7 . 통계 / Statistics
7.1 요약 / Summaries
LInux 사례 (Ubuntu 18.04)
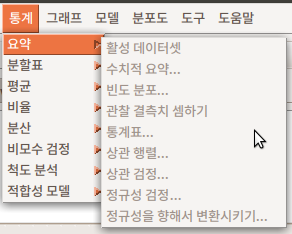
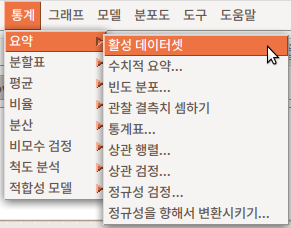
활성 데이터셋이 없는 경우, 통계 분석의 대상이 없기 때문에 하위 기능의 메뉴가 음영 처리되어 있다. 활성 데이터셋이 있는 경우 아래와 같이 음영 처리가 사라지고, 하위 기능을 선택할 수 있게 된다:
LInux 사례 (Ubuntu 18.04)
7.1.1 활성 데이터셋 / Active Data set
Linux 사례 (Ubuntu 18.04)
Prestige라는 데이터셋을 불러와서 자료처리와 분석용으로 활성화시켰다고 가정하자. Prestige 데이터셋의 요약정보를 보고자 할때, 기능을 선택한다:
## education.income.women.prestige.census.type
## accountants,12.77,9271,15.7,63.4,1171,prof : 1
## aircraft.repairmen,10.1,7716,0.78,50.3,8582,bc: 1
## aircraft.workers,8.78,6573,5.78,43.7,8515,bc : 1
## architects,15.44,14163,2.69,78.1,2141,prof : 1
## athletes,11.44,8206,8.13,54.1,3373,NA : 1
## auto.repairmen,8.1,5795,0.81,38.1,8581,bc : 1
## (Other) :96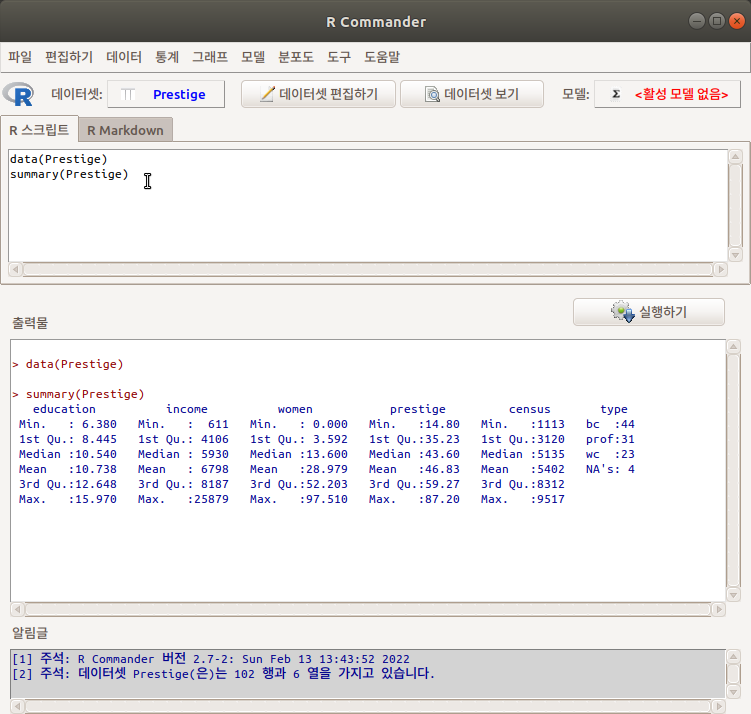
Linux 사례 (Ubuntu 18.04)
7.1.2 수치적 요약…/ Numeric summaries…
Linux 사례 (Ubuntu 18.04)
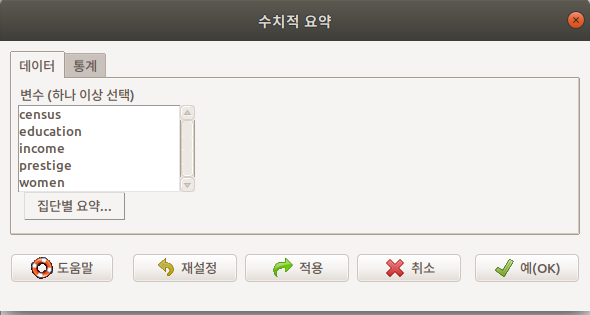
<수치적 요약…> 메뉴를 선택하면 하위 창이 나온다:
Linux 사례 (Ubuntu 18.04)
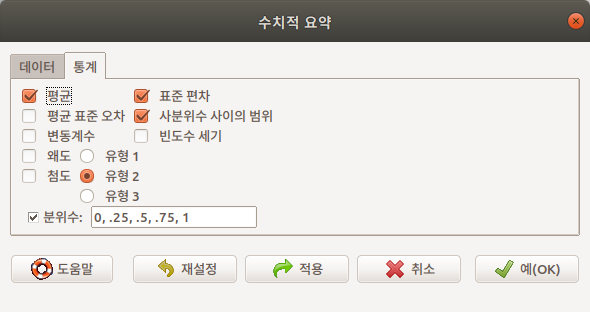
데이터 창과 통계 창이 있다. 통계 창을 보려면 데이터 옆에 있는 통계 창을 선택하면 된다:
Linux 사례 (Ubuntu 18.04)
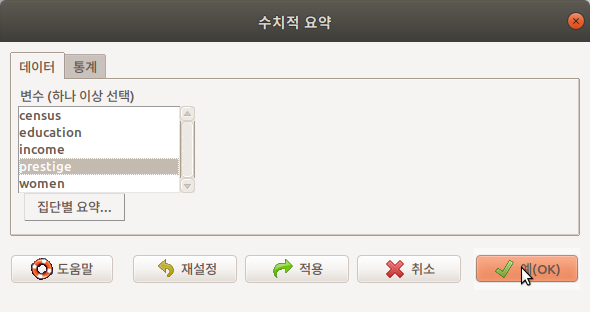
다시 데이터 창으로 와서 prestige 라는 변수의 수치적 요약 정보를 보고자 한다. prestige 변수를 선택하고, 오른쪽 아래의 예(OK) 버튼을 선택한다:
Linux 사례 (Ubuntu 18.04)
입력 창과 출력 창을 살펴보자. 통계 창의 선택사항들에 변경을 주지 않은 상태에서 Prestige 라는 데이터셋의 prestige 변수의 수치적 정보는 다음과 같다:
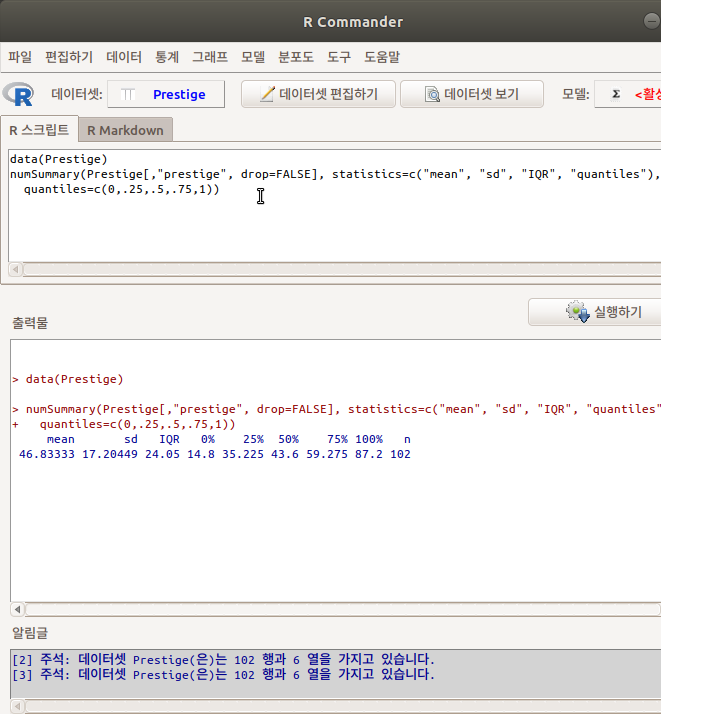
Linux 사례 (Ubuntu 18.04)
7.1.3 빈도 분포… / Frequency distributions…
Linux 사례 (Ubuntu 18.04)
Linux 사례 (Ubuntu 18.04)
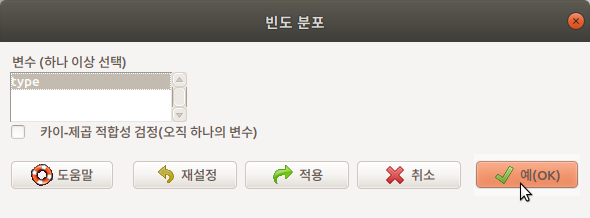
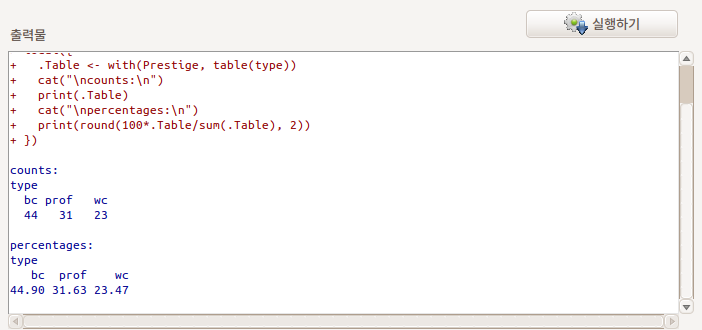
type 변수를 선택하고 예(OK)를 누른다. Prestige 데이터셋의 type 변수의 빈도를 보는 명령문이 다음과 같이 입력창에 기록되고 출력창에 빈도 정보가 출력된다:
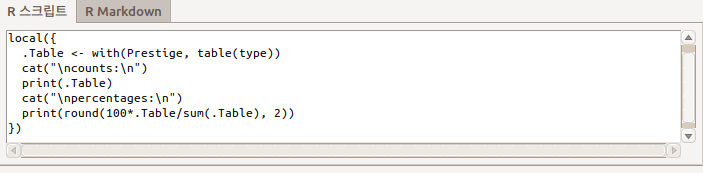
Linux 사례 (Ubuntu 18.04) - 입력 창 기록
Linux 사례 (Ubuntu 18.04) - 출력창 출력결과
Q1> Prestige의 변수는 여러개가 있습니다. 그중에서 왜 type만 선택 창에 나오나요?
type 변수는 factor 유형입니다. 빈도는 factor 유형의 변수만 셀 수 있기 때문입니다.
> str(Prestige) # Prestige 데이터셋의 변수 유형 살펴보기7.1.4 관측 결측치 셈하기 / Count missing observations
Linux 사례 (Ubuntu 18.04)
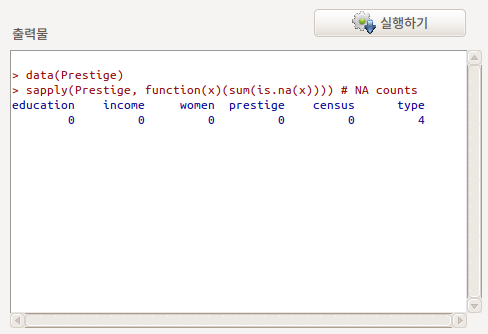
데이터셋을 구성하는 사례에 값이 입력되지 않은 결측치가 있는 경우가 있다. 어떤 변수에 관측값이 없는 결측치가 있는지를 확인할 때 사용하는 기능이다.
Linux 사례 (Ubuntu 18.04)
Prestige 데이터셋의 type 변수에 결측치가 4개가 있음을 확인한다.
7.1.5 통계표…/ Table of statistics…
Linux 사례 (Ubuntu 18.04)
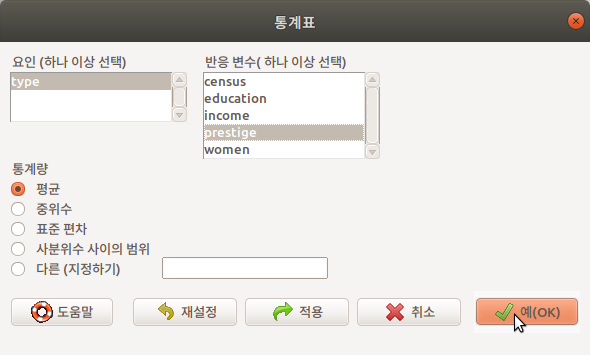
통계표(Table of statistics)는 요인(factor) 변수 유형별로 수치형(numeric, integer) 변수의 통계량을 계산하여 출력한다. Prestige 데이터셋에서 직업 유형의 type 변수를 요인에서 선택하고, 직업 유형별로 권위(prestige)의 통계량 중에서 기본 설정으로 선택된 평균값의 통계표를 선택하고, 예(OK) 버튼을 누른다.
Linux 사례 (Ubuntu 18.04)
Linux 사례 (Ubuntu 18.04)
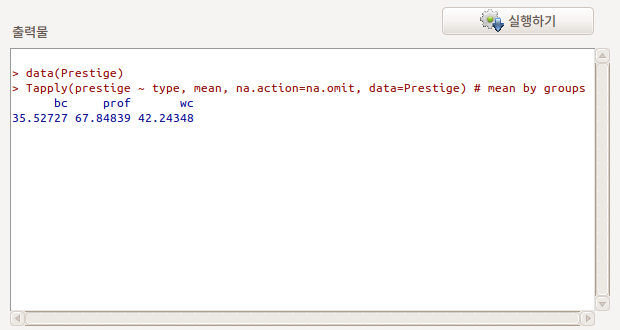
직업 유형(bc, prof, wc)별로 평균값을 계산하여 출력한다. 출력창을 보면 Tapply() 함수를 사용함을 알 수 있다.
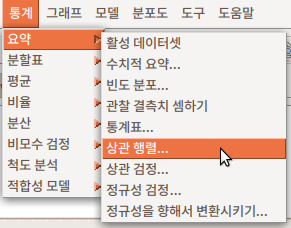
7.1.6 상관 행렬…/ Correlation matrix…
Linux 사례 (Ubuntu 18.04)
상관 행렬은 두개 이상의 변수를 선택해야 한다. Prestige 데이터셋에서 교육수준과 연봉(수입)의 관계에 대한 관심에서 이 두 변수를 선택하고, 예(OK) 버튼을 누른다.
Linux 사례 (Ubuntu 18.04)
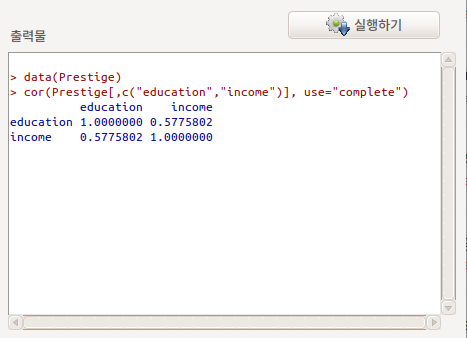
Linux 사례 (Ubuntu 18.04)
출력 창을 보면, cor() 함수가 사용되었음을 알 수 있다.
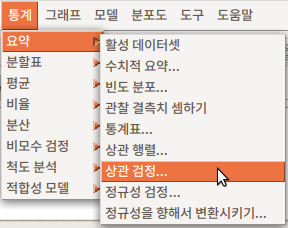
7.1.7 상관 검정…/ Correlation test…
Linux 사례 (Ubuntu 18.04)
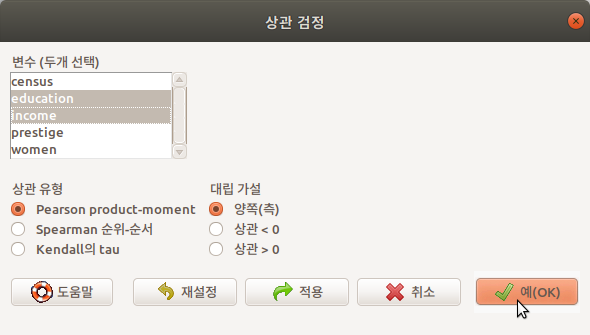
상관 검정은 두 변수를 구성하는 사례값들 사이에 어떤 방향의 관계성이 있는지를 통계학적으로 확인하고자 할 때 사용한다. 아래는Prestige 데이터셋에서 교육수준과 수입(연봉) 사이에 어떤 관계성이 있는지를 확인하고자 한다. education과 income 변수를 선택하고, 예(OK) 버튼을 누른다.
Linux 사례 (Ubuntu 18.04)
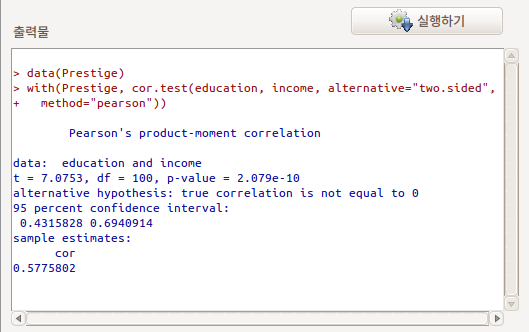
상관의 유형 중에서 Pearson product-moment (피어슨 적률상관), 대립 가설에는 양측이 기본으로 설정되어 있다. 이 설정을 바탕으로 상관 검증의 결과를 출력하면 아래와 같다:
Linux 사례 (Ubuntu 18.04)
cor.test() 함수를 활용한다.
7.1.8 정규성 검정…/ Test of normality…
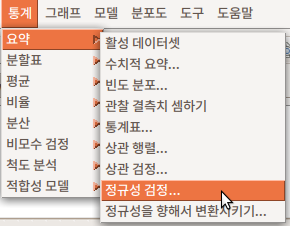
Linux 사례 (Ubuntu 18.04)
수치형(numeric, integer) 변수들 중에서 하나를 선택한다. 기본 설정에 Shapiro-Wilk의 정규성 검정법이 선택되어 있다. 수입(연봉)의 사례들이 정규 분포를 이루고 있는가를 확인하고자, 변수 income을 선택하고 예(OK) 버튼을 누른다.
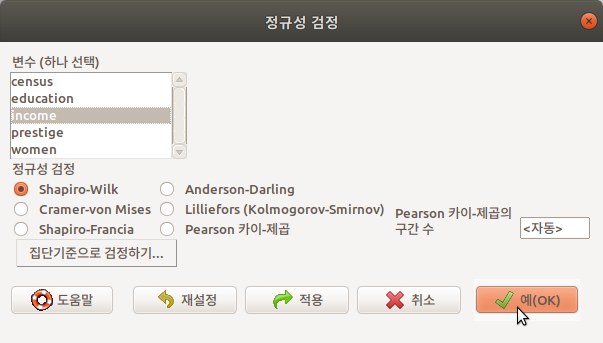
Linux 사례 (Ubuntu 18.04)
normalityTest()를 사용한다.
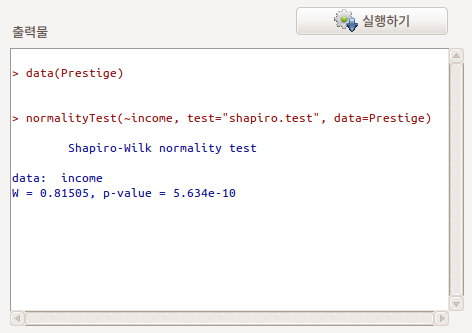
Linux 사례 (Ubuntu 18.04)
normalityTest(~education, test="shapiro.test", data=Prestige)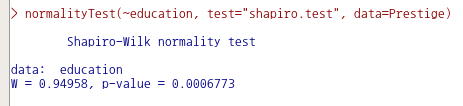
Linux 사례 (Ubuntu 18.04)
7.2 분할표 / Contingency tables
7.2.1 분할표 / Contingency tables
Linux 사례 (MX 21)
분석대상인 데이터셋에 요인형 변수가 한개 있거나, 하나도 없는 경우 분할표 메뉴의 오른쪽에 있는 , 기능은 불활성 음영 표시로 나타난다. 두개 이상의 요인형 변수가 있는 경우, 예를 들어 car 패키지에 포함된 Moore 데이터셋이 활성 데이터셋이 되는 경우 불활성 음영 표시가 사라진다.
Linux 사례 (MX 21)
요인형 변수가 세개 이상 있는 경우, 까지 활성화된다. 아래의 화면을 보면, partner.status, fcatetory 두개의 변수가 요인(factor)형이다. 는 활성화된 반면에, 기능이 아직 활성화되지 않았다면, 요인형 변수가 두개 뿐인 데이터셋임을 간접적으로 알려준다.
Linux 사례 (MX 21)
7.2.2 이원표…/ Two-way table
Linux 사례 (MX 21)
두개 이상의 요인형 변수를 가지고 있는 Moore 데이터셋을 활성화시키면, 의 음영이 사라지고 사용할 수 있는 기능이 된다.
Linux 사례 (MX 21)
행 변수와 열 변수에 요인형 변수 하나씩을 선택한다.
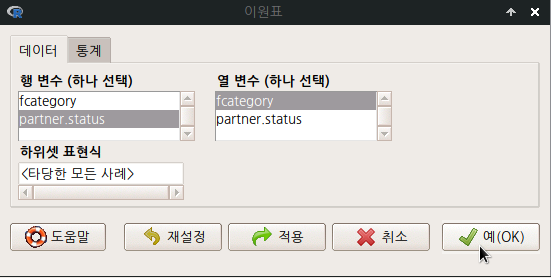
Linux 사례 (MX 21)
Linux 사례 (MX 21)
데이터 창과 함께 통계 창이 있다. 통계 창을 선택하면 다음과 같은 화면에 다양한 선택 기능을 선택할 수 있다. 다른 선택으로 출력 내용의 변화를 주지 않을 경우, 데이터 창으로 돌아가서 예(OK) 버튼을 누른다.
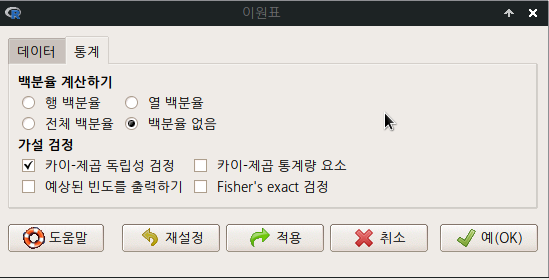
Linux 사례 (MX 21)
다음과 같은 출력물을 볼 수 있다. 행 변수에 partner.status, 열 변수에 fcategory를 선택한 경우의 출력물이다.
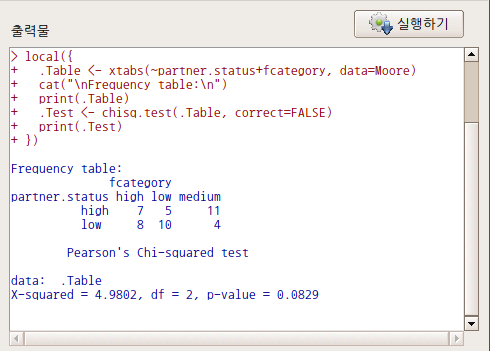
Linux 사례 (MX 21)
행 변수에 fcategory, 열 변수에 partner.status를 선택한 경우의 출력물이다.
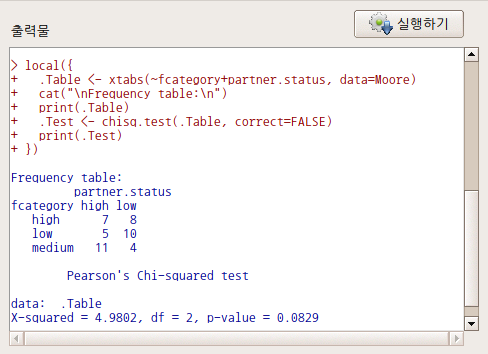
Linux 사례 (MX 21)
프롬프트의 입력 스크립트를 살펴보면, xtabs() 함수를 사용하는 것이 보인다.
7.3 평균 / Means
7.3.1 일-표본 t-검정… / Single-sample t-test…
Linux 사례 (MX 21)
datasets 패키지에 있는 sleep 데이터셋을 활용해보자.
<일-표본 t-검정…> 기능을 선택하면, 아래와 같은 선택 창으로 넘어간다.
sleep 데이터셋에서 일-표본 t-검정으로 점검할 수 있는 변수는 extra 하나가 보인다. 예(OK) 버튼을 누르자.
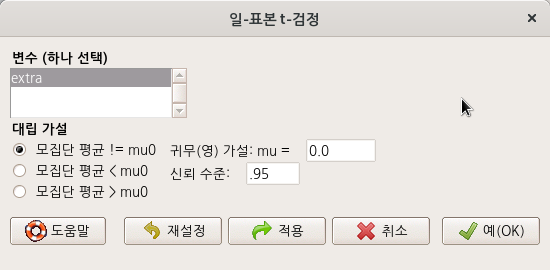
Linux 사례 (MX 21)
에 관련된 선택사항에 변화를 주지 않았다. 아래 명령문과 같은 결과를 얻는다.
t.test(extra ~ 1, data = sleep)
Linux 사례 (MX 21)
7.3.2 독립 표본 t-검정…/ Independent samples t-test…
Linux 사례 (MX 21)
datasets 패키지에 있는 sleep 데이터셋을 활용해보자. 활성화시키자.
sleep 데이터셋의 수치형 변수 extra에 대하여 2개의 수준을 가진 요인형 집단인 group 변수의 t-검정을 한다.
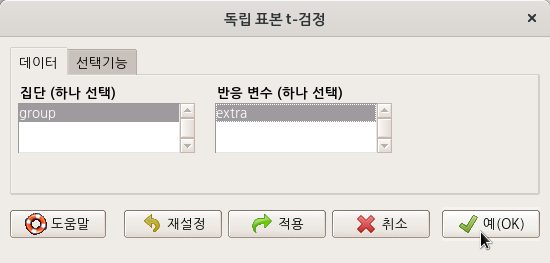
Linux 사례 (MX 21)
창에는 1그룹과 2그룹의 차이를 비교하는 , , 의 선택 사항이 있다. 일단 기본 선택 들을 사용하자.
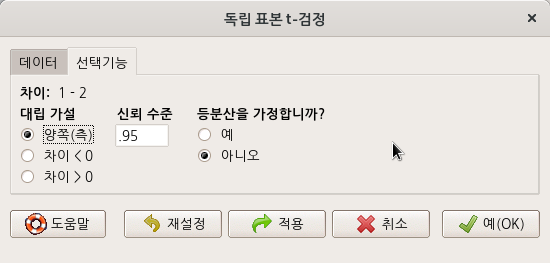
Linux 사례 (MX 21)
t.test(extra~group, alternative=‘two.sided’, conf.level=.95, var.equal=FALSE, data=sleep) alternative 이하의 선택 사항들은 기본 설정을 사용하였기에 다음과 같은 결과를 갖는다.
t.test(extra ~ group, data = sleep)
Linux 사례 (MX 21)
참고로 group1 과 group2의 사례들을 상자그림(boxplot)을 이용하여 비교해보자.
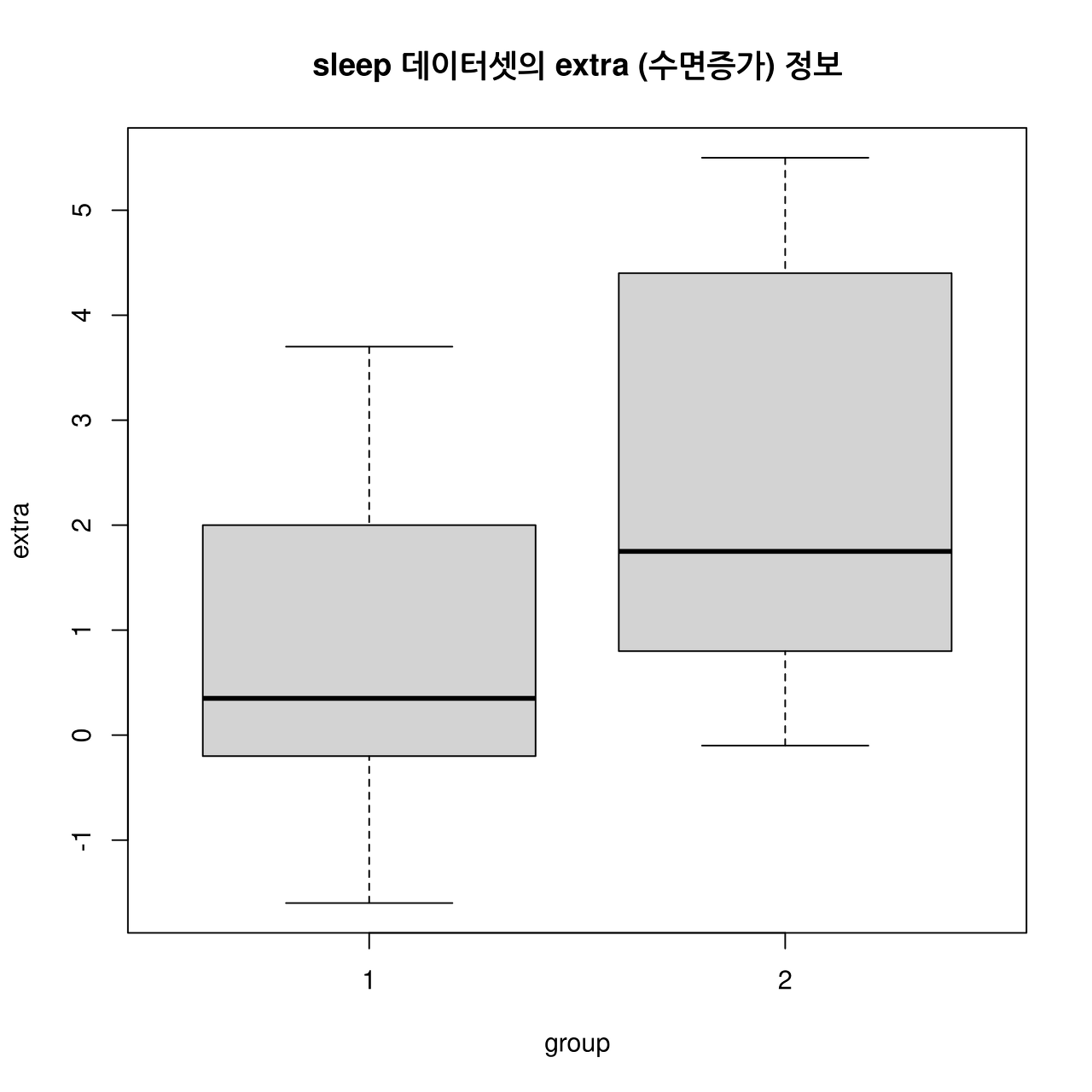
Linux 사례 (MX 21)
한편, 비교하는 두 집단의 분산의 차이가 없다는 것을 먼저 확인한 경우에 진행하는 t-검정도 있을 수 있다. 통계 > 분산 > 이-분산 F-검정의 결과를 바탕으로 독립-표본 t-검정을 진행하는 사례이다.
창에서 <등분산을 가정합니까?>에 ’예’를 선택한다.
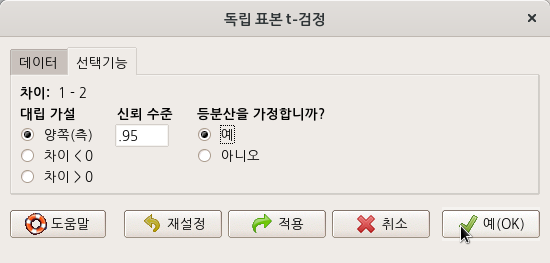
Linux 사례 (MX 21)
t.test(extra~group, alternative='two.sided',
conf.level=.95, var.equal=TRUE, data=sleep)
Linux 사례 (MX 21)
7.3.3 Paired t-검정…/ Paired t-test…
Linux 사례 (MX 21)
datasets 패키지에 포함된 sleep 데이터셋에는 extra라는 수치형 변수가 포함되어 있다. 수치형 변수가 하나만 있는 경우는 Paired t-검정을 사용할 수 없다. 10명이 각각 2개의 약을 복용한 후 group1, group2라는 집단 안에서 수면 시간의 변화를 측정한 데이터셋이다. reshape(), reshapeL2W() 등의 함수를 사용하여 extra라는 수치형 변수를 group1 , group2 별로 두개의 수치형 변수로 변환시켜야 한다. 변환이 되면 <Statistics : Means : Paired t-test> 기능이 활성화된다.
Linux 사례 (MX 21)
extra 변수를 두개의 집단 X1, X2 로 이미 나눈 상황이다. X1과 X2를 각각 와 에 선택하자.
Linux 사례 (MX 21)
창 추가 선택 사항들이 있다. 기본 선택을 이용하자.
Linux 사례 (MX 21)
아래의 함수 사용과 같은 결과를 얻는다.

Linux 사례 (MX 21)
7.3.4 일원 분산 분석…/ One-way ANOVA…
Linux 사례 (MX 21)
datasets 패키지에 있는 sleep 데이터셋을 활용해보자.
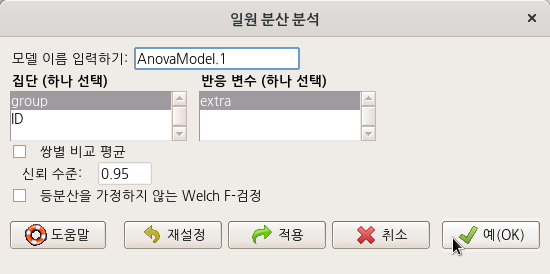
<집단 (하나 선택)>에 요인형 변수 group을, <반응 변수 (하나 선택)>에 수치형 변수 extra를 선택한다. 통계 > 분산 > 이-분산 F-검정을 통하여 비교되는 두 집단의 extra 변수의 사례 분포는 등분산임을 알고 있는 상황이다.
Linux 사례 (MX 21)
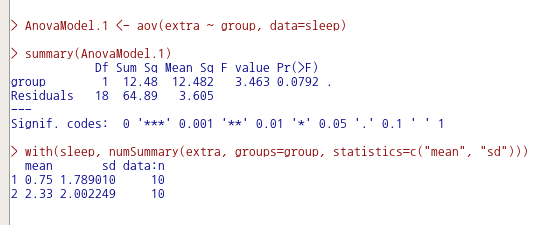
AnovaModel.1 <- aov(extra ~ group, data=sleep)
summary(AnovaModel.1)
with(sleep, numSummary(extra, groups=group, statistics=c("mean", "sd")))일원 분산 분석의 명령문 작성과 분석 결과는 아래와 같다.
Linux 사례 (MX 21)
추가로 carData 패키지의 Prestige 데이터셋을 이용하여 일원 분산 분석을 연습해보자. Prestige 데이터셋에는 type 이라는 요인형 변수가 있다. 그러나 앞서 연습한 sleep 데이터셋의 group 변수처럼 요인 수준이 두개가 아니라 요인의 수준이 셋이다. 직업의 사회적 권위에 대한 직업 유형별 (bc, prof, wc) 평균의 차이가 있는가를 점검한다.
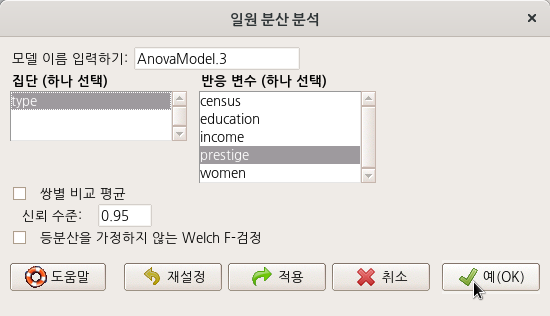
Linux 사례 (MX 21)
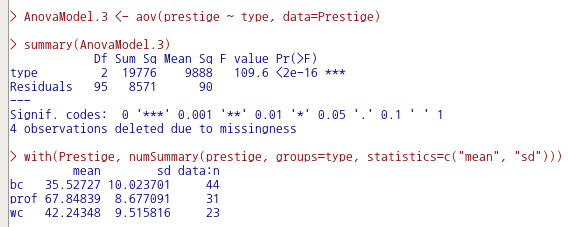
AnovaModel.3 <- aov(prestige ~ type, data=Prestige)
summary(AnovaModel.3)
with(Prestige, numSummary(prestige, groups=type, statistics=c("mean", "sd")))직업유형 (bc, prof, wc)에 따른 직업의 사회적 권위는, 각 유형별 평균을 비교할 때, 차이가 있다는 결과를 얻는다.
Linux 사례 (MX 21)
7.3.5 다원 분산 분석…/ Multi-way ANOVA…
Linux 사례 (MX 21)
다중 분산 분석 (Multi-way ANOVA)은 두개 이상의 요인형 변수들의 작용으로 하나의 수치형 변수에 영향을 주었는가를 점검하는 통계기법이다.
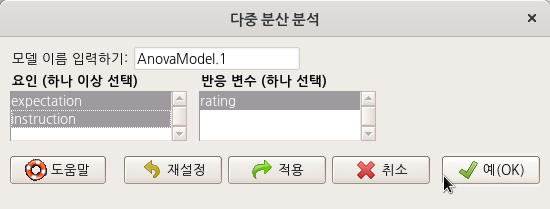
Linux 사례 (MX 21)
data(Adler, package="carData")
help("Adler", package="carData")
AnovaModel.1 <- lm(rating ~ expectation*instruction, data=Adler, contrasts=list(expectation
="contr.Sum", instruction ="contr.Sum"))
Anova(AnovaModel.1)
Tapply(rating ~ expectation + instruction, mean, na.action=na.omit, data=Adler) # means
Tapply(rating ~ expectation + instruction, sd, na.action=na.omit, data=Adler) # std. deviations
xtabs(~ expectation + instruction, data=Adler) # counts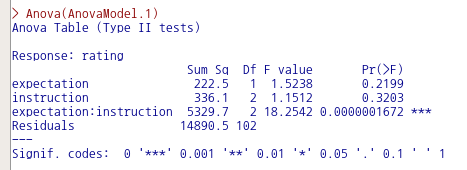
Linux 사례 (MX 21)
7.4 비율 / Proportions
7.4.1 일-표본 비율 검정…/ Single-sample proportion test…
Linux 사례 (MX 21)
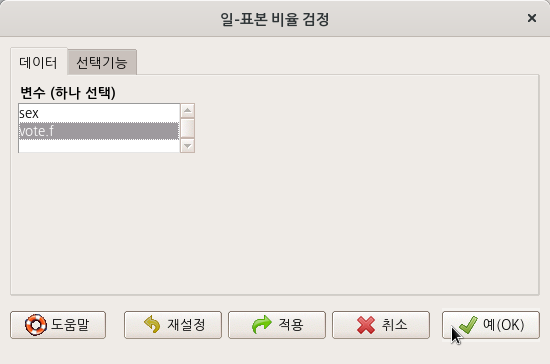
carData 패키지에 있는 Chile 데이터셋을 활용한다. 요인형 변수 vote를 변형시켜 vote.f 변수를 새롭게 코딩하고 사용하도록 하자.
data(Chile, package="carData")
Chile <- within(Chile, {
vote.f <- Recode(vote, '"Y" = "yes"; "N" = "no"; else = NA', as.factor=TRUE)
})
Linux 사례 (MX 21)
창에 표시되어 있는 기본 설정을 그대로 사용하자.
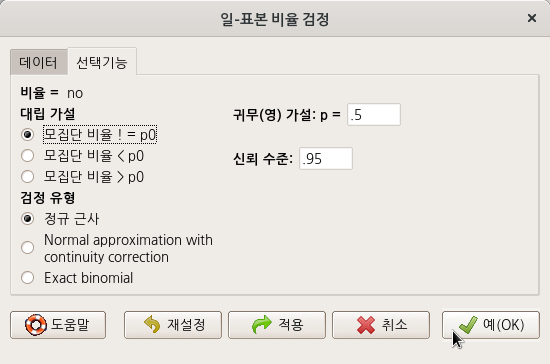
Linux 사례 (MX 21)
local({
.Table <- xtabs(~ vote.f , data= Chile )
cat("\nFrequency counts (test is for first level):\n")
print(.Table)
prop.test(rbind(.Table), alternative='two.sided', p=.5, conf.level=.95, correct=FALSE)
})출력창에 나오는 결과는 아래와 같다:

Linux 사례 (MX 21)
7.5 분산 / Variance
7.5.1 이-분산 F-검정…/ Two variances F-test…
Linux 사례 (MX 21)
datasets 패키지에 포함된 sleep 데이터셋을 활용해보자.
메뉴창에서 요인형 변수 group을 <집단 (하나 선택)>에, 수치형 변수 extra를 <반응 변수 (하나 선택)>으로 결정하자. Two variances F-test (이-분산 F-검정)은 두 개의 집단 비교로 반응 변수의 분산을 점검하는 기법이다.
Linux 사례 (MX 21)
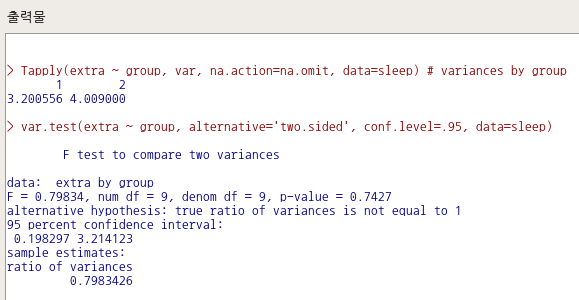
Tapply(extra ~ group, var, na.action=na.omit, data=sleep) # variances by group
var.test(extra ~ group, alternative='two.sided', conf.level=.95, data=sleep)alternative 이후 선택 사항들은 기본 선택을 사용하였다. 변화를 준 것은 없다. 따라서 아래의 명령문과 같은 의미이기도 하다.
var.test(extra ~ group, data=sleep)sleep 데이터셋에 있는 extra 변수의 요인 수준 (group1, group2)별 분산은 차이가 있다고 통계적으로 말하기 어렵다는 결론을 얻는다. 줄여서 거칠게 말하면, 두 분산의 차이가 없다고 할 수 있다.
Linux 사례 (MX 21)
7.5.2 Bartlett의 검정…/ Bartlett’s test…
Linux 사례 (MX 21)
carData 패키지에서 제공하는 Prestige 데이터셋을 활성화 시키자. Prestige 데이터셋에는 type 이라는 세개의 수준을 가진 요인형 변수가 있다. 그 수준 이름은 bc, prof, wc 이다. 직업유형(type)별로 사회적인 권위가 다른지를 확인하는 문제의식이 있다고 하자. 집단별(직업유형, type)로 직업의 사회적 권위(prestige)에 대한 분산의 차이가 있는지를 통계적으로 살펴본다.
Linux 사례 (MX 21)
Tapply(prestige ~ type, var, na.action=na.omit, data=Prestige) # variances by group
bartlett.test(prestige ~ type, data=Prestige)
Linux 사례 (MX 21)
7.5.3 Levene의 검정…/ Levene’s test…
Linux 사례 (MX 21)
carData 패키지에서 제공하는 Prestige 데이터셋을 활성화 시키자. Prestige 데이터셋에는 type 이라는 세개의 수준을 가진 요인형 변수가 있다. 그 수준 이름은 bc, prof, wc 이다. 직업유형(type)별로 사회적인 권위가 다른지를 확인하는 문제의식이 있다고 하자. 집단별(직업유형, type)로 직업의 사회적 권위(prestige)에 대한 분산의 차이가 있는지를 통계적으로 살펴본다. <중앙(센터)>에서 중앙값과 평균을 선택할 수 있다. 중앙값이 기본 설정이다.
Linux 사례 (MX 21)
Tapply(prestige ~ type, var, na.action=na.omit, data=Prestige) # variances by group
leveneTest(prestige ~ type, data=Prestige, center="median")
Linux 사례 (MX 21)
7.6 비모수 검정 / Nonparametric tests
7.6.1 이-표본 Wilcoxon 검정…/ Two-sample Wilcoxon test…
Windows 사례 (10 Pro)
‘통계 > 비모수 검정 > 이-표본 Wilcoxon 검정…’ 기능을 이용하기 위해서 데이터셋을 선택하고, 정비해보자. datasets 패키지에 있는 airquality 데이터셋을 선택하고, 그 안에 있는 변수 Month 사례 값들 중에서 5월, 8월에 해당하는 5, 8을 선택한 하위 데이터셋을 만들고, airquality.sub라 이름 붙이자. 그리고, 5, 8을 요인화 시켜서, May, August라고 수준을 만들자.
data(airquality, package="datasets") # airquality 데이터셋 불러오기
airquality.sub <- subset(airquality, subset=Month %in% c(5, 8))
# 5월, 8월만 포함하는 하위셋 만들기
summary(airquality.sub)
airquality.sub <- within(airquality.sub, {
Month.f <- factor(Month, labels=c('May','August'))
}) # Month.f라는 요인형 변수 만들기집단 변수인 Month.f는 두개의 수준을 갖고 있고, 이 두개의 수준을 기준으로 Ozone을 비교하는 것이다.
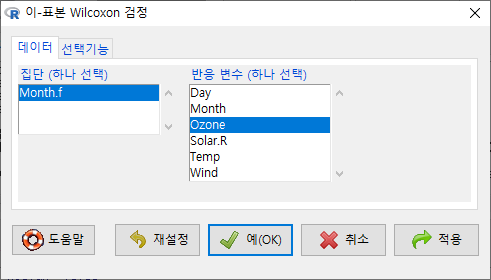
Windows 사례 (10 Pro)
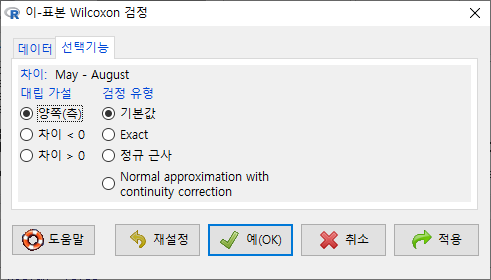
창에 있는 기본 설정을 우선 그대로 사용해보자. 향후 데이터셋과 변수에 대한 이해력이 높아지면, 다양한 선택을 할 수 있다.
Windows 사례 (10 Pro)
Tapply(Ozone ~ Month.f, median, na.action=na.omit, data=airquality.sub)
# medians by group
wilcox.test(Ozone ~ Month.f, alternative="two.sided", data=airquality.sub)
Windows 사례 (10 Pro)
7.6.2 일-표본 Wilcoxon 검정…/ Single-sample Wilcoxon test…
Windows 사례 (10 Pro)
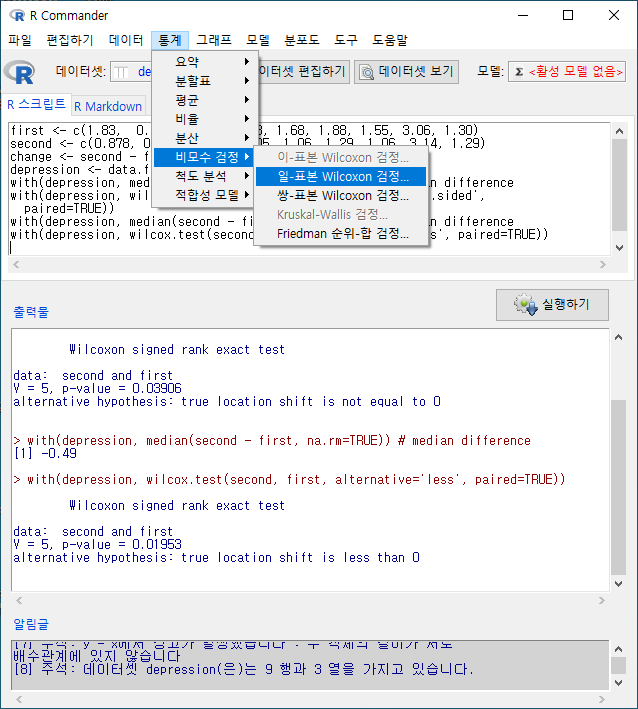
먼저 ’통계 > 비모수 검정 > 쌍-표본 Wilcoxon 검정…’을 살펴보는 것을 추천한다. depression 이라는 데이터셋을 만들고, 변수 first, second, change를 만들었다. change는 second와 first의 차이에 관련 사례 값을 갖는다.
참고: Paired-samples Wilcoxon test…
’통계 > 비모수 검정 > 일-표본 Wilcoxon 검정…’은 depression 데이터셋의 change 변수처럼 두 개 변수의 차이를 갖는 (또는 차이가 계산된) 변수를 기준값과 비교하여 차이 검정을 하는 기법이다. 때로는 특정 변수와 기준 값의 비교를 통하여 검정을 하기도 한다.
Windows 사례 (10 Pro)
데이터셋과 변수에 대한 의미적 판단이 깊은 경우 의 선택을 다양하게 결정할 수 있다. 아래 화면에서 ’mu < 0’은 change가 귀무(영) 가설, mu=0.0 일 때 depression 의 변화가 작아졌음을 확인하는 것으로 이해할 수 있다.
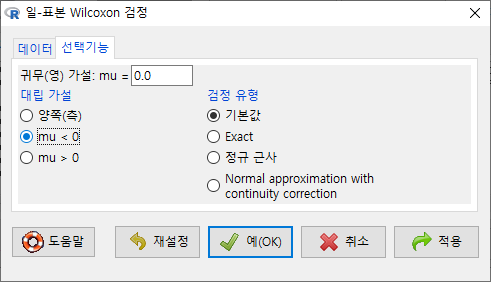
Windows 사례 (10 Pro)
with(depression, median(change, na.rm=TRUE))
with(depression, mean(change, na.rm=TRUE))
with(depression, wilcox.test(change, alternative='less', mu=0.0))출력 창에 아래와 같이 검정의 통계적 정보가 제공된다:

Windows 사례 (10 Pro)
7.6.3 쌍-표본 Wilcoxon test…/ Paired-samples Wilcoxon test…
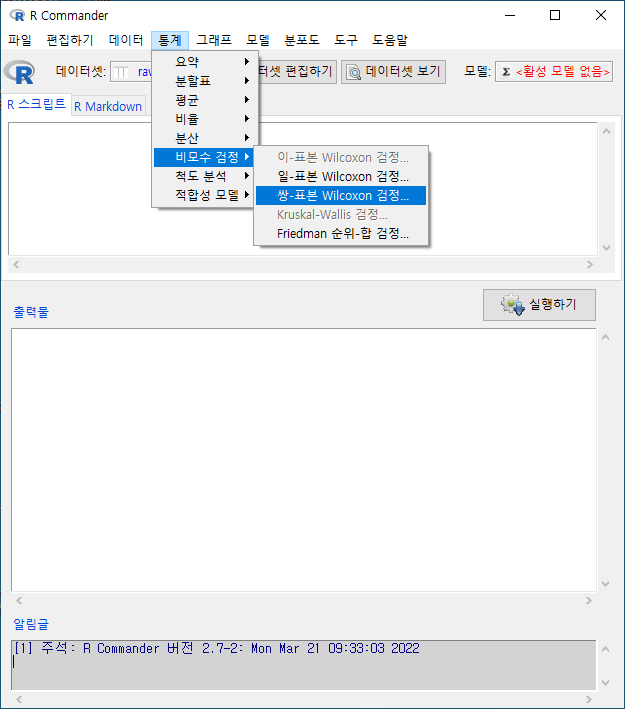
Windows 사례 (10 Pro)
depression 이라는 이름의 데이터셋을 만들자. first, second, change 라는 세개의 변수를 갖는다고 하자. change 변수는 second와 first의 차이를 사례 값으로 갖는다고 하자. 아래와 같을 것이다.
first <- c(1.83, 0.50, 1.62, 2.48, 1.68, 1.88, 1.55, 3.06, 1.30)
second <- c(0.878, 0.647, 0.598, 2.05, 1.06, 1.29, 1.06, 3.14, 1.29)
change <- second - first # compute new variable 참조할 것
depression <- data.frame(cbind(first, second, change)) # 세개의 vector를 묶어 데이터프레임으로 전환
Windows 사례 (10 Pro)
창에 있는 기본 선택 사양을 그대로 사용해보자. 에서 ’양쪽(측)’이 선택되어 있다. depression 데이터셋의 second 변수와 first 변수 사이에 순위 차이가 있는가를 살펴보는 것이라 할 수 있다.
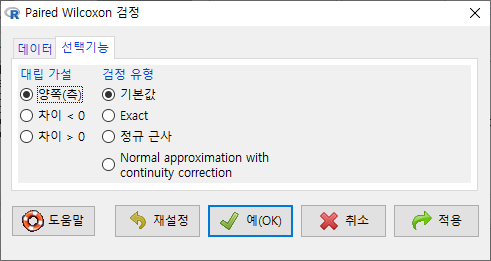
Windows 사례 (10 Pro)
with(depression, median(second - first, na.rm=TRUE)) # median difference
with(depression, wilcox.test(second, first, alternative='two.sided',
paired=TRUE)) # 양측 검정
with(depression, wilcox.test(second, first, alternative='less', paired=TRUE))
# 단측 검정 ( 차이 < 0 )
Windows 사례 (10 Pro)
창에서 에 ’차이 < 0’를 선택하자. second 변수의 사례 값이 first 변수의 사례 값보다 작아졌는지를 점검하는 것이다. (depression이 작아졌다는 것은 개선되었다는 의미로 해석될 수도 있다.)
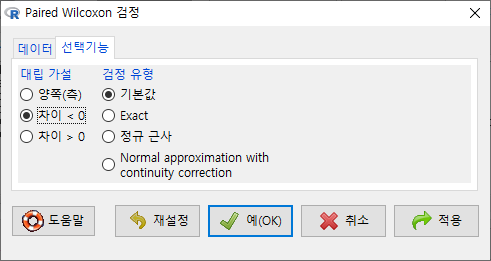
Windows 사례 (10 Pro)

Windows 사례 (10 Pro)
7.6.4 Kruskal-Wallis 검정…/ Kruskal-Wallis test…
Linux 사례 (MX 21)
carData 패키지에 있는 Friendly 데이터셋을 활용한다.
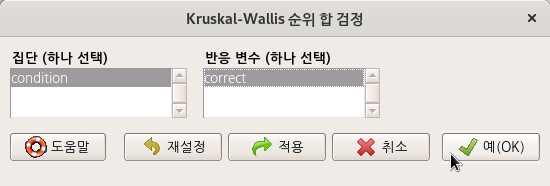
Linux 사례 (MX 21)
data(Friendly, package="carData")
Tapply(correct ~ condition, median, na.action=na.omit, data=Friendly) # medians by group
kruskal.test(correct ~ condition, data=Friendly)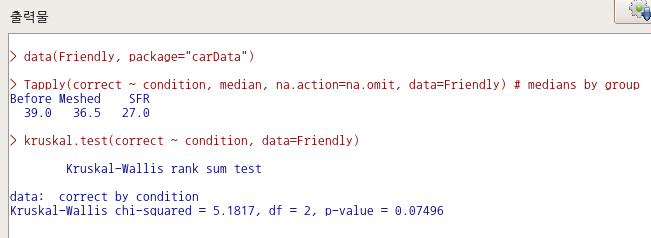
Linux 사례 (MX 21)
7.6.5 Friedman 순위-합 검정…/ Friedman rank-sum test…
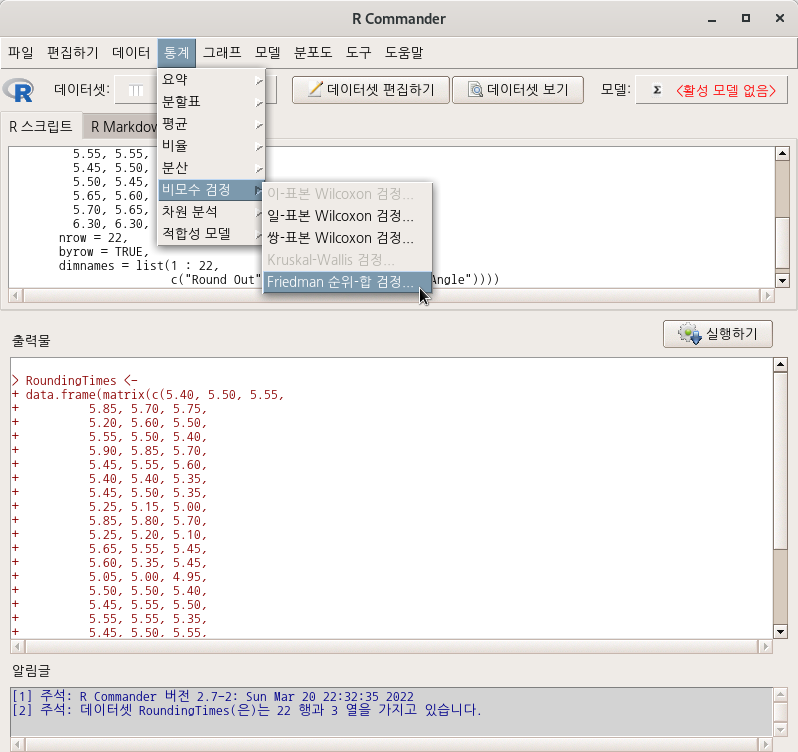
Linux 사례 (MX 21)
<Friendman 순위-합 검정…> 기능은 두개 이상의 수치형 변수가 데이터셋에 포함되어 있을때 활성화된다. <Friedman 순위-합 검정…> 기능의 함수적 특징을 이해하기 위하여 먼저 아래와 같이 RoundingTimes라는 데이터셋을 만들어보자.
RoundingTimes <-
data.frame(matrix(c(5.40, 5.50, 5.55,
5.85, 5.70, 5.75,
5.20, 5.60, 5.50,
5.55, 5.50, 5.40,
5.90, 5.85, 5.70,
5.45, 5.55, 5.60,
5.40, 5.40, 5.35,
5.45, 5.50, 5.35,
5.25, 5.15, 5.00,
5.85, 5.80, 5.70,
5.25, 5.20, 5.10,
5.65, 5.55, 5.45,
5.60, 5.35, 5.45,
5.05, 5.00, 4.95,
5.50, 5.50, 5.40,
5.45, 5.55, 5.50,
5.55, 5.55, 5.35,
5.45, 5.50, 5.55,
5.50, 5.45, 5.25,
5.65, 5.60, 5.40,
5.70, 5.65, 5.55,
6.30, 6.30, 6.25),
nrow = 22,
byrow = TRUE,
dimnames = list(1 : 22,
c("Round Out", "Narrow Angle", "Wide Angle"))))
summary(RoundingTimes) # RoundingTimes 데이터셋 보기이 데이터셋을 만드는 이유는 friedman.test()라는 함수의 예제 연습에 포함되어있기 때문이다. RoundingTimes 데이터셋은 아래와 같은 내부 구성을 갖는다:
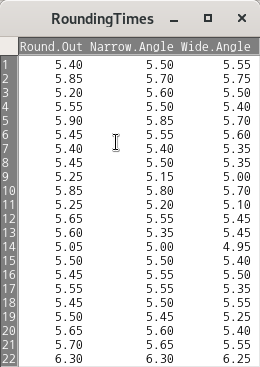
Linux 사례 (MX 21)
RoungdingTimes 라는 데이터셋을 만들고, 화면 맨 위에 있는 <Friedman 순위-합 검정…> 기능을 선택하면 추가적인 선택 메뉴 창으로 넘어간다.
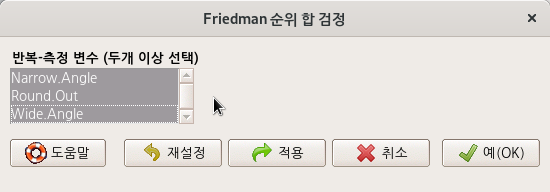
Linux 사례 (MX 21)
local({
.Responses <- na.omit(with(RoundingTimes, cbind(Narrow.Angle, Round.Out, Wide.Angle)))
cat("\nMedians:\n")
print(apply(.Responses, 2, median))
friedman.test(.Responses)
})
Linux 사례 (MX 21)
7.7 차원 분석 / Dimensional analysis
7.7.1 군집 분석 > k-평균 군집 분석…/ Cluster analysis > k-means cluster analysis…
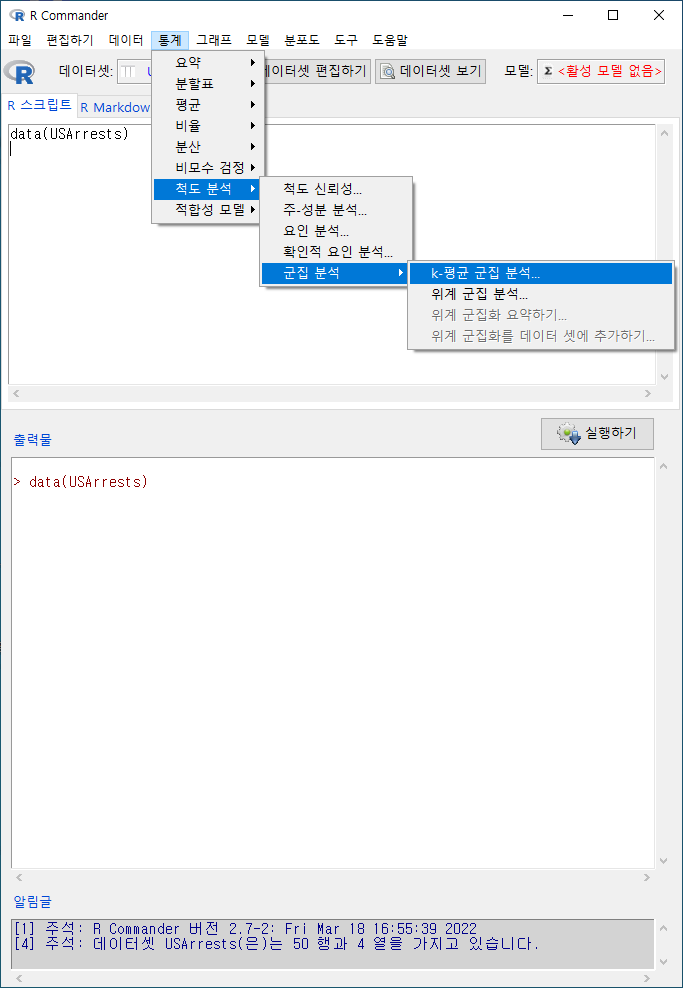
Windows 사례 (10 Pro)
datasets 패키지에서 제공하는 USArrests 데이터셋을 이용해보자.
데이터셋에 포함된 네개의 변수를 모두 선택한다.
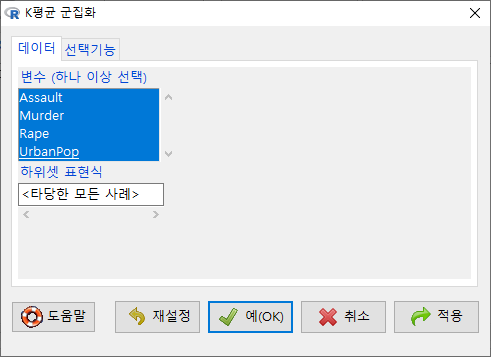
Windows 사례 (10 Pro)
창에서, 군집의 수를 3개, 초기값의 수를 5번으로, 최대 반복 횟수를 5회로 정해보자. 데이터셋에 추가될 변수 이름이 KMeans가 될 것이다. 아래 있는 선택사항에서 데이터셋에 군집 할당하기를 선택한다.
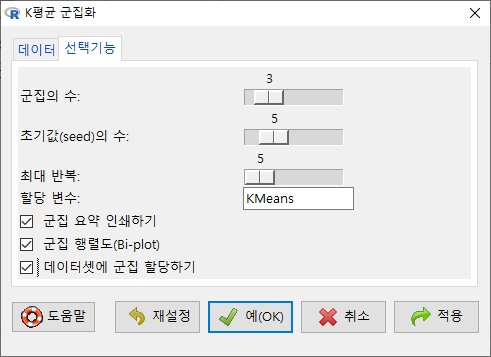
Windows 사례 (10 Pro)
위 화면에서 선택된 군집 행렬도(Bi-plot)이 아래와 같이 생산된다.
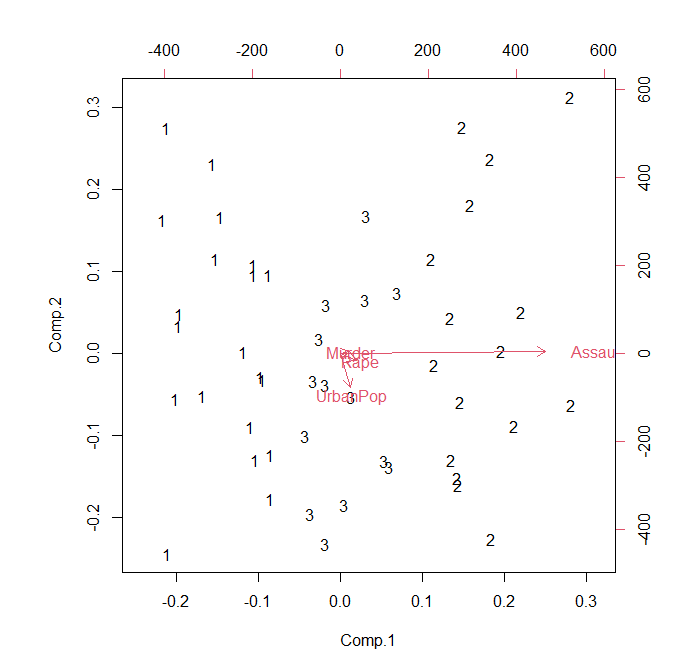
Windows 사례 (10 Pro)
USArrests 데이터셋에 변수 KMeans가 추가될 것이다. R Commander 상단에 있는 버튼을 눌러보자. KMeans 변수는 요인형으로 1, 2, 3 이라는 세개의 군집을 표시한다.
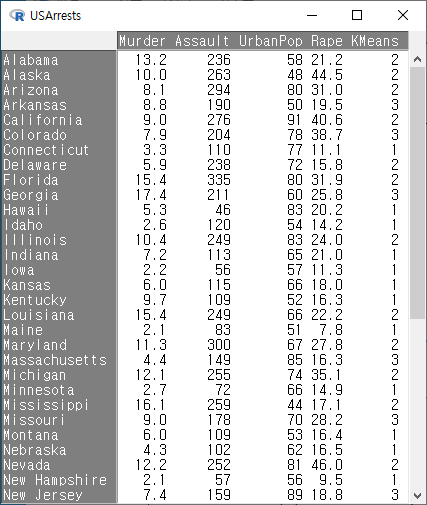
Windows 사례 (10 Pro)
아래 화면은 다소 복잡해보일 것이다. 그러나 객체 .cluster가 만들어졌으며, 그 객체안에 있는 $size, $withinss, $tot.withinss, $betweenss 등의 정보를 차례를 보여준다고 생각하자. 그리고 biplot을 생산하고, USArrests 데이터셋에 KMeans라는 변수를 추가하는 것이다.
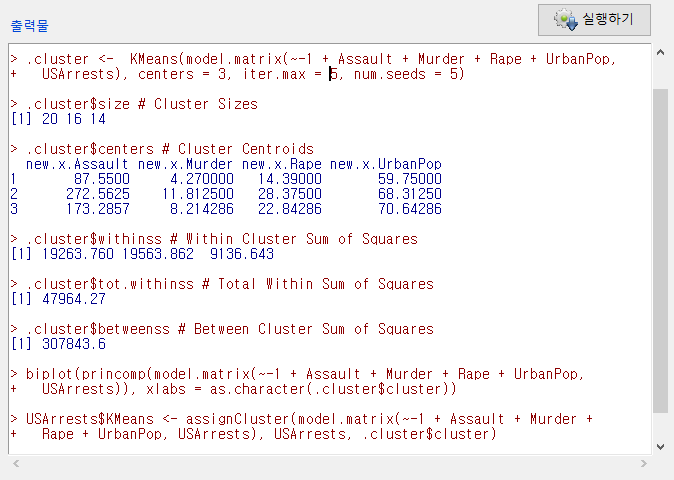
Windows 사례 (10 Pro)
7.7.2 군집 분석 > 위계 군집 분석…/ Cluster analysis > Hierarchical cluster analysis…
Linux 사례 (MX 21)
datasets 패키지에 있는 USArrests 데이터셋을 활용해서, 위계 군집 분석을 연습해보자. 우선 USArrests 데이터셋을 활성화시킨다.
창에서 아래와 같이 변수 네개를 모두 선택한다. 그리고, 기본으로 추천되는 HClust.1를 군집화 이름으로 사용하자.
Linux 사례 (MX 21)
창에서 기본설정된 사항들을 그대로 사용해보자. , , 등을 살펴본다.
Linux 사례 (MX 21)
예(OK) 버튼을 누르면, 아래와 같은 그래픽 창이 등장한다.
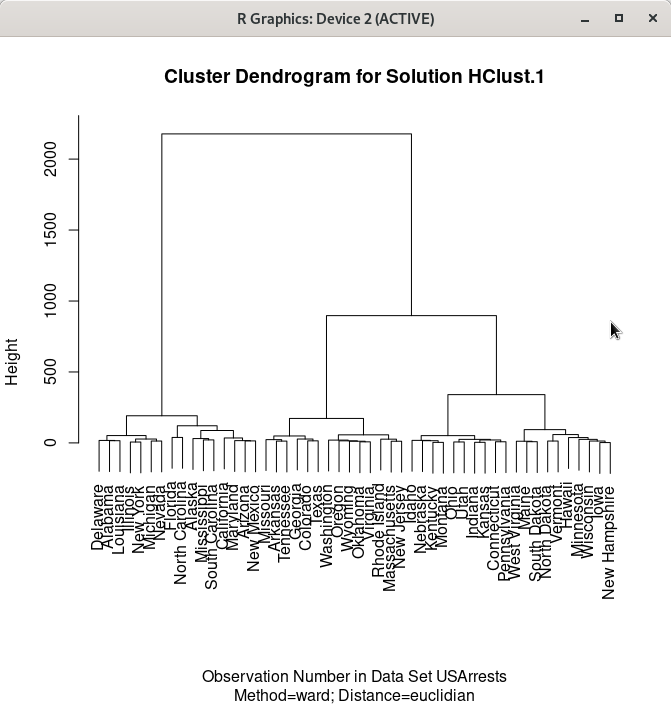
Linux 사례 (MX 21)
data(USArrests, package="datasets")
HClust.1 <- hclust(dist(model.matrix(~-1 + Assault+Murder+Rape+UrbanPop, USArrests)) , method=
"ward")
plot(HClust.1, main= "Cluster Dendrogram for Solution HClust.1", xlab=
"Observation Number in Data Set USArrests", sub="Method=ward; Distance=euclidian")7.7.3 군집 분석 > 위계 군집화 요약하기…/ Cluster analysis > Summarizing hierarchical clustering…
Linux 사례 (MX 21)
‘통계 > 차원 분석 > 군집 분석 > 위계 군집 분석’을 하였다고 하자. 그 다음에는 <위계 군집화 요약하기…> 기능을 사용할 수 있다.
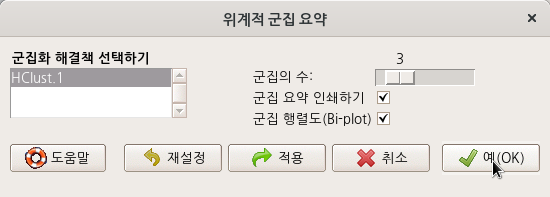
창에서 를 3으로 변경해보자. , <군집 행렬도(Bi-plot)> 등이 선택되어 있는 것을 점검하자.
Linux 사례 (MX 21)
예(OK) 버튼을 누르면, 아래와 같은 그래픽 창이 등장한다.
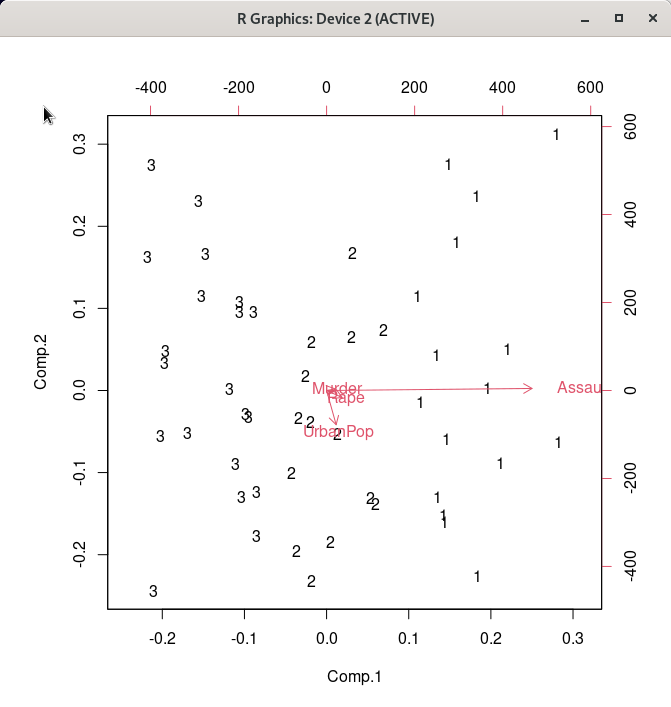
Linux 사례 (MX 21)
summary(as.factor(cutree(HClust.1, k = 3))) # Cluster Sizes
by(model.matrix(~-1 + Assault + Murder + Rape + UrbanPop, USArrests), as.factor(cutree(HClust.1, k
= 3)), colMeans) # Cluster Centroids
biplot(princomp(model.matrix(~-1 + Assault + Murder + Rape + UrbanPop, USArrests)), xlabs =
as.character(cutree(HClust.1, k = 3)))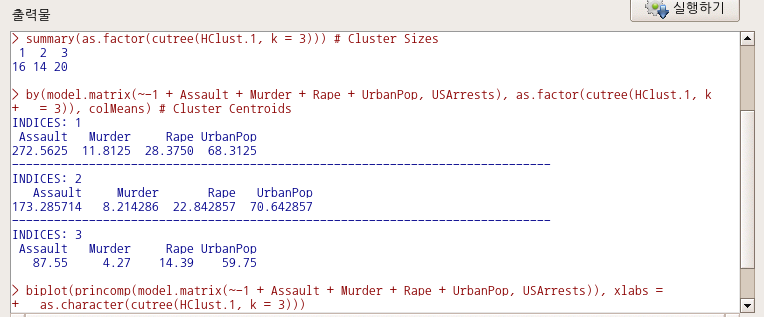
Linux 사례 (MX 21)
7.7.4 군집 분석 > 위계 군집화를 데이터셋에 추가하기…/ Cluster Analysis > Add hierarchical clustering to data set…
Linux 사례 (MX 21)
’ 통계 > 차원 분석 > 군집 분석 > 위계 군집 분석…’ 기능을 진행했다고 하자. 그 다음에 <위계군집화를 데이터 셋에 추가하기…>를 이용할 수 있다. 를 3으로 변경하자. 그리고 예(OK) 버튼을 누르면, hclus.label라는 변수가 USArrests 데이터셋에 추가된다.

Linux 사례 (MX 21)
R Commander 상단에 있는 버튼을 눌러보자. 아래와 같이 데이터셋의 내부 구성이 보일 것이다. hclus.label 변수가 추가되어 있음을 확인할 수 있다:
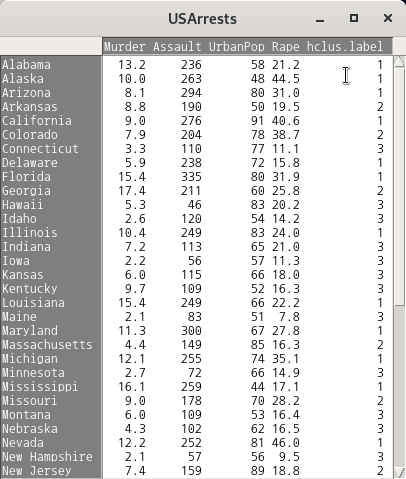
Linux 사례 (MX 21)
7.7.5 척도 신뢰성…/ Scale reliability…
Linux 사례 (MX 21)
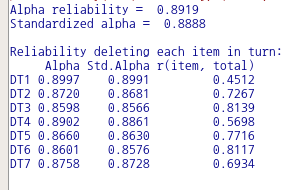
carData 패키지에서 제공하는 DavisThin 데이터셋을 활성화시키자. DavisThin 데이터셋에는 DT1, DT2, DT3, …, DT7 이라는 7개의 수치형 변수가 있다. 이 변수들은 “drive for thinness” 척도를 구성한다.
창에서 <변수 (세개 이상 선택)> 기능에서 DT1부터 DT7까지 일곱개의 변수를 선택하고, 예(OK) 버튼을 누른다.
Linux 사례 (MX 21)
Linux 사례 (MX 21)
7.7.6 주-성분 분석…/ Principal-components analysis…
Linux 사례 (MX 21)
메뉴 창에서 <변수 (두개 이상 선택)> 에서 4개의 변수를 모두 선택해보자.
Linux 사례 (MX 21)
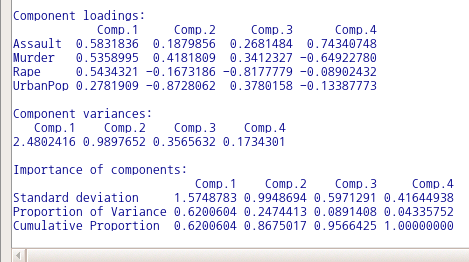
창에서 기본 설정되어 있는 기능을 기억하자.
Linux 사례 (MX 21)
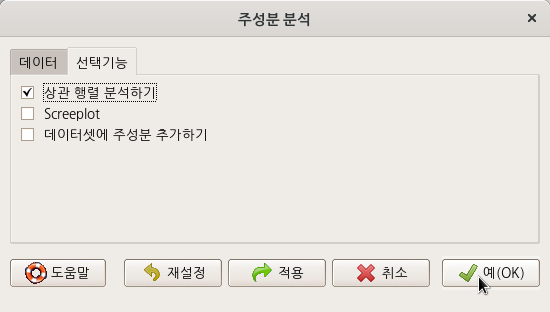
local({
.PC <- princomp(~Assault+Murder+Rape+UrbanPop, cor=TRUE, data=USArrests)
cat("\nComponent loadings:\n")
print(unclass(loadings(.PC)))
cat("\nComponent variances:\n")
print(.PC$sd^2)
cat("\n")
print(summary(.PC))
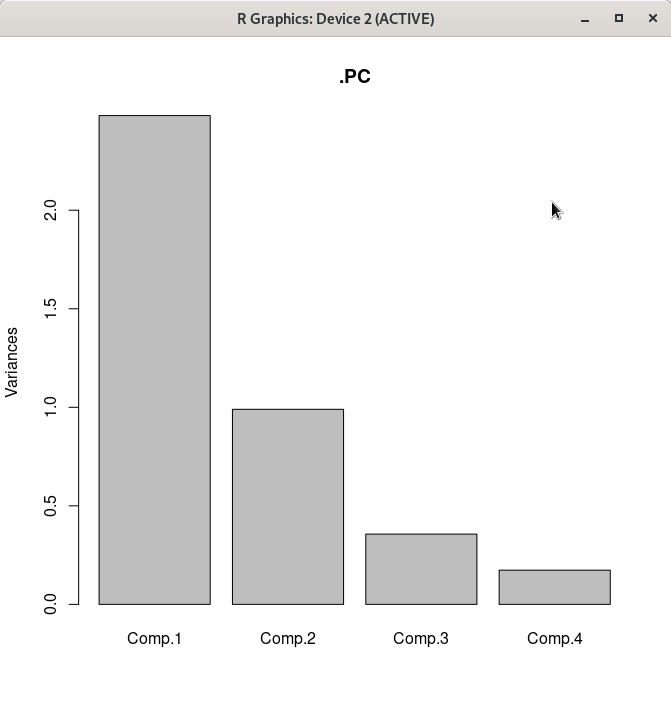
})
Linux 사례 (MX 21)
Linux 사례 (MX 21)
biplot(.PC)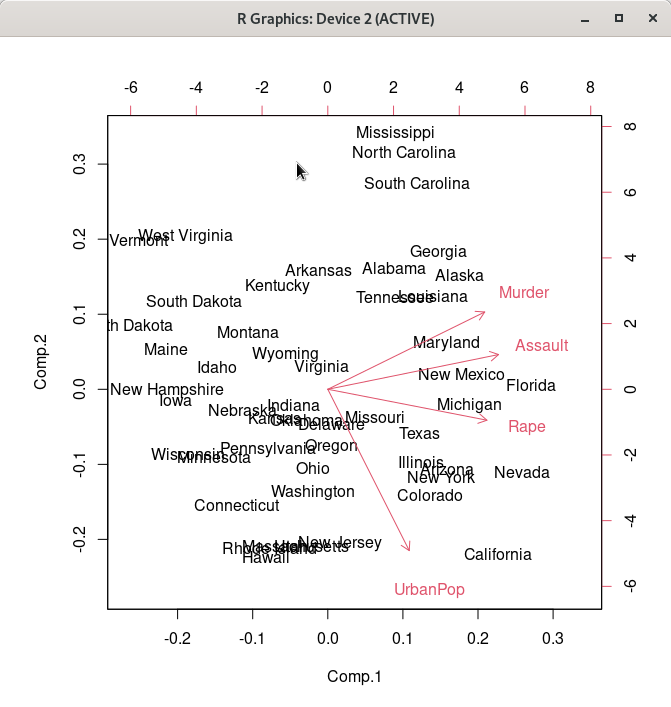
Linux 사례 (MX 21)
7.8 적합성 모델 / Fit models
7.8.1 선형 회귀…/ Linear regression…
Linux 사례 (MX 21)
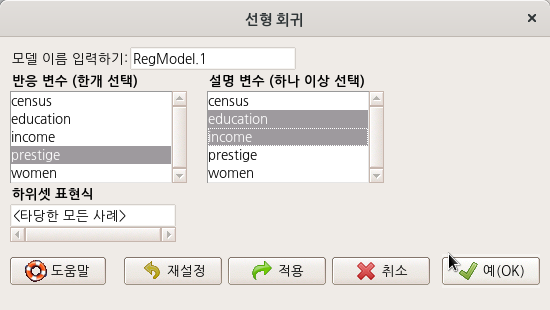
carData 패키지에서 제공하는 Prestige 데이터셋을 불러와서 활성화시키자. 그러면, 위의 화면처럼 <선형 회귀…> 기능이 활성화될 것이다. 이 기능을 선택하면 아래와 같이 Prestige 데이터셋의 변수 목록이 등장하며, 회귀분석을 위한 구조적 설계를 시작한다.
교육연수(education)와 연소득(income)이 직업의 사회적권위(prestige)에 영향을 미치는가? 어떤 영향을 미치는가? 등의 문제의식을 통계적으로 점검한다고 해보자. 교육연수와 연소득은 설명 변수일 것이며, 직업의 사회적 권위는 이 두개의 설명 변수로부터 영향을 받는 반응 변수가 될 것이다. 한편, 에는 RegModel.1이 자동적으로 추천된다. 여러 개의 모델을 만들어 점검하는 경우, 지속적으로 일련번호가 추가된다. 분석가가 자유롭게 모델 이름을 정할 수 있다.
Linux 사례 (MX 21)
예(OK) 버튼을 누르면, R Commander 화면 상단에 있는 <모델:>옆에 파란색으로 RegModel.1이 등장한다.

Linux 사례 (MX 21)
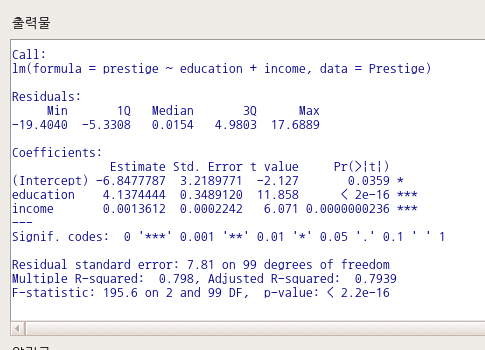
R Commander의 출력 창에는 만든 선형 회귀 모델의 결과가 출력된다.
Linux 사례 (MX 21)
7.8.2 선형 모델…/ Linear model…
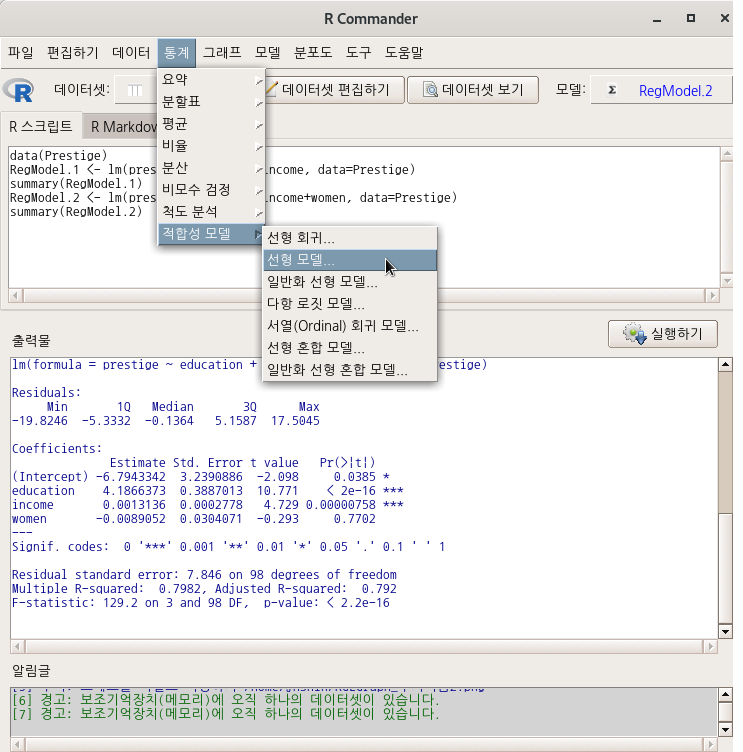
Linux 사례 (MX 21)
아래와 같은 선택 창에서 변수들을 선택할 수 있다. <통계 : 적합성 모델 : 선형 회귀…> 기능의 <선형 회귀…>창과 달리 선택할 수 있는 변수에 ’type [요인]’이 추가되어 있다.
carData 패키지에서 제공되는 Prestige 데이터셋에는 요인형 변수 type이 포함되어 있다. 기능에는 요인형 변수를 함께 넣어서 계산할 수 있고, 표본을 모집단 크기에 비율적으로 맞추고자 사례 값에 가중치를 넣어서 계산하는
Linux 사례 (MX 21)
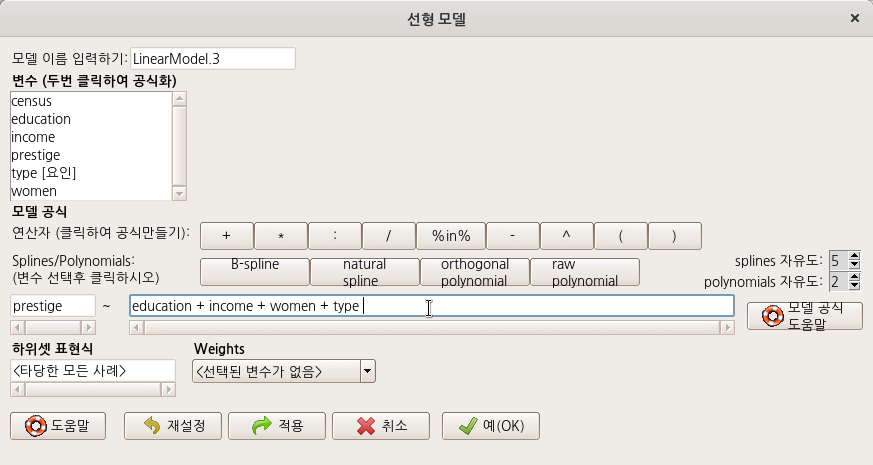
아래 창은 위의 모델 구성식과는 다른 방식을 제안한다. 직업의 사회적 권위 (prestige)에 대한 education + income + women + type 의 영향력을 계산하는 것이 아니라, education + log(income)의 결과와 type의 관계가 prestige 변수에 미치는 영향력을 계산하는 식이다.
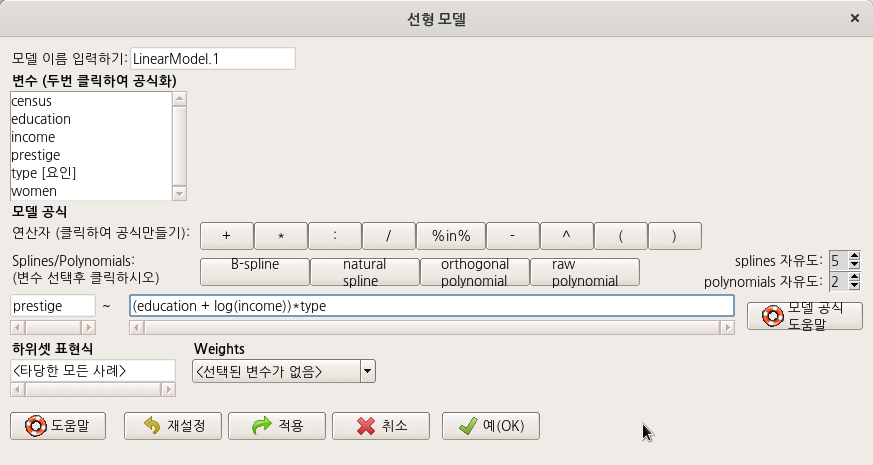
Linux 사례 (MX 21)
LinearModel.1 <- lm(prestige ~ (education + log(income))*type, data=Prestige)
summary(LinearModel.1)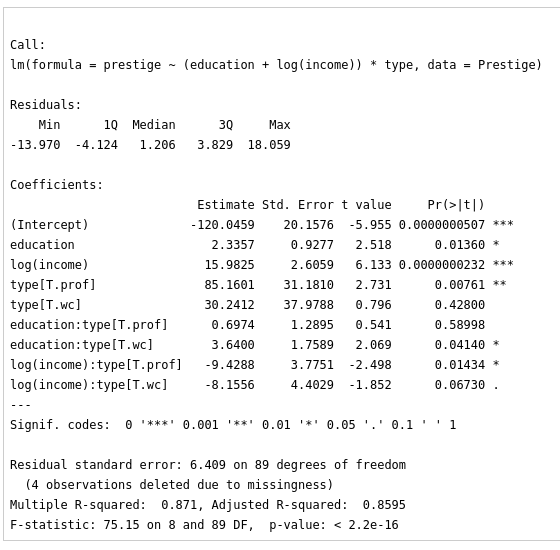
Linux 사례 (MX 21) - R Markdown 보고서 결과
7.8.3 일반화 선형 모델…/ Generalized linear model…
Linux 사례 (MX 21)
MASS 패키지에 있는 birthwt 데이터셋을 활용하자.
birthwt 데이터셋을 분석을 위하여 변형시켜서 bwt라는 데이터셋으로 만들자.
bwt <- with(birthwt, {
race <- factor(race, labels = c("white", "black", "other"))
ptd <- factor(ptl > 0)
ftv <- factor(ftv)
levels(ftv)[-(1:2)] <- "2+"
data.frame(low = factor(low), age, lwt, race, smoke = (smoke > 0),
ptd, ht = (ht > 0), ui = (ui > 0), ftv)
})
options(contrasts = c("contr.treatment", "contr.poly"))bwt 데이터셋을 활성화시키자.
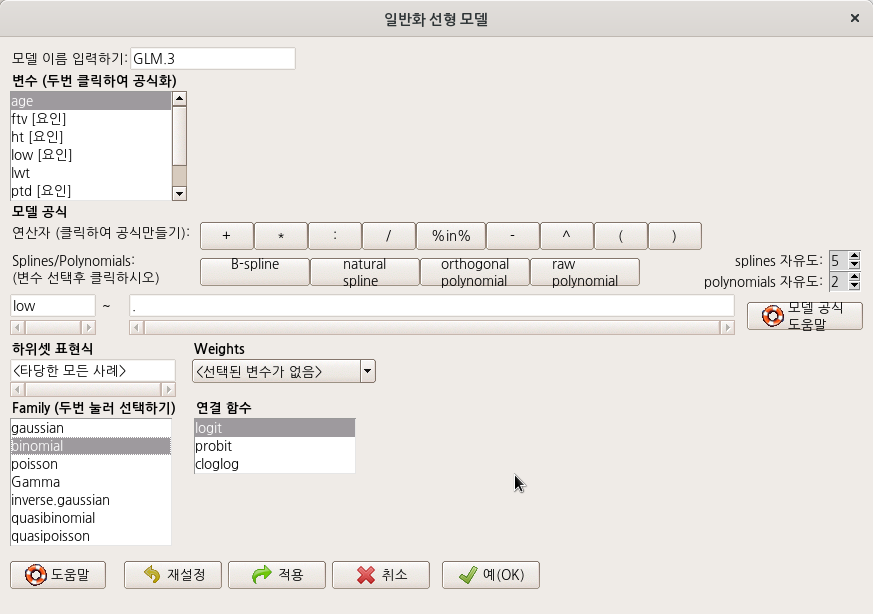
Linux 사례 (MX 21)

Linux 사례 (MX 21) - R Markdown 에서

Linux 사례 (MX 21)
## an example with offsets from Venables & Ripley (2002, p.189)
utils::data(anorexia, package = "MASS")
GLM.2 <- glm(Postwt ~ Prewt + Treat + offset(Prewt),
family=gaussian(identity), data=anorexia)
summary(GLM.2)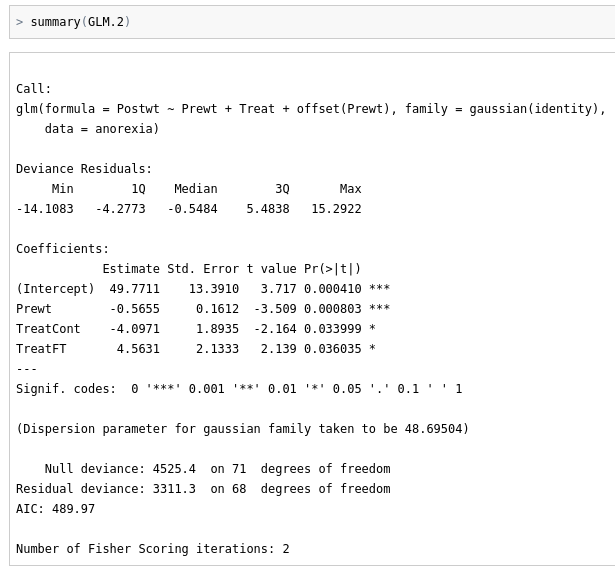
Linux 사례 (MX 21)
data(Cowles, package="carData")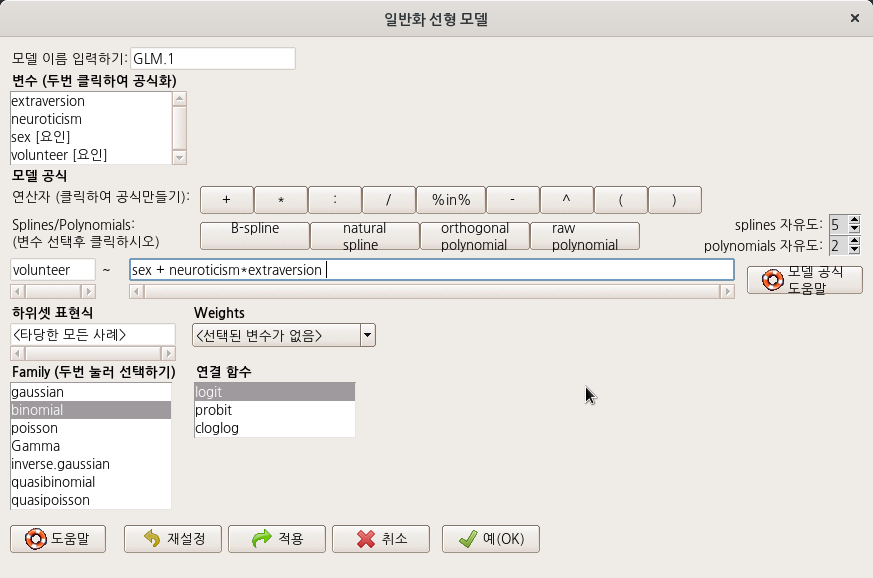
Linux 사례 (MX 21)
GLM.1 <- glm(volunteer ~ sex + neuroticism*extraversion, family=binomial(logit), data=Cowles)
summary(GLM.1)
exp(coef(GLM.1)) # Exponentiated coefficients ("odds ratios")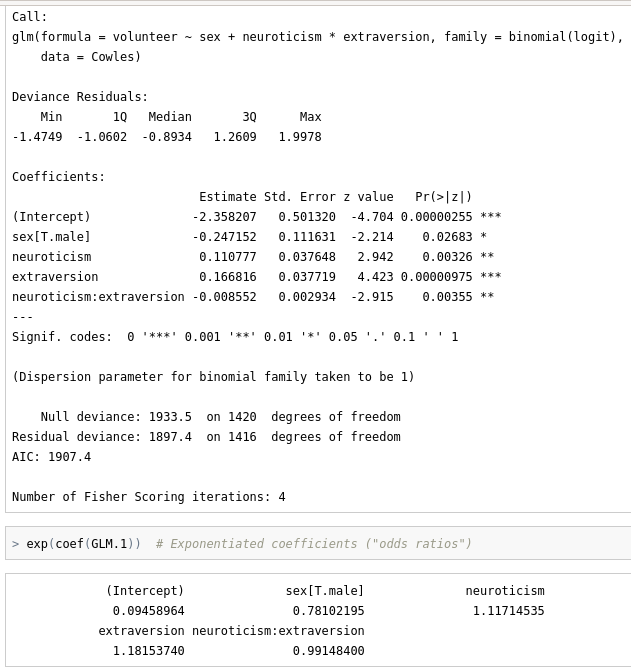
Linux 사례 (MX 21)
7.8.4 다항 로짓 모델…/ Multinomial logit model…
Linux 사례 (MX 21)
MASS 패키지에 있는 birthwt 데이터셋을 활용해보자. 먼저 birthwt 데이터셋을 활성화 시킨다.
이후 일부 변수의 특징을 변화시켜 bwt라는 새로운 데이터셋을 만들자.아래의 연습 중간에 bwt를 만드는 스크립트가 있다.
아래 화면은 bwt 데이터셋을 활용한 사례이다.
Linux 사례 (MX 21)
MLM.1 <- multinom(low ~ ., data=bwt, trace=FALSE)
summary(MLM.1, cor=FALSE, Wald=TRUE)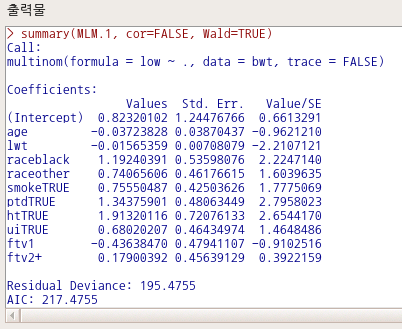
Linux 사례 (MX 21)