10 데이터프레임
다른 프로그래밍 언어에서 다루지 않는 독특한 자료구조가 데이터프레임(Dataframe)이다. R도 프로그래밍 언어이기 때문에 다른 언어에서 갖고 있는 자료구조를 대부분 갖추고 있지만, 데이터 분석, 시각화, 모형 개발 등에 꼭 필요한 기본 자료구조가 데이터프레임이다. 데이터프레임을 본격적으로 살펴보기 전에 통계학에서 다루는 측정에 대해 살펴보고, 측정 척도(scale)에 대한 이론적 배경을 이해한다. 척도의 개념에 대응되는 R 자료구조를 통해 데이터프레임과 추후 프로그래밍 과정에서 많이 다뤄지는 리스트에 대한 차별점도 살펴본다.
10.1 측정 변수의 구분
분석 과정에서 현실 세계의 다양한 사건과 현상들을 관찰하고, 이후 측정 단계를 거쳐 수치나 범주 형태로 자료, 즉 데이터로 생산된다. 이는 복잡한 실제 현상들을 체계적이고 구조화된 데이터로 전환하는 과정으로, 이러한 데이터 분석 과정에서 컴퓨터 활용이 중요하다. 프로그래밍 언어들마다 데이터를 처리하고 관리하기 위한 고유한 자료구조를 가지고 있다. 측정 단계에서 생산된 다양한 데이터를 담아낼 수 있는 자료구조가 데이터프레임이다.
자료의 고유 특성을 수치화하는 측정 척도로 명목형, 순서형, 구간형, 비율형 4가지 주요 유형으로 분류된다. 측정 척도는 데이터 유형별로 적합한 유의미한 통계량을 결정하는 데 중요한 역할을 한다. (Stevens 1946) (Wiener 1921) (이경화 2020)
- 명목척도(Nominal): 단순히 개체 특성 분류를 위해 숫자나 부호를 부여한 척도로 숫자는 의미가 없음.
- 남자: M, 여자: F 혹은 월: 1, 화: 2, … 일:7 혹은 갑:1, 을:2, 병:3, …
- 서열척도(Ordinal): 명목척도에 부가적으로 “순서(서열)” 정보가 추가된 척도로 측정대상 간 차이는 정보가 없음.
- 군대계급: 사병, 장교, 장군 등
- 소득계층: 1분위, 2분위, 3분위 등
- 등간척도(Interval): 서열척도에 부가적으로 “등간격” 정보가 추가된 척도
- 온도에서 0도는 상대적인 위치로 수학에서 다루는 개념과 차이가 있음.
- 온도가 서울 10도, 제주 20도는 제주가 서울보다 온도가 2배 높지 않음.
- 온도, 시력, IQ 지수, 물가지수 등
- 비율척도(Ratio): 구간척도에 “비율” 비교특성이 추가된 척도로 “비율 등간격” 특성이 포함됨.
- 키나 몸무게에서 0은 수학적 의미 0을 의미함.
- 100m는 200m의 절반 의미.
- 절대 ’0’을 가지고 사칙연산이 가능함.
- 연령, 월소득, TV 시청률 등.
10.2 기본 자료구조
측정은 한 번만 이뤄지는 것이 아닌 여러 관측점을 통해 데이터로 표현되기 때문에 이를 담을 수 있는 벡터 자료구조가 필요하다. R 언어에서 벡터 자료형을 주로 원자 벡터와 리스트로 분류한다. 원자 벡터는 논리형(logical), 정수형(integer), 부동 소수점형(double), 문자형(character), 복소수형(complex), raw 등 여섯 가지 자료형을 포함하며, 이중 논리형, 정수형, 부동 소수점형, 문자형이 주로 사용된다. 리스트는 다양한 자료형을 포함할 수 있는 재귀 벡터(recursive vector)로, 복잡한 데이터 구조를 효과적으로 다루는 데 적합하다.(Wickham, Çetinkaya-Rundel, 와/과 Grolemund 2023)
R에서 자료형을 type, mode, storage mode로 다르게 표현하는데 데이터 객체의 다양한 측면을 표현하기 위함이다. 자료형(type)은 객체의 내부적인 구현 유형을 표현한다. 예를 들어, 정수형, 부동 소수점형, 문자형을 들 수 있다. 모드(mode)는 객체가 프로그래밍적으로 어떻게 다뤄지는지를 나타내며, type보다 더 일반적인 개념으로 사용자 관점에서 데이터를 어떻게 사용할 수 있는지를 나타낸다. 예를 들어, 자료형이 정수형 혹은 부동 소수점형은 사용자 모드에서 숫자형(numeric)이 훨씬 수월하다. 저장 모드(storage mode)는 객체가 저장되는 방식을 나타내며, 특히 벡터의 경우에는 벡터의 원소 유형을 의미한다. 예를 들어, 정수 벡터 storage mode는 integer가 된다.
| 자료형(Type) | 사용자 모드(Mode) | 저장모드(Storage Mode) |
|---|---|---|
| logical | logical | logical |
| integer | numeric | integer |
| double | numeric | double |
| complex | complex | complex |
| character | character | character |
| raw | raw | raw |
따라서, 원자벡터는 동질적(homogeneous)이고, 리스트는 상대적으로 이질적(heterogeneous)이다. 모든 벡터는 두 가지 성질(Property)을 갖는데, 자료형과 길이로 이를 확인하는 데 typeof()와 length() 함수를 사용해서 확인한다.
모드 함수는 객체의 모드를 반환하고, 클래스 함수는 클래스를 반환한다. 가장 흔하게 만나는 객체 모드는 숫자, 문자, 논리 모드다. 리스트나 데이터프레임과 같이 다양한 모드를 한 객체 안에 포함하는 경우도 있다.
리스트(List)는 데이터를 저장하는 유연하며 강력한 방법으로 과거 리스트 자료구조를 처리하는 *apply 함수와 함께 가장 빈번하게 사용되는 자료형이다. 현재는 purrr 팩키지 map_*()함수를 사용한다. 리스트형 자료 a를 세 가지 숫자형, 문자형, 숫자형과 리스트 총 네 가지 자료형을 포함하게 작성한다. map_chr() 함수를 이용하여 mode와 class 인자를 넣어줌으로써, 각각 자료형의 모드와 자료형을 확인한다.
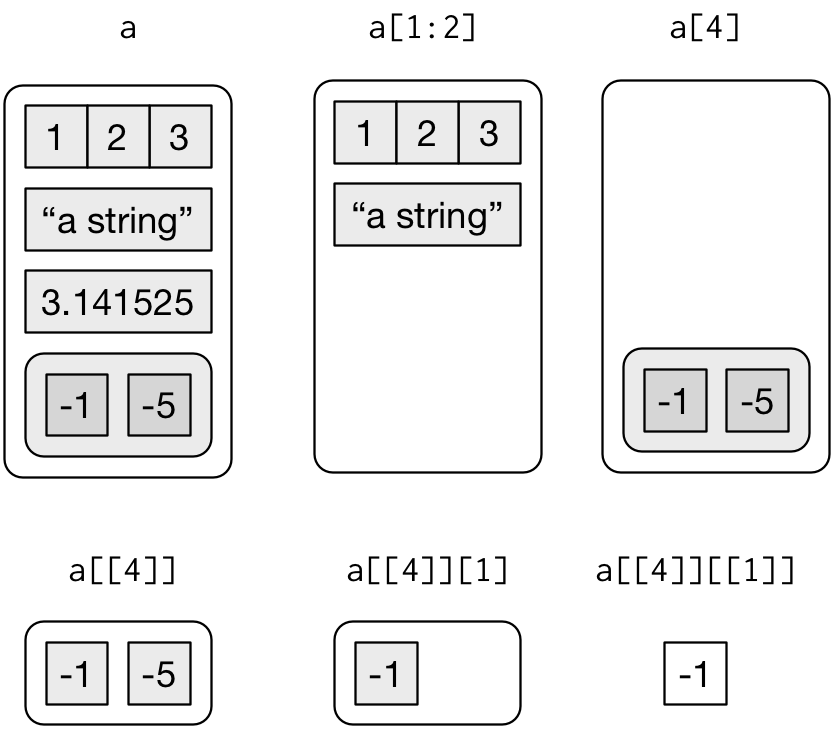
리스트에서 원소를 뽑아내는 의미를 살펴보자. 시각적으로 표현하면 다음과 같다. 리스트는 이질적인 객체를 담을 수 있다는 점에서 동질적인 것만 담을 수 있어 한계가 있는 원자벡터보다 쓰임새가 다르다. 회귀분석 결과 산출되는 lm 결과값은 다양한 정보를 담을 수 있는 리스트로 표현된다.
- 리스트 생성 :
list() - 하위 리스트 추출 :
[ - 리스트에 담긴 원소값 추출 :
[[,$→ 연산작업을 통해 위계를 갖는 구조를 제거한다.
범주형 자료를 R에 저장하기 위해서 요인(Factor) 클래스를 사용하며 요인 클래스를 사용하여 자료를 저장할 경우 저장 공간을 절약할 수 있다. 요인은 내부적으로 숫자(value)로 저장을 하고 레이블(value label)을 사용하여 표시하여 저장 공간을 절약한다.
각각의 데이터 형식에 맞는지를 다양한 테스트 함수(is.)를 이용하여 데이터 형식을 확인할 수 있다.
-
is.list: 리스트 형식인 확인 -
is.factor: 팩터 형식인지 확인 -
is.numeric: 숫자형인지 확인 -
is.data.frame: 데이터 프레임형인지 확인 -
is.character: 문자형인지 확인
10.3 자료형 확장
요인, 텍스트, 날짜와 시간도 R에서 자주 사용되는 중요한 데이터 자료형으로 별도로 다뤄진다. 이를 위해서 stringr, lubridate, forcats 팩키지를 사용해서 데이터 정제 작업은 물론 기계학습 예측모형 개발에 활용한다.
| R 자료형 | 자료형 | 예제 |
|---|---|---|
logical |
부울 | 부도여부(Y/N), 남여 |
integer |
정수 | 코로나19 감염자수 |
factor |
범주 | 정당, 색상 |
numeric |
실수 | 키, 몸무게, 주가, 환율 |
character |
텍스트 | 주소, 이름, 책제목 |
Date |
날짜 | 생일, 투표일 |
10.4 범주 자료형
명목척도 범주형, 서열척도 범주 자료형을 생성하는 경우 주의를 기울여야 한다. factor 함수를 사용해서 요인형 자료형을 생성하는데, 내부적으로 저장 공간을 효율적으로 사용하고 속도를 빠르게 하는 데 유용하다. 순서를 갖는 범주형의 경우 factor 함수 내부에 levels 인자를 넣어 정의하면 순서 정보가 유지된다.
범주형 자료의 경우 범주가 갖는 척도 가독성을 높이기 위해 levels() 함수를 사용하기도 한다.
통계 처리와 자료분석에 문자형 벡터와 요인 범주형 벡터를 다른 의미를 갖는 점에 유의한다. 동일한 summary() 함수지만 입력 자료형에 따라 R은 적절한 후속 작업을 자동으로 수행한다.
10.5 데이터프레임
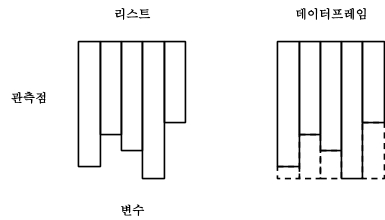
R은 6가지 기본 벡터로 자료를 저장하지만, 이외에 행렬(matrix), 데이터프레임(data.frame), 리스트(list) 자료구조가 있다. 하지만, 자료분석을 위해서 데이터를 데이터셋의 형태로 구성해야 한다. 데이터셋이 중요한 이유는 자료를 분석하기 위해서 다양한 형태의 개별 자료를 통합적으로 분석하기 위해서다. 이를 위해서 리스트 자료구조로 일단 모으게 된다. 예를 들어 개인 신용분석을 위해서는 개인의 소득, 부채, 성별, 학력 등등의 숫자형, 문자형, 요인(Factor)형 등의 자료를 데이터셋에 담아야 한다. 특히 변수와-관측값(Variable-Observation) 형식의 자료를 분석하기 위해서는 데이터프레임(data.frame)을 사용한다. 데이터프레임은 모든 변수에 대해서 관측값이 같은 길이를 갖도록 만들어 놓은 것이다.
데이터프레임은 data.frame() 함수를 사용해서 생성한다. R 객체 구조 파악을 위해서는 간단한 자료의 경우 데이터 형식을 확인할 수 있는 1–2줄 정도의 간단한 스크립트와 명령어를 통해서 확인이 가능하지만, 복잡한 데이터의 구조를 파악하기 위해서는 summary 함수와 str 함수를 통해서 확인해야 한다.
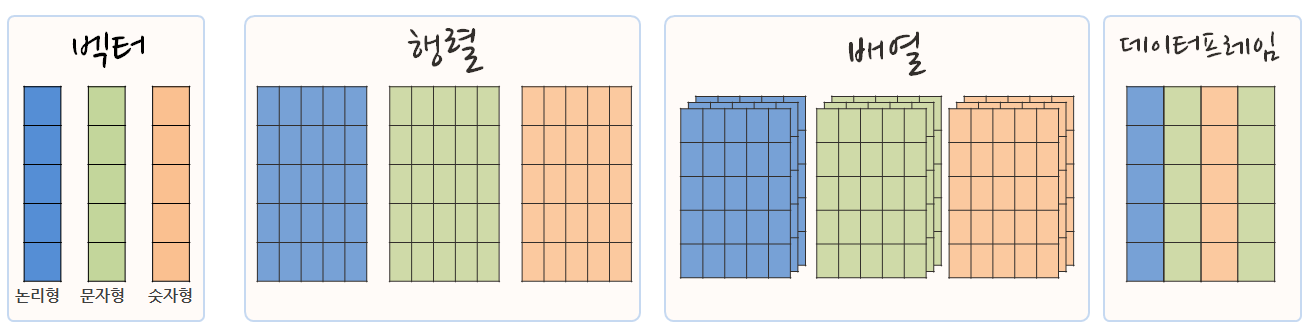
10.6 벡터, 행렬, 배열, 데이터프레임
가장 많이 사용되는 논리형, 문자형, 숫자형을 통해 자료분석 및 모형개발을 진행하게 되고, 경우에 따라서 동일한 자료형을 모은 경우 이를 행렬로 표현할 수 있고, 행렬을 모아 RGB 시각 데이터를 위한 배열(Array)로 표현한다. 데이터프레임은 서로 다른 자료형을 모아 넣은 것이다.
10.7 NULL과 NA
결측되었다는 없다는 것을 표시하는 방법이 두 가지 필요하다. 하나는 벡터가 없다는 NULL이고, 벡터 내부에 값이 결측되었다는 NA다. dataframe$variable <- NULL 명령문을 사용하면 데이터프레임(dataframe)에 변수(variable)를 날려보내는 효과가 있다. 예를 들어 책장이 아예 없다는 의미(NULL)와 책장에 책이 없다(NA)는 다른 개념을 지칭하고 쓰임새가 다르다.
NA의 중요한 특징은 전염된다는 것이다. 즉, NA에 연산을 가하면 연산 결과는 무조건 NA가 된다. NA가 7보다 큰지, 7을 더하고 빼고, 부울 연산을 하든 NA와 연산 결과는 무조건 NA가 된다.
NA + 7
#> [1] NA
NA / 7
#> [1] NA
NA > 7
#> [1] NA
7 == NA
#> [1] NA
NA == NA
#> [1] NA10.8 리스트 칼럼
레고를 통해 살펴본 R 자료구조는 계산 가능한 원자 자료형(논리형, 숫자형, 요인형)으로 크게 볼 수 있다. R에서 정수형과 부동소수점은 그다지 크게 구분을 하지 않는다. 동일 길이를 갖는 벡터를 쭉 붙여넣으면 자료구조형이 데이터프레임으로 되고, 길이가 같지 않는 벡터를 한 곳에 모아넣은 자료구조가 리스트다. 1 2
데이터프레임이 굳이 모두 원자벡터만을 갖출 필요는 없다. 리스트를 데이터프레임 내부에 갖는 것도 데이터프레임인데 굳이 구별하자면 티블(tibble)이고, 이런 자료구조를 리스트-칼럼(list-column)이라고 부른다.

의외로 리스트-칼럼 자료구조를 실무에서 빈번히 마주하게 된다. 정규표현식을 사용하여 텍스트 데이터에서 원하는 패턴을 추출하거나 변환할 수 있다. 추출된 결과는 주로 리스트 형태로 저장되며, 리스트-칼럼을 활용하면 텍스트 처리 결과를 데이터프레임에 직접 저장할 수 있어 편리하다. 웹 API를 통해 수집한 JSON이나 XML 형식의 데이터는 계층적 구조를 가지고 있어 리스트-칼럼을 사용하여 데이터프레임에 저장하면 복잡한 구조의 데이터를 분석에 용이한 형태로 환하기 수월하다.
분할-적용-병합(Split-Apply-Combine) 전략은 데이터를 그룹별로 나누어 각 그룹에 동일한 연산을 적용하고, 결과를 다시 병합하는 방법으로 그룹별 연산 결과는 리스트 형태로 저장되며, 리스트-칼럼을 사용하여 데이터프레임에 통합시킨 후 후속 작업을 이어나가는 패턴을 흔히 볼 수 있다.
이렇게 리스트-칼럼을 활용하여 데이터를 처리하고 분석하는 과정에서, 티블(tibble) 형태의 데이터프레임을 사용하면 데이터 탐색과 조작이 한결 수월해진다. 데이터프레임이 티블(tibble) 형태로 되어 있을 때, 데이터프레임 파악, 인덱싱, 연산, 간략화 등 다양한 작업을 수월하게 할 수 있다.
먼저, 들여다보기(Inspect) 측면에서 티블 형태 데이터프레임은 콘솔에 출력했을 때 깔끔하게 보여주므로, 데이터의 구조와 내용을 쉽게 파악할 수 있다. 또한, glimpse() 함수를 사용하면 데이터프레임 개요를 자료형과 함께 한 눈에 확인할 수 있다.
인덱싱(Indexing) 측면에서는 티블이 데이터프레임과 동일하게 [], [[]], $ 연산자를 사용하여 원소에 접근할 수 있어, 열 이름이나 위치를 사용하여 원하는 변수나 관측값을 추출할 수 있다.
연산(Compute) 측면에서도 리스트-칼럼을 포함한 티블에서 mutate(), summarise() 등의 함수를 사용하여 새로운 변수를 생성하거나 요약 통계량을 계산할 수 있으며, 이 과정에서 리스트-칼럼에 대한 연산도 자연스럽게 수행할 수 있다.
마지막으로 간략화(Simplify) 측면에서는 리스트-칼럼을 포함한 티블을 일반적인 데이터프레임으로 변환할 때, unnest() 함수를 사용할 수 있다. 이를 통해 리스트-칼럼의 각 요소를 개별 행으로 풀어내어, 분석에 더 용이한 형태로 만들 수 있다.
연습문제
객관식
- R에서 벡터 자료형을 주로 어떻게 분류하는가?
- 원자 벡터와 리스트
- 숫자형과 문자형
- 정수형과 실수형
- 행렬과 배열
- 데이터프레임에서 특정 변수를 제거하기 위해 사용하는 코드는?
- dataframe$variable == NULL
- dataframe$variable = NULL
- dataframe$variable <- NULL
- dataframe <- NULL
- 다음 중 리스트-칼럼 자료구조를 활용하기에 적합하지 않은 경우는?
- 정규표현식을 통한 텍스트 문자열 처리
- 웹 API로 추출된 JSON, XML 데이터
- 분할-적용-병합(Split-Apply-Combine) 전략
- 단순한 숫자형 벡터 저장
서술형
- 데이터프레임을 생성하는 함수의 이름과 사용 예시를 간단히 작성하시오.
- 리스트-칼럼 자료구조의 장점을 설명하고, 이를 분석에 활용하는 방법에 대해 서술하시오.