다양한 사용자 인터페이스(User Interface)가 적용되었다. 스티브 잡스의 애플사는 매킨토시 GUI에 이어 아이폰 모바일 인터페이스를 일반화시켰다면, 최근 챗GPT는 언어 사용자 인터페이스(LUI)를 통해 각 분야에 혁신을 예고하고 있다. 챗GPT 데이터 과학도 사용자 관점에서 보자. 기존 R, 파이썬, SQL, 엑셀 등 데이터 과학 구문을 머리속에 암기하고 있거나 구글이나 네이버를 통해 중요 키워드를 통해 문제를 해결해야 했었다. 하지만, 이제 챗GPT가 자연어를 이해하기 때문에 데이터 전처리, 통계 작업, 데이터 분석, 시각화, 모형개발 등 데이터 과학 전반에 변화는 필연적이다. [@wickham2023r] [@wickham2019welcome] [@gozalo2023chatgpt]
9.1 tidyverse
통계학은 데이터에서 정보를 압축하거나 최대한 많은 정보를 추출하는 노력에서 크게 발전해 왔다. 최근에는 기계학습과 딥러닝, 데이터 사이언스가 실무에 폭넓게 활용되면서 난제가 발생했다. R언어가 파이썬보다 먼저 맞이한 문제는 만개가 넘는 패키지가 개발되었지만, 각 패키지가 개별적인 설계 원칙에 따라 개발되고 여러 개발자에 의해 유지보수되어 초기 설계 원칙이 흔들리는 문제가 발생했다는 점이다. 이런 문제점을 인지한 데이터 과학자 중 해들리 위컴(Hadley Wickham)의 기여가 특히 돋보였다. 그는 R 언어를 활용해 정제되지 않은 데이터를 처리하는 과정에서 축적한 지식을 패키지 형태로 제작하여 공개하였고, 이런 패키지들의 모임을 통칭해서 hadlyverse, 나중에 tidyverse라고 부르게 되었다.
tidyverse는 install.packages() 명령어로 쉽게 설치한 후 library(tidyverse) 명령어로 작업에 바로 사용할 수 있다. tidyverse 패키지는 하나의 독립된 패키지로 구성되지 않고 각 역할을 독립적으로 수행하는 수많은 작은 패키지로 구성된 하나의 생태계를 구성하고 있다. 가장 최근에 날짜와 시간 데이터를 담당하는 lubridate 패키지가 추가되어 library(lubridate) 명령을 실행하지 않더라고 다양한 날짜 및 시간 관련 함수를 tidyverse에서 즉시 사용할 수 있게 되었다.
install.packages('tidyverse')
library(tidyverse)
── Attaching core tidyverse packages ────────────────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.1 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.2 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
✔ purrr 1.0.1
── Conflicts ──────────────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package to force all conflicts to become errors
Warning messages:
1: 패키지 ‘ggplot2’는 R 버전 4.2.3에서 작성되었습니다
2: 패키지 ‘tibble’는 R 버전 4.2.3에서 작성되었습니다
3: 패키지 ‘dplyr’는 R 버전 4.2.3에서 작성되었습니다 tidyverse는 깔끔한 데이터 과학 세상을 구현하기 위한 철학이다. 공교롭게도 tidyverse는 유닉스 철학, 즉 모듈 방식과 재사용성 개념을 적극 도입한 소프트웨어 개발 철학을 기반으로 한다. tidyverse는 깔끔한(tidy) API에 기반하며, 기존 자료구조를 재사용하고, 파이프 연산자를 통해 간단한 함수를 조합하며, 함수형 프로그래밍을 적극 사용하고, 기계가 아닌 인간을 위한 설계를 추구하는 원칙을 제시했을 뿐만 아니라 엉망진창(messy) 데이터에 대한 새로운 지평을 열었다.
tidyverse 핵심은 다양한 형태의 데이터를 가져와 사람과 기계가 소통할 수 있는 형태로 변환하는 과정을 추상화한 것이다. 이는 시각화와 모델링을 통해 통찰력을 향상시키고, 동시에 자동화와 확장성을 반영하는 체계적인 작업 흐름을 제공한다. 이러한 작업 흐름을 관통하는 핵심 개념은 ‘파이프’로, 이는 유닉스 파이프 연산자에서 검증된 개념이다. 이를 통해 tidyverse는 데이터 과학 작업을 효율적으로 진행할 수 있는 도구를 제공하며, 그 내재된 철학을 통해 데이터를 ’깔끔하게’ 처리하는 작업흐름(workflow)를 그림 fig-tidyverse 에서 제시하고 있다.
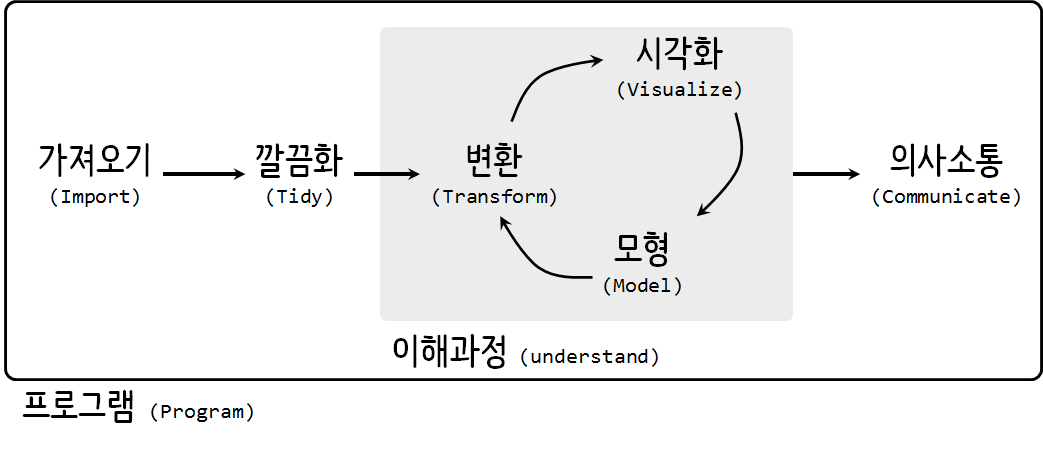
9.2 실습 데이터
palmerpenguins 패키지에 있는 penguins 데이터셋이 붓꽃(iris) 데이터셋을 대체하며 데이터 과학에서 많이 사용되고 있다. 챗GPT 데이터 과학 접근법을 보여주기 위해 먼저 palmerpenguins 패키지에 penguins 데이터셋을 펭귄 종별로 명칭을 달리하여 .csv 파일로 저장한다. 챗GPT 초창기 한국어를 영어로 번역해야 성능이 좋아졌으나 최근에는 한국어로 프롬프트를 작성해도 좋은 결과를 제시하고 있다.
파일 저장 프롬프트
“palmerpenguins 패키지 penguins 데이터셋을 각 종별로 나눠
.csv 파일로 저장하는 R 코드를 작성해 주세요. purrr 패키지 walk 함수를 사용해서
작성해주세요.”
GPT-4 모형엔진을 사용하면 다음에 저자가 직접 작성한 코드와 유사한 R 코드를 작성해준다. data/ 디렉토리 아래 penguin_adelie.csv, penguin_chinstrap.csv, data/penguin_gentoo.csv 파일 세개로 나눠진 것을 fs 패키지 dir_ls() 함수를 통해 확인된다.
# *. 패키지 --------------------------------------------------------------
library(palmerpenguins)
library(tidyverse)
# *. 데이터 나누기 --------------------------------------------------------------
species <- palmerpenguins::penguins %>%
count(species) %>%
pull(species) %>%
as.character(.)
save_species <- function(species_name = "Adelie") {
palmerpenguins::penguins %>%
filter(str_detect(species, species_name)) %>%
write_csv(glue::glue("data/penguin_{str_to_lower(species_name)}.csv"))
}
walk(species, save_species)
fs::dir_ls(path = "data/", glob="data/penguin_*.csv")
#> data/penguin_adelie.csv data/penguin_chinstrap.csv
#> data/penguin_gentoo.csv9.3 펭귄종별 개체수
펭귄 종별로 .csv 파일을 나눈 이유는 실제 현장에서 다양하게 쪼개진 데이터를 하나로 묶어 분석을 수행하는 경우가 많은 일일이 데이터를 열어 분석가가 직접 분석하는 것은 손이 많이 가고 경우에 따라서는 실수로 오류가 발생하기 때문에 이를 방지할 필요가 있다.
펭귄 종별 개체수 빈도수를 계산하는 유닉스 쉘 프로그램을 작성해보자.
첫번째 분석 프롬프트
“펭귄 종별로 구분된 palmer penguins csv 파일이 세개 data/ 폴더안에 있습니다.
각각의 파일명은 penguin_adelie.csv, penguin_chinstrap.csv, penguin_gentoo.csv 으로
종별 펭귄 개체수 빈도수를 계산하는 코드를 작성하세요.”
첫번째 분석 프롬프트를 작성하고 ShellGPT에 실행하면 다음과 같은 결과가 나온다. sgpt에서 제시한 유닉스 쉘 명령어를 해석하면 “이 쉘 명령은 세 개의 서로 다른 CSV 파일에서 펭귄 데이터를 읽고, 종 열을 추출하고, 고유 값을 정렬 및 계산한 후 결과를 출력합니다.”라는 취지로 작성된 것을 확인하고 이를 [E]xecute로 실행하면 기대했던 결과를 얻을 수 없음이 확인된다.
$ sgpt -s "펭귄 종별로 구분된 palmer penguins csv 파일이 세개 data/ 폴더안에 있습니다. \
> 각각의 파일명은 penguin_adelie.csv, penguin_chinstrap.csv, penguin_gentoo.csv 으로 \
> 종별 펭귄 개체수 빈도수를 계산하는 코드를 작성하세요."
cat data/penguin_adelie.csv | tail -n +2 | cut -d ',' -f 2 | sort | uniq -c
cat data/penguin_chinstrap.csv | tail -n +2 | cut -d ',' -f 2 | sort | uniq -c
cat data/penguin_gentoo.csv | tail -n +2 | cut -d ',' -f 2 | sort | uniq -c
[E]xecute, [D]escribe, [A]bort: D
This shell command reads penguin data from three different CSV files, extracts the species column, sorts and counts the unique values, and outputs the results.
[E]xecute, [D]escribe, [A]bort: E
44 Biscoe
56 Dream
52 Torgersen
68 Dream
124 Biscoe두번째 분석 프롬프트에서는 명확하게 펭귄종(species)이 위치한 칼럼을 특정하고 쉘 명령어를 작성하도록 지시하고 이를 바로 실행해보자.
두번째 분석 프롬프트
“펭귄 종별로 구분된 palmer penguins csv 파일이 세개 data/ 폴더안에 있습니다.
각각의 파일명은 penguin_adelie.csv, penguin_chinstrap.csv, penguin_gentoo.csv 으로
종은 species 첫번째 칼럼에 위치하고, 종별 펭귄 개체수 빈도수를 계산하는 코드를 작성하세요.”
원하는 결과가 나오기는 하지만 species도 각 1 빈도수로 출력되는데 이유는 .csv 파일에 칼럼명도 펭귄 개체로 인식해서 함께 빈도수를 계산했기 때문이다. 이에 대한 문제도 제기하고 프롬프트를 수정해보자.
$ sgpt -s "펭귄 종별로 구분된 palmer penguins csv 파일이 세개 data/ 폴더안에 있습니다. \
> 각각의 파일명은 penguin_adelie.csv, penguin_chinstrap.csv, penguin_gentoo.csv 으로 \
> 종은 species 첫번째 칼럼에 위치하고, 종별 펭귄 개체수 빈도수를 계산하는 코드를 작성하세요."
cat data/penguin_adelie.csv | cut -d ',' -f 1 | sort | uniq -c
cat data/penguin_chinstrap.csv | cut -d ',' -f 1 | sort | uniq -c
cat data/penguin_gentoo.csv | cut -d ',' -f 1 | sort | uniq -c
[E]xecute, [D]escribe, [A]bort: E
152 Adelie
1 species
68 Chinstrap
1 species
124 Gentoo
1 species첫번째 행이 칼럼명임을 명시해서 세번째 프롬프트를 작성한다. 하지만 제시된 프롬프트만으로 깔끔한 결과를 제시하지 못하고 있다.
세번째 분석 프롬프트
“펭귄 종별로 구분된 palmer penguins csv 파일이 세개 data/ 폴더안에 있습니다.
각각의 파일명은 penguin_adelie.csv, penguin_chinstrap.csv, penguin_gentoo.csv 으로
종은 species 첫번째 칼럼에 위치하고, 첫번째 행은 칼럼명이고, 종별 펭귄 개체수 빈도수를 계산하는 코드를 작성하세요.”
$ sgpt -s "펭귄 종별로 구분된 palmer penguins csv 파일이 세개 data/ 폴더안에 있습니다. \
> 각각의 파일명은 penguin_adelie.csv, penguin_chinstrap.csv, penguin_gentoo.csv 으로 \
> 종은 species 첫번째 칼럼에 위치하고, 첫번째 행은 칼럼명이고, 종별 펭귄 개체수 빈도수를 계산하는 코드를 작성하세요."
awk -F"," 'NR>1{a[$1]++} END{for(i in a) print i,a[i]}' data/penguin_adelie.csv data/penguin_chinstrap.csv data/penguin_gentoo.csv
[E]xecute, [D]escribe, [A]bort: D
Count the number of occurrences of the first column in three CSV files and print the results.
[E]xecute, [D]escribe, [A]bort: E
Gentoo 124
Chinstrap 68
Adelie 152
species 2맥락을 유지하여 원하는 결과를 얻을 수 있는 챗GPT 채팅 인터페이스를 사용하여 결과를 도출할 수 있도록 작업해보자. 먼저 sgpt가 제시한 유닉스 쉘 스크립트를 챗GPT를 통해 의미를 파악해보자.
코드해석 프롬프트
다음 유닉스 쉘 코드를 해석해주세요. awk -F’,’ ‘NR>1{a[$1]++} END{for(i in a) print i,a[i]}’ data/penguin_adelie.csv data/penguin_chinstrap.csv data/penguin_gentoo.csv
주어진 awk 명령은 3개의 CSV 파일(penguin_adelie.csv, penguin_chinstrap.csv, penguin_gentoo.csv)에 대해 동작하는데, 이 파일들의 각 줄을 처리합니다. -F’,’는 각 라인이 쉼표(,)로 구분된 필드로 구성된 CSV 형식임을 의미합니다.
awk 스크립트의 각 부분을 분석하면 다음과 같습니다:
NR>1 {a[$1]++}: NR은 현재까지 읽은 라인 수를 나타내는 변수입니다. NR>1이라는 조건은 첫 번째 행(즉, 헤더 행)을 건너뛰도록 합니다. 그 다음에 오는 {a[$1]++}는 첫 번째 필드($1)의 값을 key로 사용하여 배열 a의 해당 요소의 값을 1 증가시킵니다. 다시 말해, 이 명령은 각 파일에서 첫 번째 필드의 값이 나타나는 횟수를 계산합니다.
END {for(i in a) print i,a[i]}: 이 부분은 모든 입력을 처리한 후 실행되는 명령입니다. END 부분에서는 for 반복문을 사용하여 배열 a의 모든 요소를 반복하고, 각 key(i)와 그에 대응하는 값(a[i])을 출력합니다.
결국, 이 awk 명령은 3개의 CSV 파일에서 첫 번째 필드의 각 값이 나타나는 횟수를 출력합니다. 첫 번째 행(헤더)은 건너뜁니다. 이 코드는 첫 필드가 범주형 변수(예: 특정 분류)인 경우 해당 변수의 각 값의 출현 빈도를 확인하는 데 유용할 수 있습니다.
species 2를 제거하는 유닉스 쉘 코드를 작성하는 것이 목표라서 이를 달성할 수 있도록 프롬프트에 직설적으로 작성한다.
species 2 제거 프롬프트
쉘 코드를 실행하면 다음과 같은 결과가 나옵니다. species 2 를 제외시키도록 코드를 다시 작성해주세요.
Gentoo 124 Chinstrap 68 Adelie 152 species 2
주어진 출력에서 ’species’라는 키 값이 있습니다. 이 값은 아마도 csv 파일의 헤더에서 오는 값일 것입니다. 그렇다면, awk 명령을 수정하여 ’species’를 무시하도록 할 수 있습니다. 다음은 수정된 코드입니다:
awk -F"," 'NR>1 && $1 != "species" {a[$1]++} END{for(i in a) print i,a[i]}' data/penguin_adelie.csv data/penguin_chinstrap.csv data/penguin_gentoo.csv이 코드는 원래의 코드에서 추가된 && $1 != “species” 조건을 통해, 첫 번째 필드의 값이 “species”인 행은 건너뛰게 됩니다. 이렇게 하면 ’species’라는 키 값이 결과에서 제외되게 됩니다.
챗GPT를 통해 얻은 명령어를 복사하여 쉘 프롬프트에 붙여넣고 실행시키면 원하는 결과를 얻은 것이 확인된다.
$ awk -F"," 'NR>1 && $1 != "species" {a[$1]++} END{for(i in a) print i,a[i]}' data/penguin_adelie.csv data/penguin_chinstrap.csv data/penguin_gentoo.csv
Gentoo 124
Chinstrap 68
Adelie 152R 코드를 통해 세개로 쪼개진 .csv 파일이 목표를 달성했는지 검사해보자. 펭귄 종 순서는 다르지만 정확하게 펭귄종별 관측 빈도수가 일치함을 확인할 수 있다.
palmerpenguins::penguins %>%
count(species)
#> # A tibble: 3 × 2
#> species n
#> <fct> <int>
#> 1 Adelie 152
#> 2 Chinstrap 68
#> 3 Gentoo 124