system2("ls", "-l", stdout = TRUE, stderr = TRUE)
#> Error: The `system()` function is unsupported under Emscripten.24 작업 자동화
파일, 네트워크, 서비스, 그리고 데이터베이스에서 데이터를 읽어왔다. R은 또한 여러분의 로컬 컴퓨터 디렉터리와 폴더를 훑어서 파일도 읽어온다.
이번 장에서, 여러분의 로컬 컴퓨터를 스캔하고 각 파일에 대해서 연산을 수행하는 프로그램을 작성한다. 파일은 디렉터리(또한 “폴더”라고도 부른다.)에 정렬되어 보관된다. 간단한 R 스크립트로 전체 로컬 컴퓨터나 디렉터리 여기저기 뒤져야 찾아지는 수백 수천 개 파일에 대한 단순한 작업을 짧게 수행한다.
트리상의 디렉터리나 파일을 여기저기 돌아다니기 위해서 list.files과 for 루프를 사용한다. readLines이 파일 콘텐츠를 읽는 루프를 작성하는 것과 비슷하게, websocket은 네트워크 연결된 콘텐츠를 읽는 루프를 작성하고, httr`은 웹문서를 열어 콘텐츠를 루프를 통해서 읽어오게 한다.
24.1 파일 이름과 경로
모든 실행 프로그램은 “현재 디렉터리”를 가지고 있는데 작업 대부분을 수행하는 디폴트 디렉터리가 된다. 예를 들어, 읽기 위해서 파일을 연다면, R은 현재 디렉터리에서 파일을 찾는다.
libuv C 라이브러리에 기반한 fs 패키지는 파일과 디렉터리를 작업하는 함수를 제공한다. path_wd() 함수는 현재 디렉터리 이름을 반환한다.
cwd는 current working directory의 약자로 현재 작업 디렉터리다. 예제의 결과는 C:/swc/gpt-coding인데 현재 작성 중인 전자책 gpt-coding의 홈 디렉터리가 된다.
파일을 식별하는 cwd 같은 문자열을 경로(path)라고 부른다. 상대경로(relative path)는 현재 디렉터리에서 시작하고, 절대경로(absolute path)는 파일 시스템의 가장 최상단의 디렉터리에서 시작한다.
지금까지 살펴본 경로는 간단한 파일 이름이어서, 현재 디렉터리에서 상대적이다. 파일의 절대 경로를 알아내기 위해서 fs::path_abs() 함수를 사용한다.
fs 패키지의 file_exists 함수와 기본 내장함수 file.exists 함수는 파일 또는 디렉터리가 존재하는지 여부를 확인한다. 먼저 music 디렉터리와 memo.txt 파일을 생성한 후 memo.txt 파일이나 music 디렉터리가 존재하는지 여부를 확인한다. dir_exists는 디렉터리, file_exists는 파일이 존재하는지 검사한다.
dir_ls() 함수는 주어진 디렉터리에 파일 리스트(그리고 다른 디렉터리)를 반환한다.
web-r, pyodide
web-r, pyodide 모두 자바스크립트 emscripten 환경에서 실행되기 때문에, 시스템 명령어를 실행할 수 없다.
import os
cmd = 'ls -l'
fp = os.popen(cmd)
#> OSError: [Errno 138] emscripten does not support processes.24.2 BBC 뉴스 사례
작업 자동화를 별도의 주제로 분리하여 다루는 이유는, BBC 뉴스 데이터셋(Greene 와/과 Cunningham 2006)과 같은 파일들이 디렉터리에 저장될 경우, 이를 효과적으로 처리할 수 있기 때문이다. 인공지능의 기반 기술인 기계학습과 딥러닝은, 전 세계 다양한 언어로 수집된 상상을 초월하는 양의 텍스트 데이터를 가공하여 AI 모델 개발의 기초 데이터로 활용한다.
BBC 뉴스 데이터셋은 5개 뉴스 범주에 맞춰 각 뉴스는 001.txt, 002.txt, 003.txt 등과 같은 파일명으로 저장되어 있다. 먼저 궁금한 점은 BBC 뉴스 데이터가 각 범주별로 몇 개의 기사가 있는지 빈도수를 확인하는 것이다.
이 작업을 위해서 디렉터리 파일 정보를 파일시스템에서 fs 패키지 dir_ls() 함수로 읽어온 후에 dplyr 패키지 enframe() 함수로 데이터프레임으로 변환하여 디렉터리인지 파일인지 구분하는 작업을 if_else 문으로 수행하고 빈도수를 count() 함수로 계산한다.
bbc_files <- fs::dir_ls("data/bbc/", recurse = TRUE)
bbc_files |>
enframe() |>
mutate(구분 = if_else(str_detect(value, "txt$"), "파일", "디렉토리")) |>
count(구분, name = "건수")
#> # A tibble: 2 × 2
#> 구분 건수
#> <chr> <int>
#> 1 디렉토리 6
#> 2 파일 2225import os
import pandas as pd
bbc_files = []
for root, dirs, files in os.walk("data/bbc/"):
for name in files:
bbc_files.append(os.path.join(root, name))
for name in dirs:
bbc_files.append(os.path.join(root, name))
df = pd.DataFrame({'value': bbc_files})
df['구분'] = df['value'].apply(lambda x: '파일' if x.endswith('.txt') else '디렉토리')
result = df['구분'].value_counts().reset_index()
result.columns = ['구분', '건수']
print(result) 구분 건수
0 파일 2225
1 디렉토리 6이제 BBC 뉴스 데이터셋의 각 범주별로 몇 개의 기사가 있는지 빈도수를 계산한다. bbc_files에 있는 파일 목록을 데이터 프레임으로 변환하고, 파일 경로를 구분자 “/”를 기준으로 나누어 여러 열로 분리한다. 파일 이름이 “.txt”로 끝나는지 여부에 따라 파일과 디렉터리를 구분하고, 디렉터리가 아닌 파일들만을 남겨둔 후, 각 범주별로 뉴스 기사의 수를 세어 빈도수를 계산한다.
bbc_files |>
enframe() |>
separate(name, into = c("data", "bbc", "범주"), sep = "/") |>
mutate(구분 = if_else(str_detect(value, "txt$"), "파일", "디렉토리")) |>
filter(구분 != "디렉토리") |>
count(범주, name = "뉴스기사수")
#> # A tibble: 5 × 2
#> 범주 뉴스기사수
#> <chr> <int>
#> 1 business 510
#> 2 entertainment 386
#> 3 politics 417
#> 4 sport 511
#> 5 tech 401import os
import pandas as pd
# data/bbc/ 디렉토리의 파일 목록을 가져오는 함수
def get_file_list(directory):
file_list = []
for root, dirs, files in os.walk(directory):
for file in files:
file_list.append(os.path.join(root, file))
return file_list
# 파일 목록 가져오기
bbc_files = get_file_list("data/bbc/")
# 데이터 프레임 생성
df = pd.DataFrame({'value': bbc_files})
# 경로를 '/'를 기준으로 분리
df[['범주', '파일']] = df['value'].str.split('\\', expand=True)
df = df.dropna()
# 범주별로 뉴스기사 수 세기
result = df['범주'].value_counts().reset_index()
result.columns = ['범주', '뉴스기사수']
print(result) 범주 뉴스기사수
0 data/bbc/sport 511
1 data/bbc/business 510
2 data/bbc/politics 417
3 data/bbc/tech 401
4 data/bbc/entertainment 38624.3 파이프(Pipes)
대부분의 운영 시스템은 쉘(shell)로 알려진 명령어 기반 인터페이스를 지원한다. 일반적으로 쉘은 파일 시스템을 탐색하거나 응용 프로그램을 실행하는 명령어를 지원한다. 예를 들어, 유닉스에서 cd 명령어로 디렉터리를 변경하고 ls 명령어로 디렉터리의 콘텐츠를 보여주고, firefox를 타이핑해서 웹 브라우저를 실행시킬 수 있다.
쉘에서 실행시킬 수 있는 어떤 프로그램이나 파이프(pipe)를 사용하여 R에서도 실행시킬 수 있다. 파이프는 작동 중인 프로세스를 표현하는 객체다. 파이프를 사용하면 프로세스의 입출력을 읽거나 쓸 수 있다.
예를 들어, 유닉스 명령어1 ls -l은 정상적으로 현재 디렉터리의 콘텐츠(긴 형식으로)를 보여준다. system2() 내장함수, 혹은 processx, sys 패키지를 가지고 ls를 실행시킬 수 있다. 인자는 쉘 명령어를 포함하는 문자열이다.
system2("ls", "-l data", stdout = TRUE, stderr = TRUE)
#> [1] "total 6759"
#> [2] "drwxr-xr-x 1 statkclee 없음 0 Mar 8 10:09 bbc"
#> [3] "-rw-r--r-- 1 statkclee 없음 107 Feb 28 19:16 ch01-text.txt"
#> [4] "-rw-r--r-- 1 statkclee 없음 96536 Mar 2 10:36 mbox-short.txt"
#> [5] "-rw-r--r-- 1 statkclee 없음 6819047 Mar 2 10:35 mbox.txt"
#> [6] "-rw-r--r-- 1 statkclee 없음 212 Mar 4 09:42 mbox_debug.py"
#> [7] "-rw-r--r-- 1 statkclee 없음 171 Mar 4 19:03 romeo.txt" import subprocess
result = subprocess.run(["dir", "data"], shell=True, capture_output=True, text=True)
print("stdout:", result.stdout)
#> stdout: D 드라이브의 볼륨: 데이터
#> 볼륨 일련 번호: 66D3-65EC
#>
#> d:\tcs\gpt-coding\data 디렉터리
#>
#> 2024-03-08 오전 10:09 <DIR> .
#> 2024-03-08 오전 10:09 <DIR> ..
#> 2024-03-08 오전 10:09 <DIR> bbc
#> 2024-02-28 오후 07:16 107 ch01-text.txt
#> 2024-03-02 오전 10:36 96,536 mbox-short.txt
#> 2024-03-02 오전 10:35 6,819,047 mbox.txt
#> 2024-03-04 오전 09:42 212 mbox_debug.py
#> 2024-03-04 오후 07:03 171 romeo.txt
#> 5개 파일 6,916,073 바이트
#> 3개 디렉터리 1,223,577,202,688 바이트 남음24.3.1 유닉스 철학과 파이프
통계 예측모형, 기계학습, 딥러닝 시스템을 개발할 경우 유닉스/리눅스 운영체제로 환경을 통일하고 텍스트 파일을 모든 프로그램과 시스템이 의사소통하는 기본 인터페이스로 잡고, 이를 파이프로 연결한다.
- 텍스트 데이터로 분석에 사용될 혹은 훈련 데이터로 준비한다.
- 파이썬 혹은 쉘스크립트, R스크립트를 활용하여 전처리한다.
- R
tidymodels혹은 파이썬Scikit-learn예측모형을 적합, 기계학습 훈련, 시각화를 수행한다. - 마크다운(웹), \(\LaTeX\) (조판) 출력형식에 맞춰 서식을 결정한다.
- 최종 결과를 텍스트, 이미지 파일, pdf, html로 출력한다.
$ cat data.txt | preProcesswithPython.py | runModelwithR.R | formatOutput.sh > mlOutput.txt
[원문] Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface. – Doug McIlroy
- 한 가지 작업만 매우 잘하는 프로그램을 작성한다.
- 프로그램이 함께 동작하도록 작성한다.
- 텍스트를 다루는 프로그램을 작성한다. 이유는 어디서나 사용되는 인터페이스가 되기 때문이다.
24.4 명령 줄 인자
명령라인 인터페이스에서 R 스크립트를 실행하고 다양한 R 스크립트 실행방법을 살펴보자. 먼저, 유닉스/리눅스/맥OS/윈도우 운영체제가 준비되었다면 R스크립트 실행환경을 준비한다. 2 윈도우 사용자는 깃배쉬(Git Bash)를 설치하면 윈도우에서도 리눅스/맥OS와 동일한 명령어를 사용할 수 있다. 내부적으로 깃배쉬가 mintty 터미널을 사용하고 있어서 리눅스/맥OS와 동일한 명령어를 사용할 수 있다.
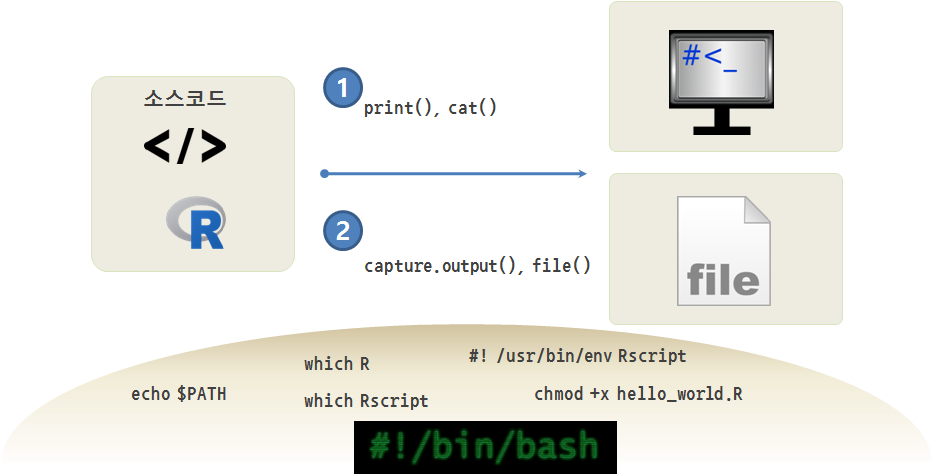
24.4.1 R 스크립트 실행환경
R과 스크립트를 실행할 Rscript 실행프로그램이 위치한 디렉터리를 확인한다. 여기에 사용되는 명령어는 which다. which R 명령어를 통해 R 실행파일이 윈도우 /c/Program Files/R/R-4.3.2/bin/R 디렉터리에 위치한 것을 확인할 수 있다.
$ which R
/c/Program Files/R/R-4.3.2/bin/Rwhich Rscript 명령어를 통해 Rscript 실행파일도 /usr/bin/ 디렉터리에 위치한 것을 확인할 수 있다.
$ which Rscript
/c/Program Files/R/R-4.3.2/bin/rscript24.4.2 R 스크립트 실행
.R 스크립트 파일을 명령라인 인터페이스로 실행하는 방법은 다양하다. 먼저 hello_world.R 스크립트 파일을 생성한다.
#! /usr/bin/env Rscript
print("Hello World!!!")쉬뱅(shebang, #!) 다음에 스크립트를 실행할 프로그램을 지정한다. Rscript로 지정하여 R스크립트를 실행하는 데 사용한다. 윈도우에서 쉬뱅 라인은 관례에 불과하며 유닉스 계열 시스템과 같은 방식으로 기능하지 않는다. R 코드는 플랫폼에 독립적이기 때문에 쉬뱅을 넣어 다른 운영체제에 대한 호환성도 함께 고려한다.
#! /usr/bin/env Rscript
$ chmod +x hello_world.R
$ ./hello_world.Rchmod +x 명령어를 통해서 일반 텍스트 파일을 실행 가능한 파일 형식으로 지정한다. hello_world.R 파일이 실행 가능한 형태가 되었기 때문에 ./hello_world.R 명령어로 R스크립트를 실행시킨다.
Hello World!!!
R 스크립트 파일을 실행하는 다른 방법
R스크립트를 실행하는 방법은 다양하다.
$ R --slave -f hello_world.R
$ Rscript hello_world.RRscript 명령어로 실행을 시켜도 동일한 산출 결과가 출력된다.
$ R CMD BATCH hello_world.R hello_world_output.txtR CMD BATCH 명령어로 실행시키면 실행 결과가 hello_world_output.txt 파일에 저장된다. hello_world_output.txt 파일명을 지정하지 않으면 hello_world.Rout 파일에 저장된다.
$ R --no-save << RSCRIPT
print("Hello World")
RSCRIPTR --no-save << 사용법도 가능하다.
24.5 R 스크립트
24.5.1 한 줄 R스크립트 작성
Rscript r_session_info.R 명령어를 실행해서 실제로 RStudio나 R 콘솔을 열지 않고도 R 세션 정보를 명령라인 인터페이스에서 처리하는 R 스크립트를 작성한다. 텍스트 편집기를 열고, sessionInfo()를 적고 파일명을 r_session_info.R로 저장한다. 3
배쉬 쉘에서 R스크립트를 실행해서 R 세션 정보를 받아 확인한다.
$ Rscript r_session_info.R
R version 4.2.2 (2022-10-31 ucrt)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 10 x64 (build 19045)
Matrix products: default
locale:
[1] LC_COLLATE=Korean_Korea.utf8 LC_CTYPE=Korean_Korea.utf8
[3] LC_MONETARY=Korean_Korea.utf8 LC_NUMERIC=C
[5] LC_TIME=Korean_Korea.utf8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
...24.5.2 출력결과 파일저장
> 파이프 연산자를 사용해서 R 스크립트 출력결과를 텍스트 파일로 저장한다.
$ Rscript r_session_info.R > r_session_info_pipe_output.txt또 다른 방법은 R 스크립트 내부에서 출력결과를 파일에 저장하고 프로그램을 종료하는 방법도 있다.
capture.output 함수를 cat과 함께 사용하는데, 한글도 적용이 가능하도록, encoding="UTF-8"도 추가한다.
output <- capture.output(sessionInfo())
cat("R 세션정보", output, file="./r_session_info_rscript.txt", sep="\n", encoding="UTF-8")Rscript r_session_info.R 명령어를 실행시키면 다음과 같이 실행결과가 텍스트 파일 r_session_info_rscript.txt로 떨어진다.
"R 세션정보
R version 4.2.2 (2022-10-31 ucrt)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 10 x64 (build 19045)
Matrix products: default
locale:
[1] LC_COLLATE=Korean_Korea.utf8 LC_CTYPE=Korean_Korea.utf8
[3] LC_MONETARY=Korean_Korea.utf8 LC_NUMERIC=C
[5] LC_TIME=Korean_Korea.utf8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
...24.6 국가별 GDP 사례
.R 스크립트를 유닉스/리눅스상에서 유연하게 동작시킨다. R 스크립트를 수정하지 않고, 인자를 바꿔 작업을 수행하는 방법을 살펴보자. 국가별 통계를 데이터 파일을 달리하여 R스크립트 통계량을 산출하는 방법을 사례로 구현해보자.
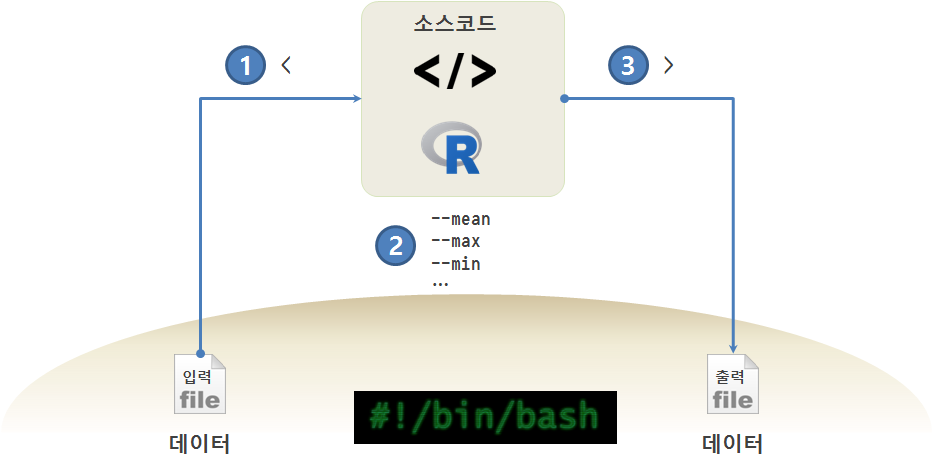
24.6.1 인자 받는 R 스크립트
유닉스/GNU리눅스 환경에서 통계모형, 기계학습, 딥러닝 작업을 하게 되면 텍스트 형태 데이터, R스크립트, 출력 산출물을 갖게 되고, 입력 데이터를 출력 산출물로 변환시키는 데 R이 역할을 하게 된다.
R 스크립트를 유연하게 만들게 되면 데이터만 바꿔도 산출물을 생성해 내고, 경우에 따라 인자값을 달리하면 원하는 다른 결과를 얻게 된다.
24.6.2 데이터 변경 R 스크립트
(Pole, West, 와/과 Harrison 2018) 가 집필한 책에 포함된 시계열 데이터 웹사이트 SOME TIME SERIES DATA SETS에서 Per capita annual GDP for several countries during 1950-1983 (first row is 1950, last is 1983) 데이터를 사용한다. 데이터를 austria.csv, canada.csv, france.csv와 같이 구분하여 저장한다.
R 스크립트 시제품 제작
먼저 austria.csv 파일을 불러와서 평균을 계산하는 R스크립트를 작성한다. code 디렉터리 r-args-ex01.R 파일명으로 저장한다.
#!/usr/bin/env Rscript
gdp.df <- read.csv("data/austria.csv", sep=",", head=TRUE)
# 평균계산
gdp.mean <- mean(gdp.df$gdp, na.rm = TRUE)
# 계산결과 화면출력
cat("평균: ", gdp.mean, "\n")Rscript code/r-args-ex01.R 실행결과 예상대로 평균 GDP가 계산되었다.
$ Rscript code/r-args-ex01.R
평균: 0.06553276입력파일명 변경
국가가 더 많을 수도 있지만, austria.csv, france.csv, canada.csv 3개 국가가 csv 파일로 데이터가 저장되어 있으니, 입력파일을 달리하여 평균을 계산하도록 R스크립트를 작성한다.
commandArgs 명령어를 통해 명령라인에서 인자를 받아온다. 인자가 순서대로 들어오기 때문에 첫 번째 인자로 들어오는 국가에 대한 GDP 평균을 구하고, 이를 화면에 출력하는 R스크립트다. R 내장함수 sub 함수와 정규표현식을 사용해서 파일명 앞쪽 – .csv 확장자 제거 – 만을 뽑아내어 국가명을 명기했다. code 디렉터리 r-args-ex02.R 파일명으로 저장한다.
#!/usr/bin/env Rscript
args = commandArgs(trailingOnly=TRUE)
country <- args[1]
# country <- "data/austria.csv"
# 데이터 불러오기
gdp_df <- read.csv(country, sep=",", head=TRUE)
# 평균계산
gdp_mean <- mean(gdp_df$gdp)
# 국가명 출력
country_name <- sub("data/(.*)\\.csv", "\\1", country)
# 계산결과 화면출력
cat("국가명:", country_name, " 평균: ", gdp_mean, "\n")상기 R스크립트를 쉘에서 실행한 결과는 다음과 같다. code 디렉터리에 r-args-ex02.R 스크립트 파일이 저장되어 있다.
$ Rscript code/r-args-ex02.R data/austria.csv
국가명: austria 평균: 0.06553276
$ Rscript code/r-args-ex02.R data/france.csv
국가명: france 평균: 20.95751
$ Rscript code/r-args-ex02.R data/canada.csv
국가명: canada 평균: 5.817088국가별 기본통계
국가 데이터를 바꾸는 것에 더해서 최소, 평균, 최대 GDP를 계산하는 로직을 추가한다. commandArgs 함수로 인자를 받는데, 최종 인자는 -1로 지정되기 때문에 그런 특성을 이용하여 R스크립트를 작성한다. 따라서, 첫 번째 인자에 최소, 평균, 최소를 구할 것인지 정보를 받고, 마지막 인자로 파일명을 받는다.
#!/usr/bin/env Rscript
args = commandArgs(trailingOnly=TRUE)
action = args[1]
country <- args[-1]
# 데이터 불러오기
gdp_df <- read.csv(country, sep=",", head=TRUE)
# 국가명 추출
country_name <- sub("data/(.*)\\.csv", "\\1", country)
# 기초 통계량 계산
if(action == "--min") {
gdp_min <- min(gdp_df$gdp)
cat("국가명:", country_name, " 최소: ", gdp_min, "\n")
}else if(action == "--mean") {
gdp_mean <- mean(gdp_df$gdp)
cat("국가명:", country_name, " 평균: ", gdp_mean, "\n")
}else if (action=="--max"){
gdp_max <- max(gdp_df$gdp)
cat("국가명:", country_name, " 최대: ", gdp_max, "\n")
}Rscript code/r-args-ex03.R --min data/canada.csv 명령라인을 살펴보면, r-args-ex03.R R 스크립트를 실행하고, --min 인자로 최소값을 계산하는데, canada.csv 데이터 파일을 이용한다.
$ Rscript code/r-args-ex03.R --min data/canada.csv
국가명: canada 최소: 3.651109
$ Rscript code/r-args-ex03.R --max data/canada.csv
국가명: canada 최대: 8.382785
$ Rscript code/r-args-ex03.R --mean data/canada.csv
국가명: canada 평균: 5.81708824.7 용어 정의
- 절대경로(absolute path): 파일이나 디렉터리가 어디에 저장되어 있는지를 저장하는 문자열로 “최상단의 디렉터리”에서 시작해서, 현재 작업 디렉터리에 관계없이 파일이나 디렉터리를 접근하는 데 사용할 수 있다.
- 체크썸(checksum): 해싱(hashing)을 참조하세요. “체크썸(checksum)”단어는 네트워크로 데이터가 보내지거나 백업 매체에 쓰여지고 다시 읽어올 때, 데이터가 왜곡되었는지를 검증하는 필요에서 생겨났다. 데이터가 쓰여지거나 보내질 때, 송신 시스템은 체크썸을 계산하고 또한 체크썸도 보낸다. 데이터가 읽혀지거나 받았을 때, 수신 시스템에서 수신된 데이터의 체크썸을 다시 계산하고 받은 체크썸과 비교한다. 만약 체크썸이 매칭되지 않으면, 전송 시에 데이터가 왜곡된 것으로 판단해야 한다.
- 명령 줄 인자(command line argument): R 스크립트 파일 이름 뒤에 명령 줄에 매개 변수.
-
현재 작업 디렉터리(current working directory): “작업하고 있는” 현재 디렉터리. 명령-줄 인터페이스에서 대부분의 시스템에
cd명령어를 사용하여 작업 디렉터리를 변경할 수 있다. 경로 정보 없이 파일만을 사용하여 R에서 파일을 열게 될 때, 파일은 프로그램을 실행하고 있는 현재 작업 디렉터리에 있어야 한다. -
해싱(hashing): 가능한 큰 데이터를 읽고 그 데이터에 대해서 유일한 체크썸을 생성하는 것. 최고의 해시 함수는 거의 “충돌(collision)”을 만들지 않는다. 여기서 충돌은 서로 다른 두 데이터 스트림에 해시 함수를 줄 때 동일한 해시값을 돌려받는 것이다. MD5, SHA1, SHA256은 가장 많이 사용되는 해시 함수의 사례다.
- 파이프(pipe): 파이프는 실행하는 프로그램에 연결이다. 파이프를 사용해서, 데이터를 다른 프로그램에 보내거나 그 프로그램에서 데이터를 받는 프로그램을 작성할 수 있다. 파이프는 소켓(socket)과 매우 유사하다. 차이점은 파이프는 동일한 컴퓨터에서 실행되는 프로그램을 연결하는 데만 사용된다는 것이다. (즉, 네트워크를 통해서는 사용할 수 없다.)
- 상대경로(relative path): 파일 혹은 디렉터리가 어디에 저장되었는지를 현재 작업 디렉터리에 상대적으로 표현하는 문자열.
- 쉘(shell): 운영 시스템에 명령줄 인터페이스. 다른 시스템에서는 또한 “터미널 프로그램(terminal program)”이라고 부른다. 이런 인터페이스에서 라인에 명령어와 매개 변수를 타입하고 명령을 실행하기 위해서 “엔터(enter)”를 누른다.
- 워크(walk): 모든 디렉터리를 방문할 때까지 디렉터리, 하위 디렉터리, 하위의 하위 디렉터리 전체 트리를 방문하는 개념을 나타내기 위해서 사용된 용어. 여기서이것을 “디렉터리 트리를 워크”한다고 부른다.
연습문제
영화 파일(예를 들어 .avi, .mp4)과 음악 파일(예를 들어 .mp3, .wav)이 다양한 디렉터리에 분산되어 저장되는 경우가 있다. 대규모 파일 컬렉션에서는 동일한 노래가 다른 디렉터리나 파일 이름으로 중복되어 저장되어 있는 경우를 종종 발견한다. 연습문제에서 이와 같은 중복 파일을 찾아내는 것을 목표로 하며, 이를 통해 보다 효율적인 파일 관리와 저장 공간 최적화를 도모할 수 있다.
영화는 대략 2시간 전후, 음악파일은 3분 전후 길이를 갖고 있어 파일 크기에 차이가 난다. 확장자를 통해 영화 혹은 음원을 구분할 수도 있지만, 파일 크기 정보를 가지고 영화파일과 음악파일을 구분하여 모든 영화파일은
movie폴더에, 음악 파일은music폴더에 저장하는 코드를 작성한다..mp3같은 확장자를 가진 파일을 모든 디렉터리와 하위 디렉터리를 검색해서 동일한 크기를 가진 파일 짝을 목록으로 보여주는 프로그램을 작성한다.-
체크썸(checksum) 알고리즘이나 해싱을 사용하여 중복 콘텐츠를 가진 파일을 찾는 이전의 프로그램을 개작하세요. 예를 들어, MD5 (Message-Digest algorithm 5)는 임의적으로 긴 “메시지”를 가지고 128비트 “체크썸”을 반환한다. 다른 콘텐츠를 가진 두 파일이 같은 체크썸을 반환할 확률은 매우 적다.
wikipedia.org/wiki/Md5에서 MD5에 대해서 더 배울 수 있다. 다음 코드 조각은 파일을 열고, 읽고, 체크썸을 계산한다.
체크섬을 계산하고 키로 이미 딕셔너리에 있게 되면, 중복 콘텐츠인 두 파일이 있어서 딕셔너리에 파일과 방금 전에 읽은 파일을 출력한다. 사진 파일 폴더에서 실행한 샘플 출력물이 다음에 있다.
./2004/11/15-11-04_0923001.jpg ./2004/11/15-11-04_1016001.jpg ./2005/06/28-06-05_1500001.jpg ./2005/06/28-06-05_1502001.jpg ./2006/08/11-08-06_205948_01.jpg ./2006/08/12-08-06_155318_02.jpg명백하게 때때로 같은 사진을 한 번 이상 보내거나 원본을 삭제하지 않고 종종 사진 사본을 만든다.
파이프를 사용하여
ls같은 운영 시스템 명령어로 대화할 때, 무슨 운영 시스템을 사용하는지 알고 운영 시스템에서 지원되는 명령어로 파이프를 열 수 있다는 것이 중요하다. ↩︎