8 . 그래프 / Graph
8.1 색 팔레트…/ Color palette…
Linux 사례 (CentOS 7.x)
<색 팔레트…> 기능을 선택하면 8개의 주요 색깔이 등장하고 그 색의 16진수(hexadecimal)값과 이름이 표시된다.

Linux 사례 (CentOS 7.x)
다섯째 색인 cyan, 일곱째 색인 yellow를 각각 gold, orange로 바꿔보자.

Linux 사례 (CentOS 7.x)
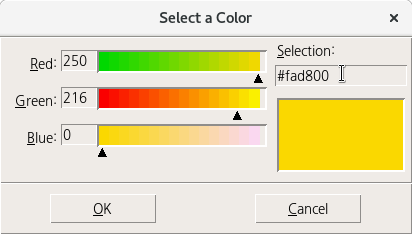
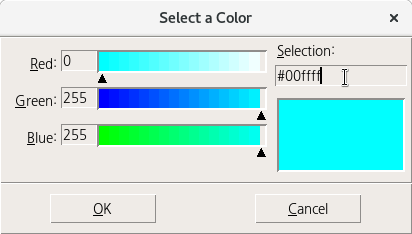
gold의 16진수 값인 #fad800, orange의 16진수 값인 #ffa500을 기억하자. cyan의 16진수 값인 #00ffff, yellow의 16진수 값인 #ffff00을 기억하자. gold를 cyan으로, orange를 yellow로 다시 바꿔보자. Selection: #fad800을 cyan의 #00ffff로 바꾸고 실행(엔터키)을 한다.
Linux 사례 (CentOS 7.x)
Linux 사례 (CentOS 7.x)
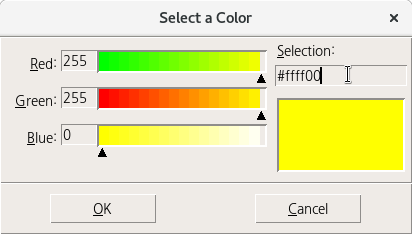
yellow로 바꾸려면, 16진수 값 #ffff00을 입력하고 실행(엔터키)을 한다. 다음과 같이 바뀔 것이다:
Linux 사례 (CentOS 7.x)
8.2 색인 그림…/ Index plot…
데이터셋이 활성화되어 있는 경우, 색인 그림(index plot)을 사용할 수 있다. 예를 들어, carData 패키지의 Prestige 데이터셋이 활성화되어있다고 하자.
Linux 사례 (MX 21)
Prestige 데이터셋에 있는 education 변수의 색인 그림을 만들자. 메뉴창에 있는 variable (pick one or more) 에서 education을 선택한다. 그 아래에 있는 <집단별 표시…>에서 요인형 변수를 선택하여 요인 수준별로 색인 그림을 출력할지 결정할 수 있다(이 설명에서는 이 기능을 사용하지 않는다). 그리고 디렉토리로 이동하여 세부사항을 점검한다.
Linux 사례 (MX 21)
의 메뉴창에 다양한 기능이 있다. 에서
Linux 사례 (MX 21)
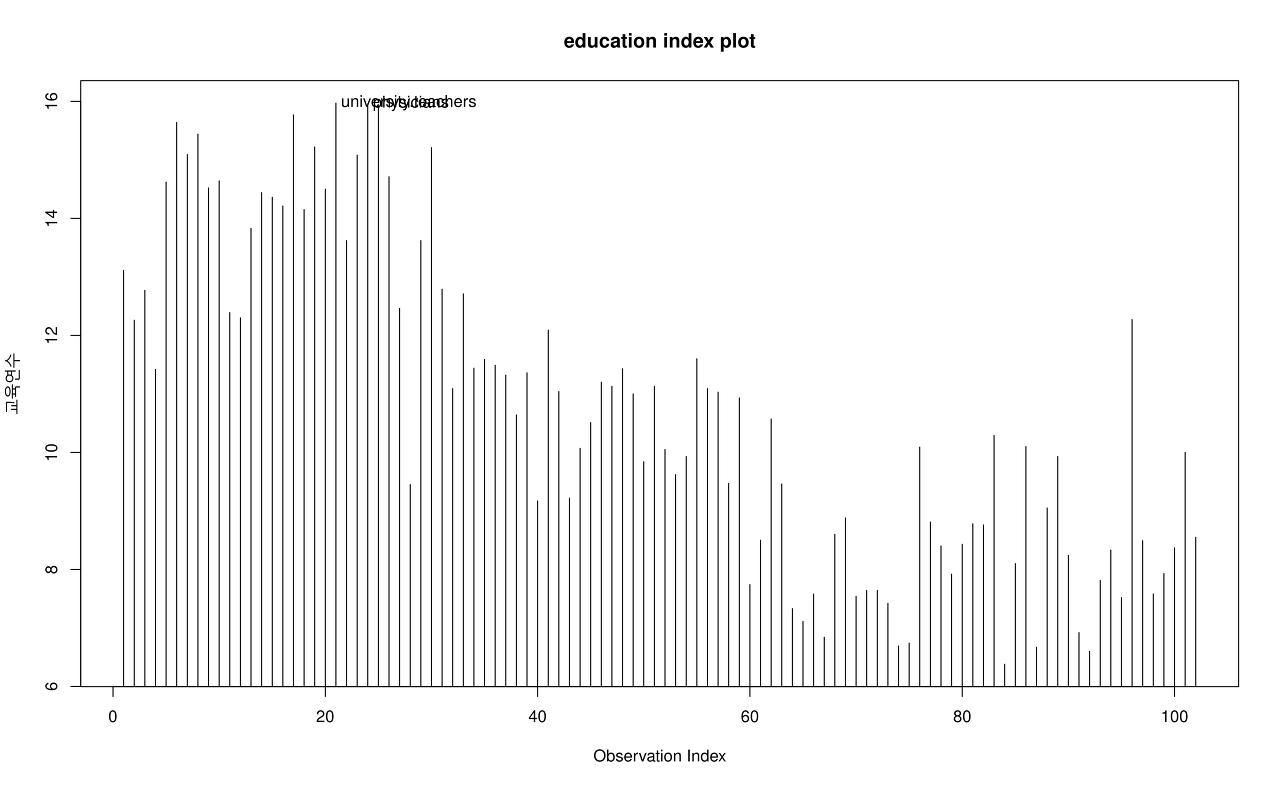
새로운 그래픽 장치창이 등장한다. 그리고 그 장치창에 안의 아래 화면 왼쪽에 ’교육연수’가, 상단 중앙에 ’education index plot’이 출력된다. 한편 그래프 안에 두개의 사례 이름이 겹쳐서 인쇄된 현상을 보게된다.
Linux 사례 (MX 21)
아래 출력창을 살펴보자. indexplot() 함수의 코드 사용법을 먼저 살펴본다. 앞서 입력한 ‘교육연수’, ’education index plot’이 인자 안에 들어있는 알 수 있다.
indexplot(Prestige[,'education', drop=FALSE], type='h', id.method='y', id.n=2,
ylab="교육연수", main="education index plot")education 변수의 사례 값 중에서 university.teachers는 15.97, physicians는 15.96라는 두개의 최고 값을 갖는다. 출력창에는 university.teachers, physicians 라는 순서와 함께 사례번호인 21, 24가 출력된다.
한편 그 밑에 있는 명령문은 출력된 그래픽창의 그림을 저장하는 내용을 담고 있다.
dev.print(png, filename="/home/jhshin/사진/Rcmdr/Graphs/indexplot/RGraph_indexplot1.png",
width=13, height=8, pointsize=12, units="in", res=300)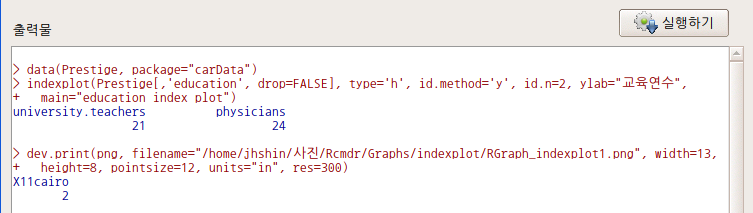
Linux 사례 (MX 21)
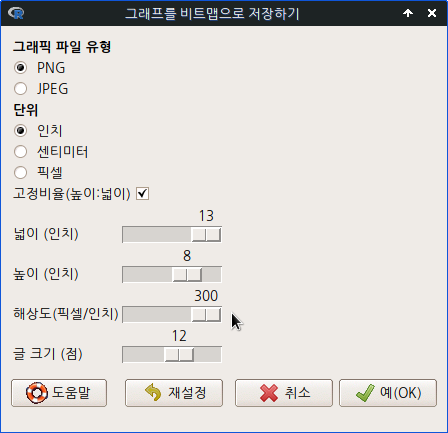
Graphs > Save graph to file 메뉴에서 <bitmap(으)로…> 기능을 선택하면 아래와 같은 선택창이 등장한다. 해상도를 300으로 최대한으로 올려보자. 예(OK) 버튼을 누른다.
Linux 사례 (MX 21)
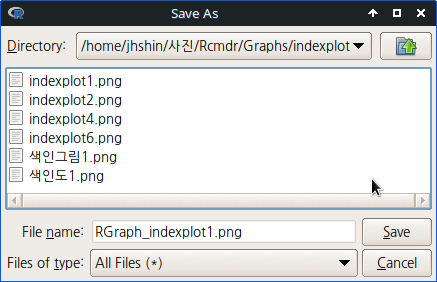
그래픽 파일을 저장할 위치를 결정하고, 결정한 파일 이름을 입력하고 저장하기(save)를 누른다. 실용적으로 RGraph_indexplot1.png라고 저장해보자.
 ## 점 플롯 / Dot plot…
## 점 플롯 / Dot plot…8.3 히스토그램…/ Histogram…
Linux 사례 (MX 21)
히스토그램으로 시각화할 변수는 수치형 (numeric, integer)이다. Prestige의 요인형 변수 type은 <집단기준으로 그리기…>에서 선택할 수 있다.
Linux 사례 (MX 21)
income 변수의 정보를 몇 개의 구간으로 나눠서 히스토그램을 만들 것인가, 그래프의 이름(title, label)관련 정보를 어떻게 넣을 것인가를 조정, 입력할 수 있다.
Linux 사례 (MX 21)
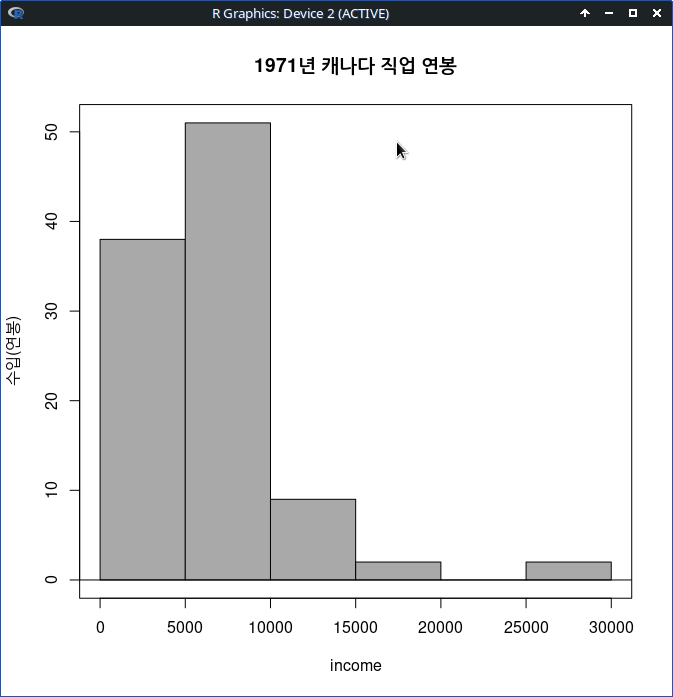
with(Prestige, Hist(income, scale="frequency", breaks="Sturges", col="darkgray",
ylab="수입(연봉)", main="1971년 캐나다 직업 연봉"))그래픽장치 창에 다음과 같은 히스토그램이 등장한다.
Linux 사례 (MX 21)
파일로 저장하여 활용하고자 할 때 사용하는 기능이다.
Linux 사례 (MX 21)
<bitmap(으)로…> 기능을 열면, 아래와 같은 파일 저장 선택기능들을 점검할 수 있다. 표현하고자는 시각화 목표에 따라 넓이와 높이를 변화줄 수 있고, 해상도를 높게, 글 크기를 크게 할 수 있다.
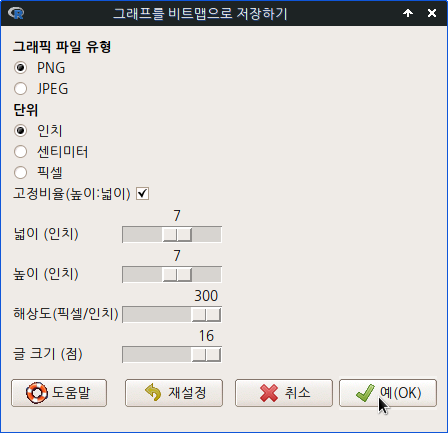
Linux 사례 (MX 21)
dev.print(png, filename="/home/jhshin/RGraph_historgram1.png", width=7, height=7,
pointsize=16, units="in", res=300)예(OK) 버튼을 누르면 파일의 경로와 이름을 정할 수 있는 메뉴창이 아래와 같이 등장한다. 저장 경로를 결정하고, 희망이름.png 파일로 저장하자.
Linux 사례 (MX 21)
저장된 파일을 다시 한번 열어보자. 아래와 같다:
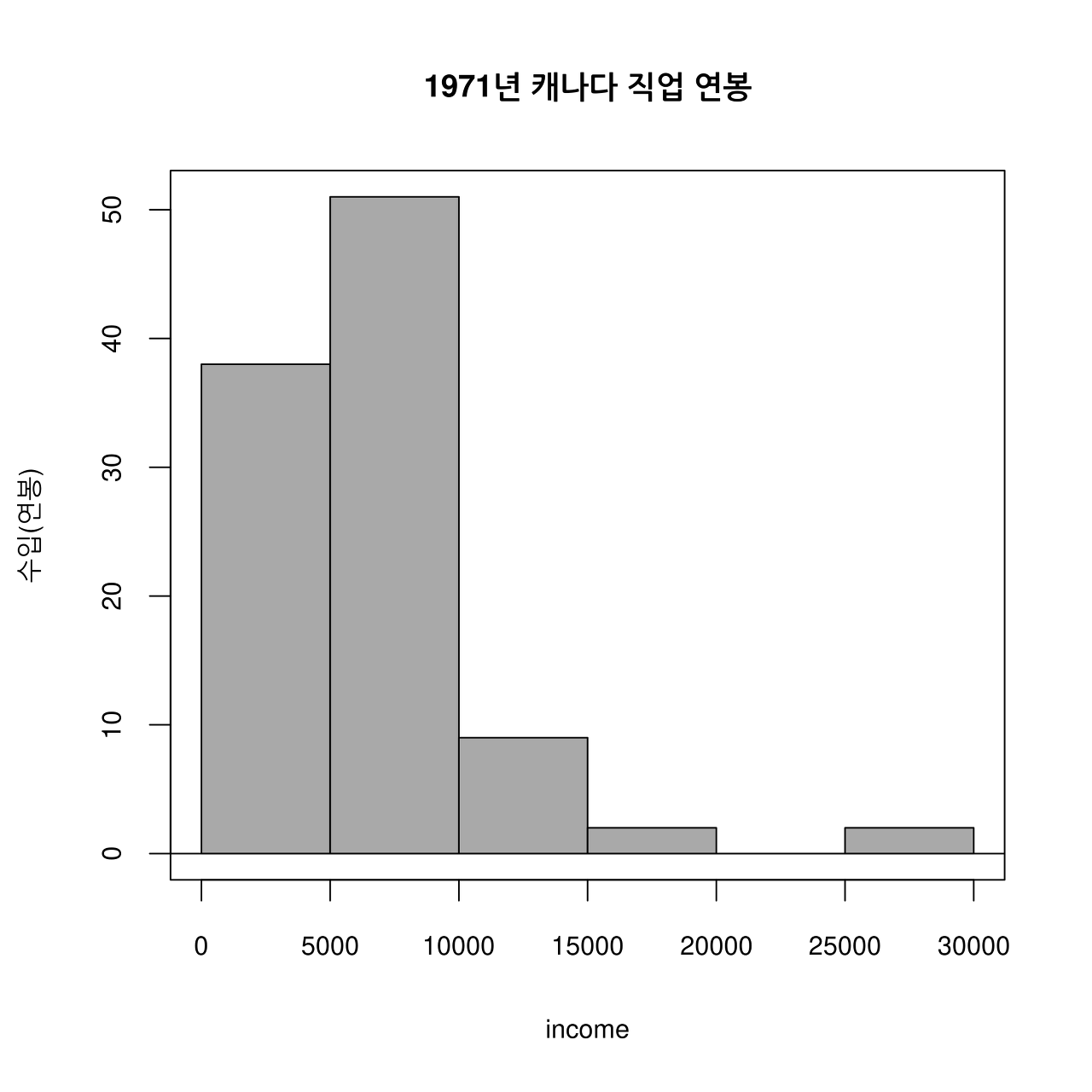
Linux 사례 (MX 21)
8.4 이산형 수치 변수 그리기…/ Plot discrete numeric variable…
Linux 사례 (MX 21)
carData 패키지의 Cowles 데이터셋을 활용해서 연습해보자.
data(Cowles, package="carData") # Cowles 데이터셋 불러오기
summary(Cowles) # Cowles 데이터셋의 요약정보 보기 (변수이름, 사례요약)외향성을 의미하는 이산형 수치 변수인 extraversion을 선택한다.
Linux 사례 (MX 21)
요인형 변수 목록에 sex와 volunteer가 있다. volunteer를 선택한다.
Linux 사례 (MX 21)
창의 선택 기능중에서 에 ’백분율”을 선택한다. 그리고 에는 내용적 이해를 돕는 사항들을 넣을 수 있다.
Linux 사례 (MX 21)
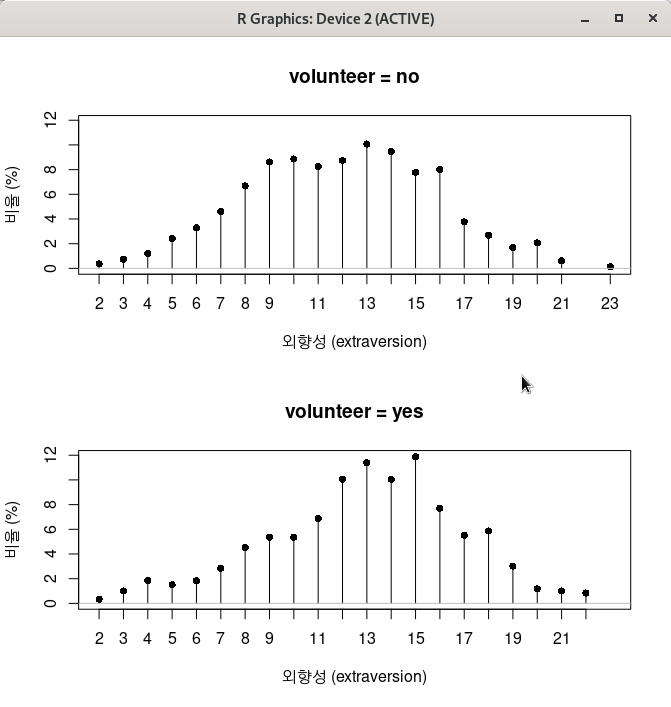
아래와 같이 그래픽 창에 ‘이산형 수치 변수’ extraversion의 백분율 분포가 자원봉사 지원 여부인 volunteer 변수의 요인형 수준인 ‘no’, ‘yes’ 별로 그래프화된다.
Linux 사례 (MX 21)
with(Cowles, discretePlot(extraversion, by=volunteer, scale="percent", xlab="외향성 (extraversion)",
ylab="비율 (%)", main="자원봉사 지원여부 그룹에 따른 외향성 분포"))8.5 밀도 추정…/ Density estimate…
Linux 사례 (MX 21)
밀도 그래프(densityplot)은 수치형 변수를 촘촘히 배열하면서 그 사례사이의 거리를 역으로 밀도화시키는 방법이다. 줄여 말하면, 거리가 가까우면 밀도가 높고, 거리가 멀면 밀도가 낮게 계산되고 시각화된다. Prestige 데이터셋의 income 변수를 사용해보자.
Linux 사례 (MX 21)
Linux 사례 (MX 21)
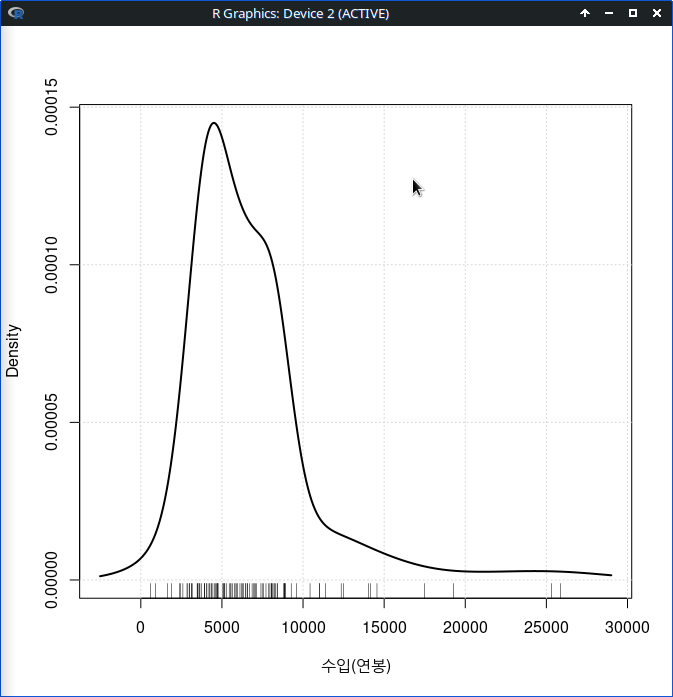
밀도 추정 그래프를 시각화하는 경우, 그래프의 시작점과 끝점에 대한 사전정보를 수치적 정보 요약 등을 활용하여 미리 알고서 지정해주면 그래프가 보다 정교해진다. 위의 그래프를 보라. 수입(연봉)을 표시하는 촘촘한 사례들의 영역 바깥에 그래프의 왼쪽 긑과 오른쪽 끝이 표시된 것을 보게된다. 변화를 줘보자.
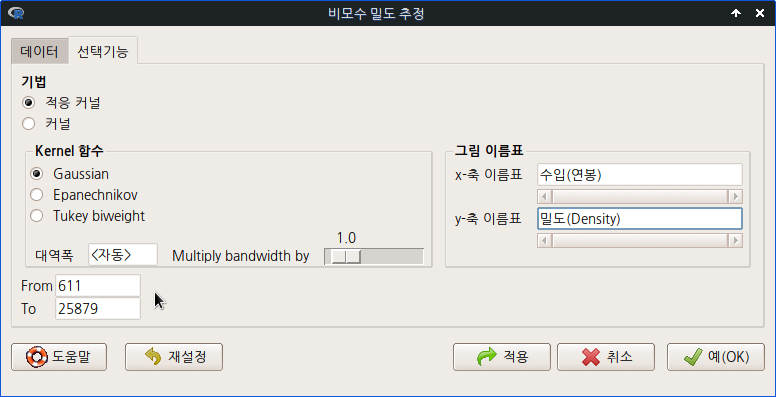
numSummary(Prestige\[,"income", drop=FALSE\], statistics=c(“mean”, “sd”, “IQR”, “quantiles”), quantiles=c(0,.25,.5,.75,1)) numSummary() 함수를 활용하여 최소값, 최대값 등을 찾아보자. 그 사례 값을 아래의 입력창에 넣는다.
Linux 사례 (MX 21)
그래프의 시작점에 최소값을, 끝점에 최대값을 넣고 그래프를 만들면, 수입(연봉)의 분포가 보다 분명하게 보일 것이다.
densityPlot( ~ income, data=Prestige, bw=bw.SJ, adjust=1, kernel=dnorm, method="adaptive", from=611, to=25879, xlab="수입(연봉)", ylab="밀도(Density)")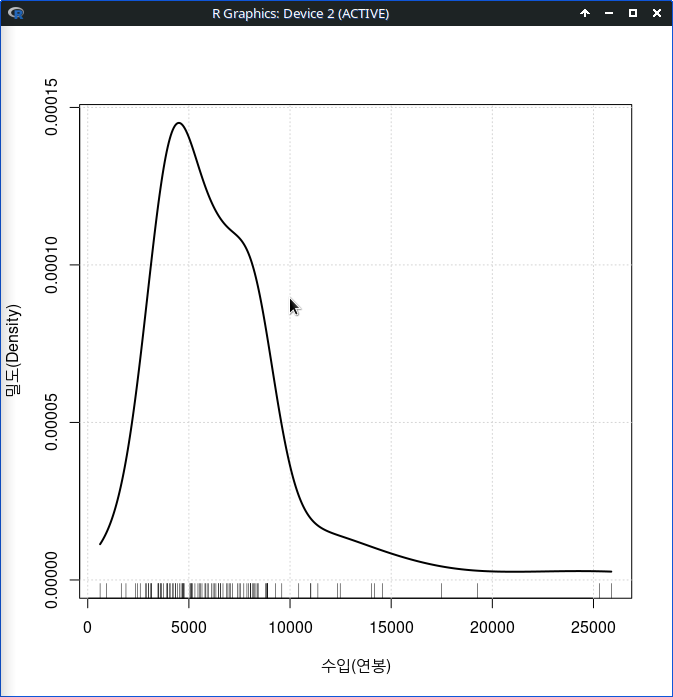
Linux 사례 (MX 21)
한편, 직업유형인 요인형 변수 type을 기준으로 수입(연봉)의 분포를 재분류해보자. <집단 기준으로 그리고…> 버튼을 누르면 <집단 변수 (하나 선택)> 기능에서 요인형 변수 목록이 나타날 것이다. Prestige 데이터셋에는 type 하나만 있다. 그리고 예(OK) 버튼을 누른다.
Linux 사례 (MX 21)
그러면 <집단 기준으로 그리기…> 버튼이
Linux 사례 (MX 21)
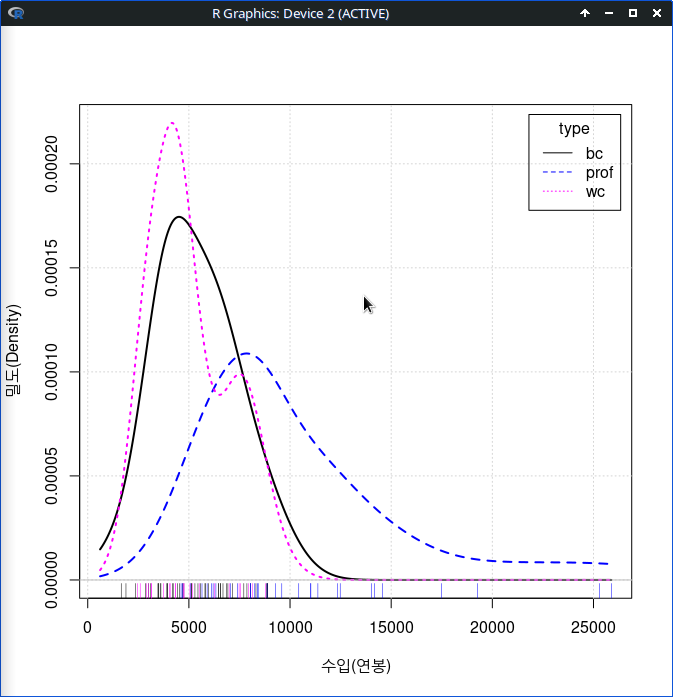
그래픽장치 창에 type 별 수입(연봉)에 대한 밀도 그래프가 등장한다. 그래프의 오른쪽에는 네모상자 안에 범례 표시가 있어서 어떤 선이 요인형 변수의 어떤 수준을 나타내는지 알려준다.
Linux 사례 (MX 21)
그래프 > 그래프를 파일로 저장하기 > PDF/Postscript/EPS(으)로 에서 PDF 파일로 저장해보자. 넓이와 높이에 대한 조정 없이<글 크기 (점)>을 16까지 키워보자.
Linux 사례 (MX 21)
아래 코드에서 ’main’인자를 살펴보라. 메뉴창에 등장하는 기능을 활용하면서 적용할 수 있는 범위에 DensityPlot 함수에는 제목 입력이 없다. 아쉽기도 한 부분이다. 이 경우는 입력창에서 main=“제목 이름”을 추가하여 넣고 실행하기 버튼을 누르면 된다.
densityPlot(income~type, data=Prestige, bw=bw.SJ, adjust=1, kernel=dnorm, method="adaptive", from=611, to=25879, xlab="수입(연봉)", ylab="밀도(Density)", main="1971년 캐나다 직업 유형별 수입에 관한 밀도그래프")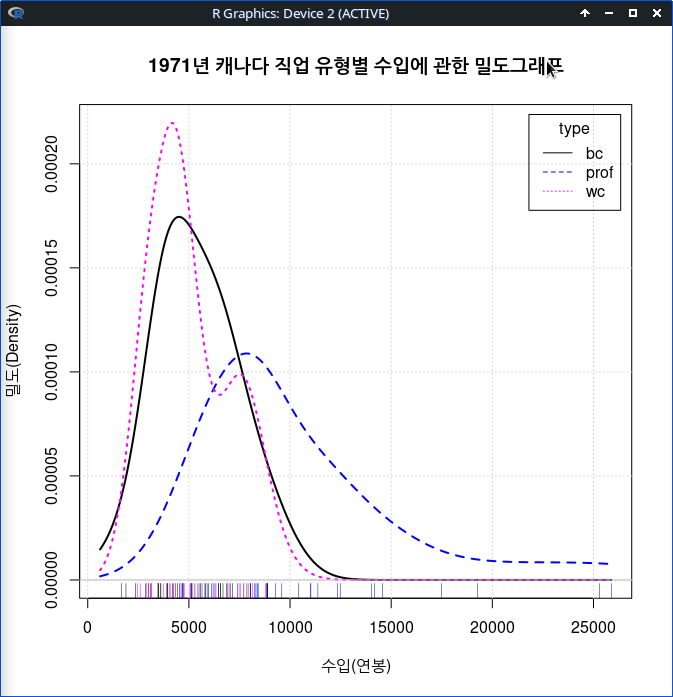
Linux 사례 (MX 21)
Q1> 첨부된 PDF 파일에는 제목과 축에 사용된 한글이 보이지 않고 점(…)으로 표시됩니다. 고쳐주세요.
8.6 줄기-잎 전시…/ Stem-and-leaf display…
Linux 사례 (MX 21)
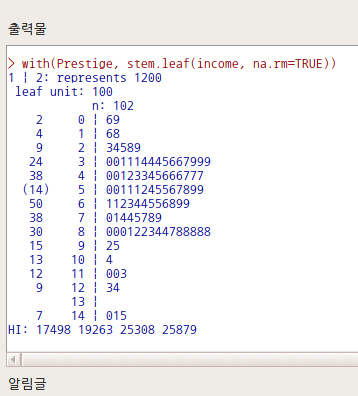
Prestige 데이터셋의 income 변수로 연습해보자. 먼저 income 변수의 수리적 특징에 대하여 점검한다.

Linux 사례 (MX 21)
Prestige 데이터셋에 있는 수치형 변수 중에서 income 변수를 선택한다. 그리고 선택기능을 살펴본다.
Linux 사례 (MX 21)
Linux 사례 (MX 21)
Linux 사례 (MX 21)
8.7 상자그림…/ Boxplot…
Linux 사례 (MX 21)
Prestige 데이터셋의 수치형 변수 income을 요인형변수 type의 수준별로 상자그림을 만들고 type별로 비교해보자.
Linux 사례 (MX 21)
옆에 있는 으로 넘어가서 살펴보자. 기본설정으로 되어있는 의 ’자동적으로’를 놔두고, 에 한글을 입력하면서 의미적 해석이 가능한 이름과 제목을 넣는다.
Linux 사례 (MX 21)
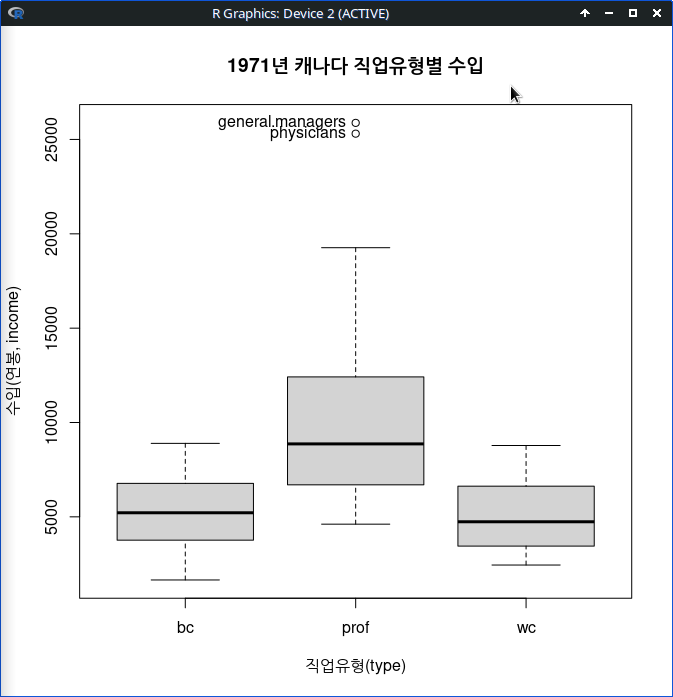
그래픽장치 창에 상자그림이 등장한다. 직업유형의 수준인 bc, prof, wc (블라칼라, 전문직, 화이트칼라) 별로 상자그림이 시각화되어 최소값, 중앙값(median), 최대값과 25%, 75% 수준의 값과 이상치 등이 표시된다.
Linux 사례 (MX 21)
아래와 같은 명령문이 사용된다:
Boxplot(income~type, data=Prestige, id=list(method="y"), xlab="직업유형(type)",
ylab="수입(연봉, income)", main="1971년 캐나다 직업유형별 수입")8.8 분위수-비교 그림…/ Quantile-comparison plot…
분위수-비교 그림은 수치형 변수 사례 값의 분포적 경향성을 확인하는데 사용된다. 또한 변수들의 관계에 대한 수리적 계산 과정에서 발생하는 잔차(Residuals)들의 분포적 특징을 확인하는데 활용할 수 있다.
Linux 사례 (MX 21)
Prestige 데이터셋에 있는 수치형 변수중에 income 변수를 선택해보자.
Linux 사례 (MX 21)
메뉴 창을 열면, income 변수의 특징을 맞춰 볼 분포들을 선택하는 기능이 있다. 기본 설정으로 되어있는 정규분포를 많이 사용한다. 오른쪽에 있는 에 출력될 그래프의 정보를 담는 내용을 입력할 수 있다.
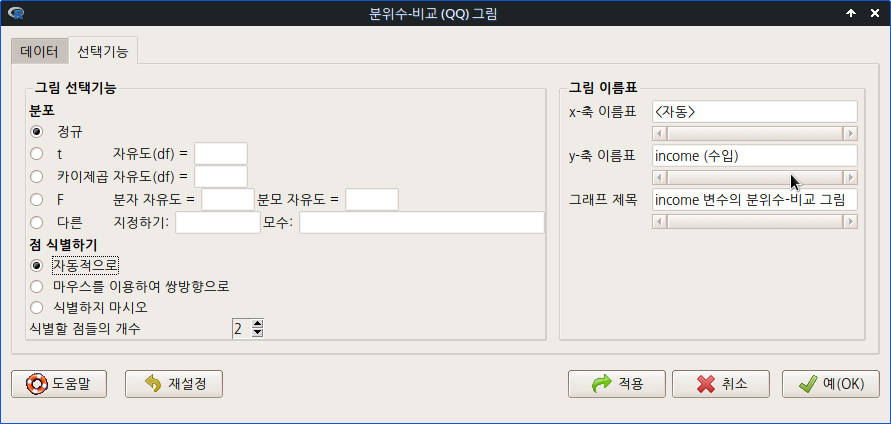
Linux 사례 (MX 21)
정규분포적 특징 안에서 income 변수의 사례적 흐름을 시각적으로 확인할 수 있다. 오른쪽 상단에 두 개의 이상치가 있는데, general.managers, physicians 직업이라고 알려준다.
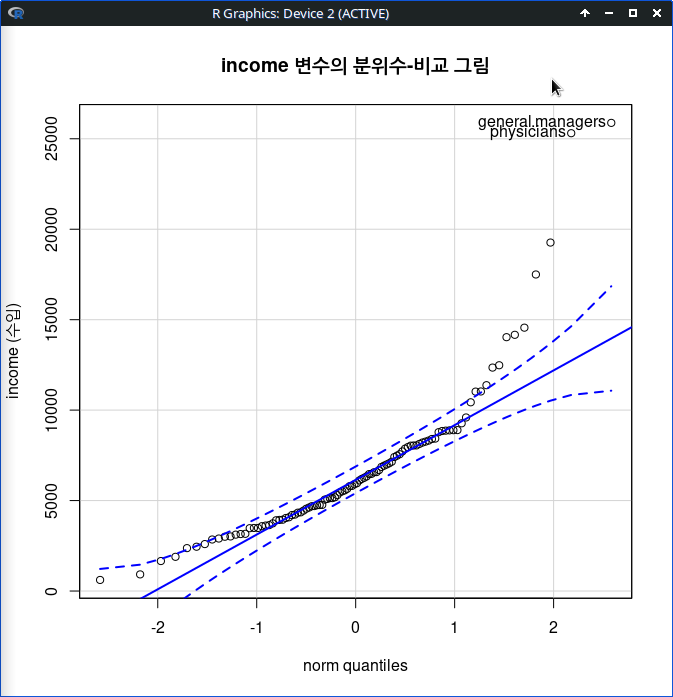
Linux 사례 (MX 21)
with(Prestige, qqPlot(income, dist=“norm”, id=list(method=“y”, n=2, labels=rownames(Prestige)), ylab=“income (수입)”, main=“income 변수의 분위수-비교 그림”))
Linux 사례 (MX 21)
아래 그래프는 income 변수 대신 education 변수를 선택해서 정규분포적 특징 안에서 살펴본 것이다. income 변수에 비해서 이상치들이 적게 보인다.
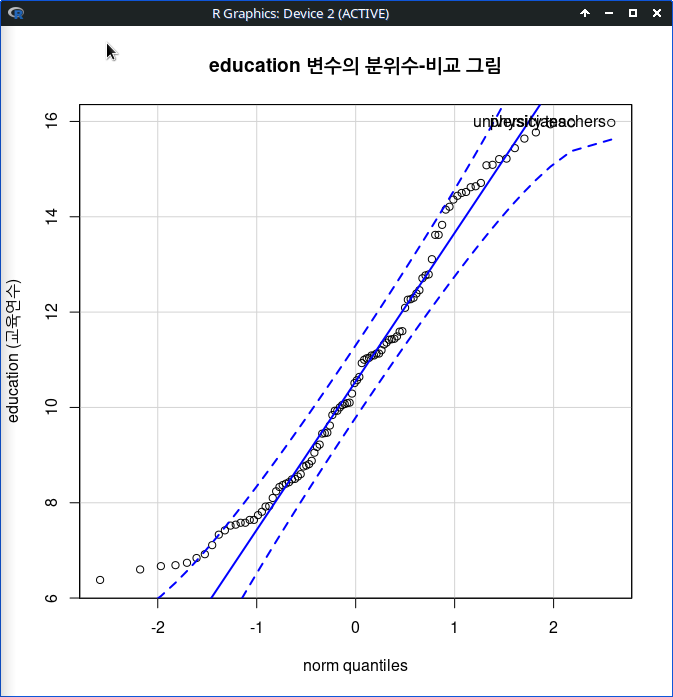
Linux 사례 (MX 21)
아래 그래프는 Prestige 데이터셋에 포함된 prestige 변수의 분위수-비교 그림의 시각화 결과이다. 정규분포적 특징 안에서 prestige 변수의 사례들이 분포되어 있음을 알 수 있다.
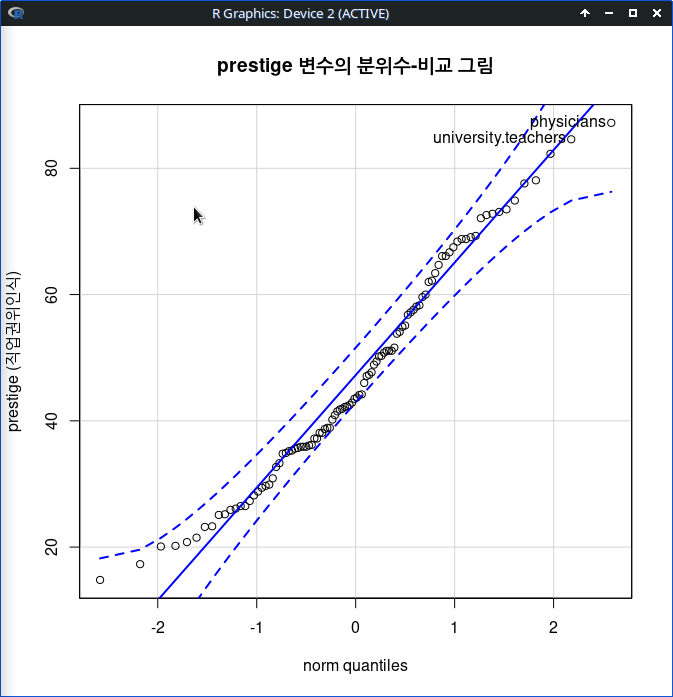
Linux 사례 (MX 21)
참고로 income 변수에 log 계산을 한 후 분위수-비교 그림을 그려보자. 원래의 income 변수보다 정규분포적 특징이 강화된다.
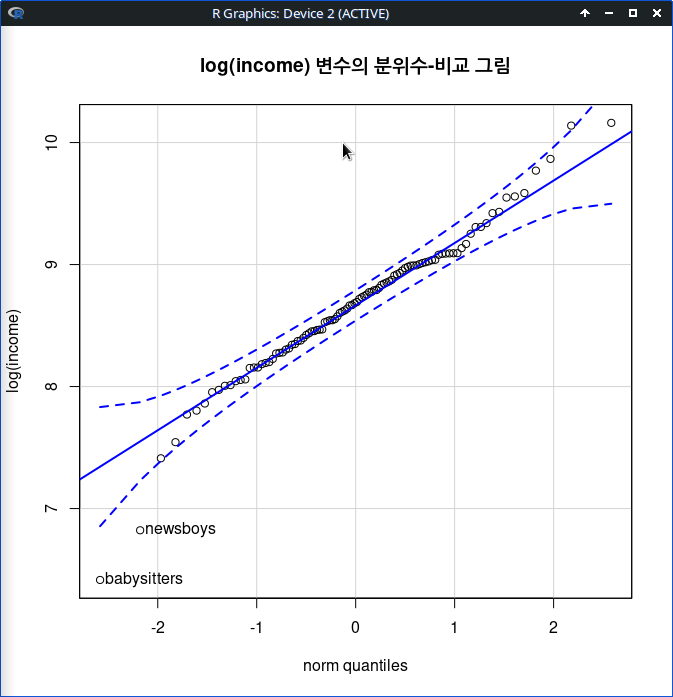
Linux 사례 (MX 21)
8.9 대칭 상자그림…/ Symmetry boxplot…
Linux 사례 (MX 21)
Prestige 데이터셋에 있는 income 변수를 선택해보자.
Linux 사례 (MX 21)
symbox(~ income, data=Prestige, trans=bcPower, powers=c(-1,-0.5,0,0.5,1)) 그래픽장치 창에 아래와 같이 시각화된다:
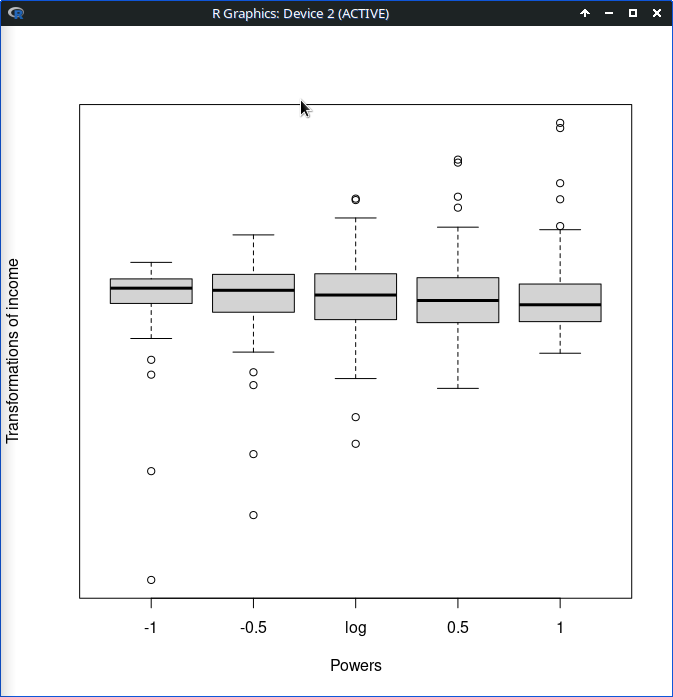
Linux 사례 (MX 21)
8.10 산점도…/ Scatterplot…
Windows 사례 (10 Pro)
산점도(Scatterplot)은 두개의 수치형 변수 사이의 수리적 연관성에 관한 시각화 기법이다. 아래의 화면에서 각 하나씩을 x-변수와 y-변수에 선택해야 한다. Prestige 데이터셋에 있는 education (교육연수), income (수입, 연소득)을 각각 선택해보자.
Windows 사례 (10 Pro)
창에 여러가지 추가 기능과 선택사양들이 있다. 먼저 중에 , 을 선택해보자. 그리고 에 변수와 그래프를 이해하는 데 도움을 주는 내용을 입력한다. 그리고 <Point(점) 크기>, , 등의 크기를 조금씩 변경할 수 있다.
Windows 사례 (10 Pro)
scatterplot(income~education, regLine=TRUE, smooth=list(span=0.5,
spread=FALSE), boxplots=FALSE, xlab="education (교육연수)",
ylab="income (수입, 연소득)", main="교육연수와 연소득의 관계", cex.axis=1.5, cex.lab=1.5,
data=Prestige)새로운 그래픽장치 창에 산점도가 출력된다. 를 시각적으로 살펴보고자 한 목적으로 점들의 분포와 추가된 최소제곱선, 평활선 등을 점검한다. 교육연수와 연소득의 관계의 방향, 크기 및 경향성 등에 대한 통찰력을 키울 수 있다.
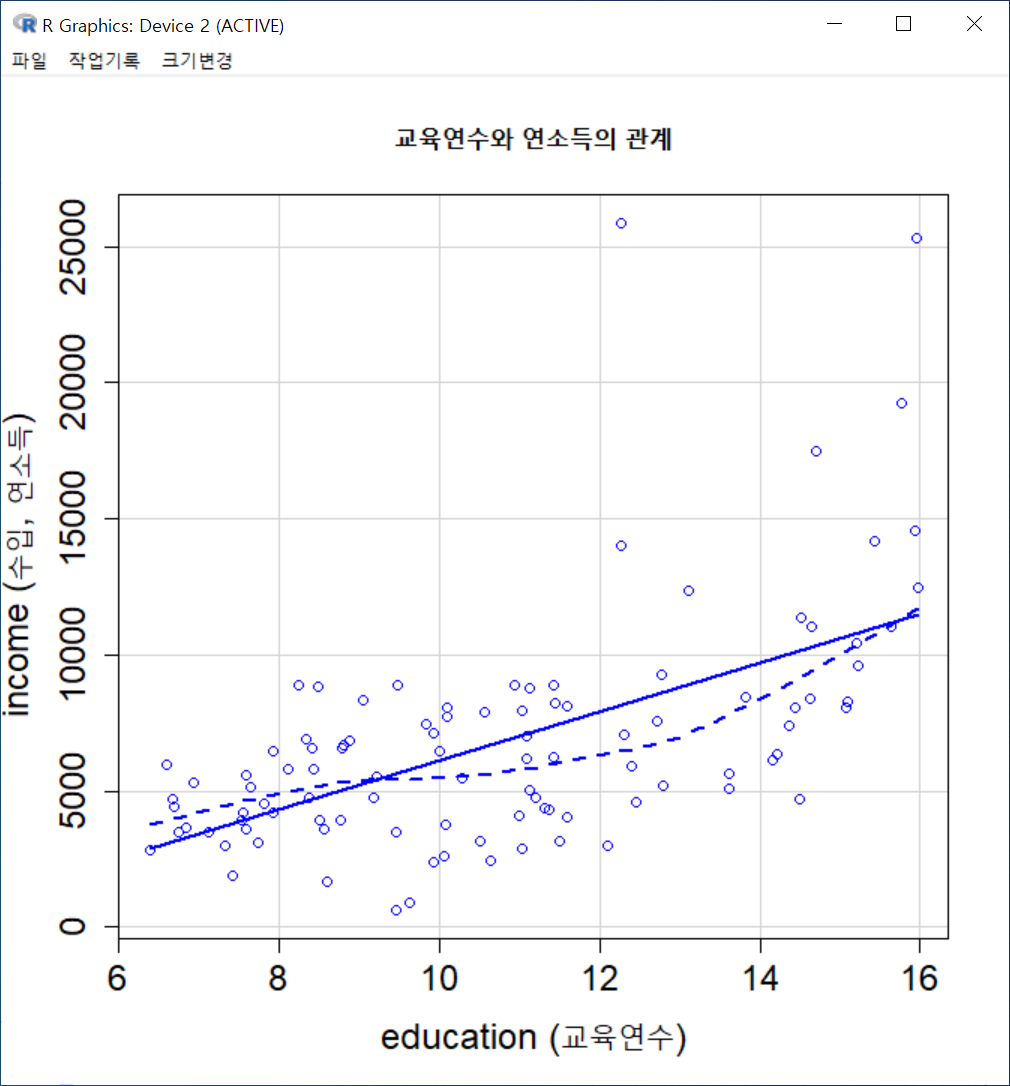
Windows 사례 (10 Pro)
한편, 산점도에 요인형 변수의 수준별로 나누어 시각화를 할 수 있다. Prestige 데이터셋에는 type 이라는 요인형 변수가 있는데, 직업유형에 따른 를 보다 미시적으로 살펴볼 수 있다. 그리고 x-축, y-축 이름 옆에 을 추가하여 각 변수들의 수치적 특징을 추가할 수 있다.
scatterplot(income~education | type, regLine=TRUE, smooth=list(span=0.5,
spread=FALSE), boxplots='xy', xlab="education (교육연수)", ylab="income (수입,
연소득)", main="교육연수와 연소득의 관계", cex.axis=1.5, cex.lab=1.5, by.groups=TRUE,
data=Prestige)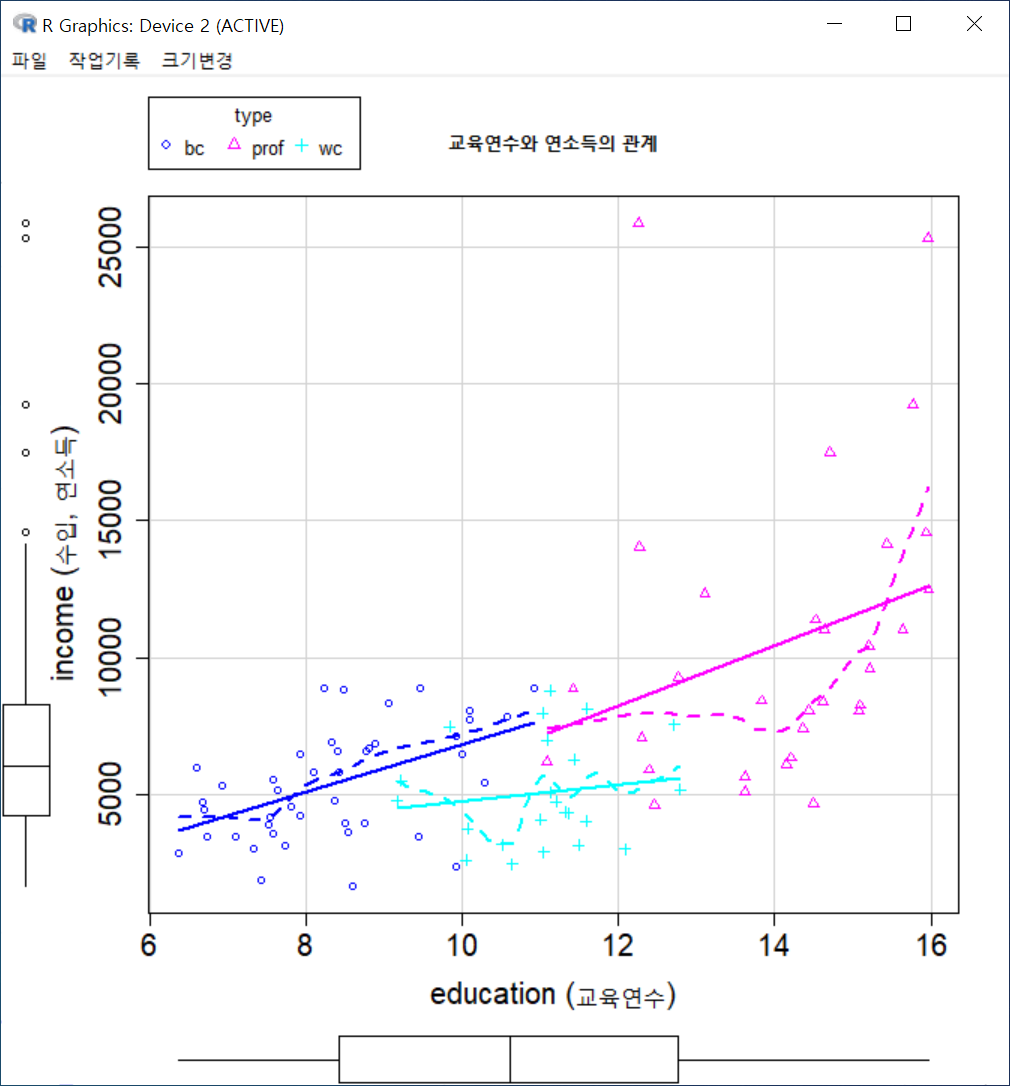
Windows 사례 (10 Pro)
8.11 산점도 행렬…/ Scatterplot matrix…
Windows 사례 (10 Pro)
산점도(Scatterplot)는 두개의 수치형 변수 사이의 관계성을 시각적으로 보면서 통찰력을 얻고자 하는 기법이다. 그런데 세개 이상의 수치형 변수들을 함께 점검하면서 관계성을 시각화하고자 할 때, 산점도의 이용은 다소 불편함이 생긴다. 이 때 산점도 행렬(Scatterplot matrix)을 사용한다.
Prestige 데이터셋에서 네개의 수치형 변수를 점검한다고 하자. 교육연수, 연소득, 직업권위의식, 여성참여율 등과 관련된 변수들 네개를 선택하자.
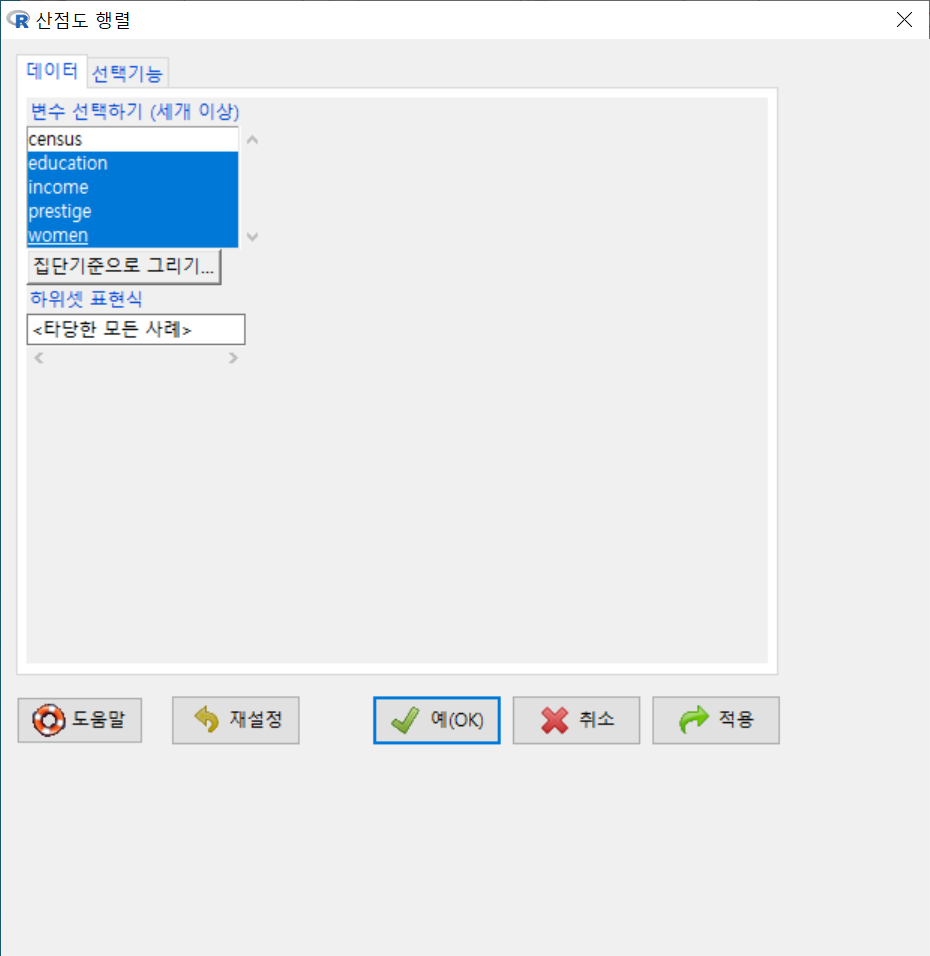
Windows 사례 (10 Pro)
창에서 는 을 선택하고, 에서는 , 을 선택하고, 그래프 제목을 추가한다.
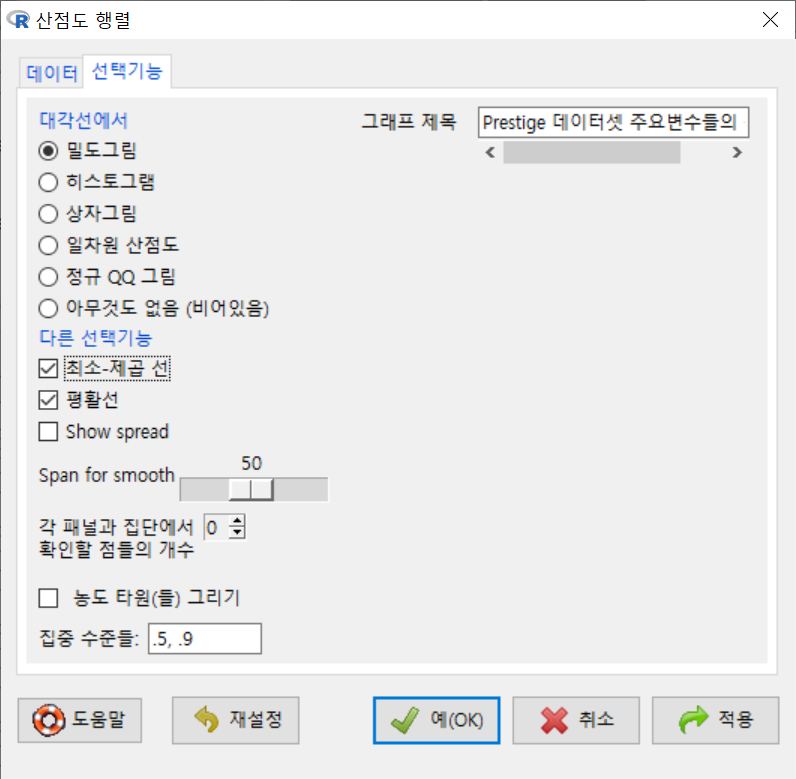
Windows 사례 (10 Pro)
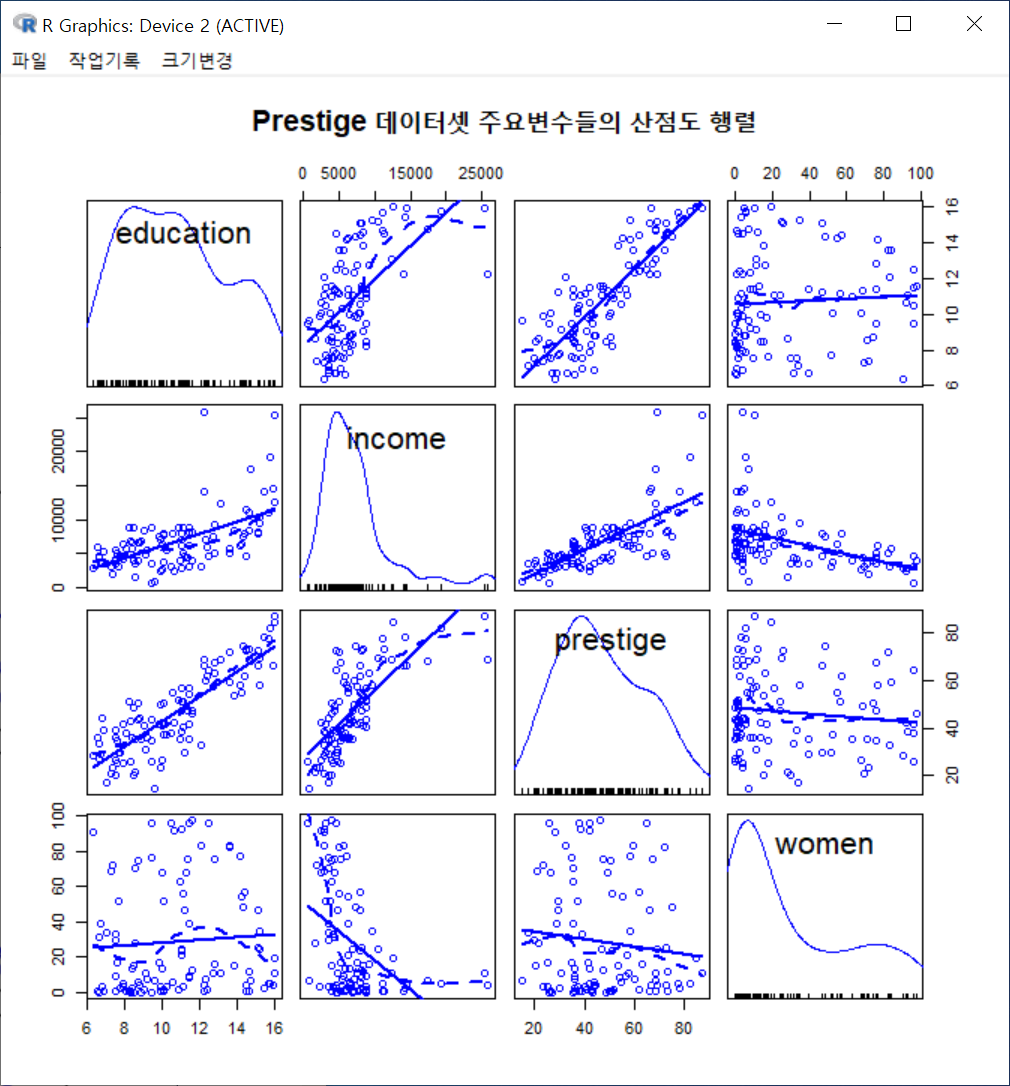
scatterplotMatrix(~education+income+prestige+women, regLine=TRUE,
smooth=list(span=0.5, spread=FALSE), diagonal=list(method="density"),
data=Prestige, main="Prestige 데이터셋 주요변수들의 산점도 행렬")아래와 같은 그래픽장치 창에 산점도 행렬이 등장한다. education, income, prestige, women 이라는 네개의 변수 각각의 밀도함수가 변수 이름과 함께 작성되어 있으며, 행렬 매 칸마다 두개의 변수 사이의 산점도가 제공된다. 행렬 칸 바깥에 있는 숫자들은 수치형 변수들의 사례 값 범위를 요약해서 보여준다.
Windows 사례 (10 Pro)
산점도행렬에는 많은 정보가 담겨있다. 확인하고자 하는 정보만을 부각시키고자 산점도행렬을 단순화시키는 노력이 요구된다.
8.12 선 그래프…/ Line graph…
Windows 사례 (10 Pro)
선 그래프(Line graph/ lineplot)는 주로 시계열적인 흐름을 가진 수치형 변수의 변화를 점검할 때 사용한다.
carData 패키지에 있는 Bfox 데이터셋을 활성화시키자. Bfox 데이터셋이 활성화된 후, R Commander 화면에서 버튼을 눌러보자. 행의 이름이 연속형 숫자인 연도로 되어있다.
연도형 행 이름을 time 이라는 변수로 전환시켜보자. 아래 창의 을 참고하라.
data(Bfox, package=“carData”) Bfox$time <- with(Bfox, as.numeric(rownames(Bfox)))
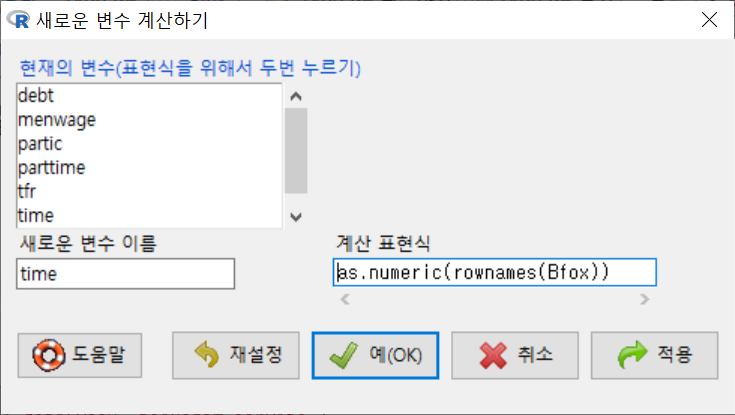
Windows 사례 (10 Pro)
아래와 같이 데이터셋 내부 구성이 보일 것이다.
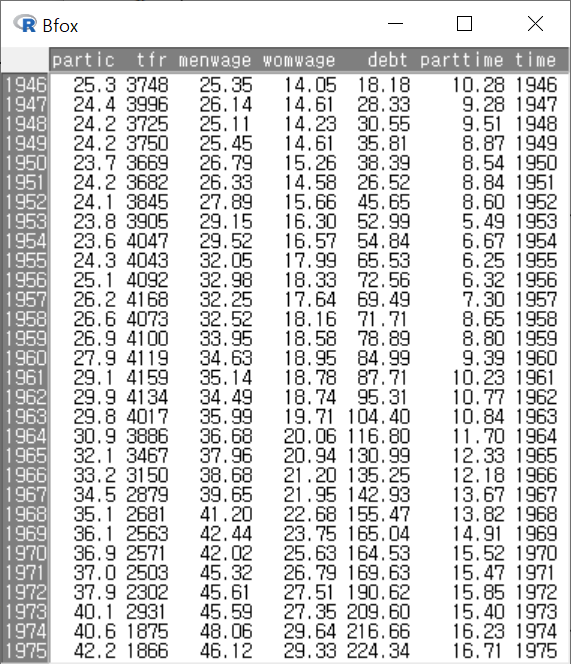
Windows 사례 (10 Pro)
Bfox 데이터셋에서 새롭게 만든 변수 time을 <x 변수 (하나 선택)>에서 선택하고, <y 변수 (하나 이상 선택)>에 주별(weekly) 남성급여, 여성급여를 뜻하는 menwage, womwage 두 변수를 선택한다. y 변수에 두개의 변수를 선택했다는 것은 두개의 선그래프가 time 변수의 흐름에 따라 만들겠다는 의미이기도 하다.
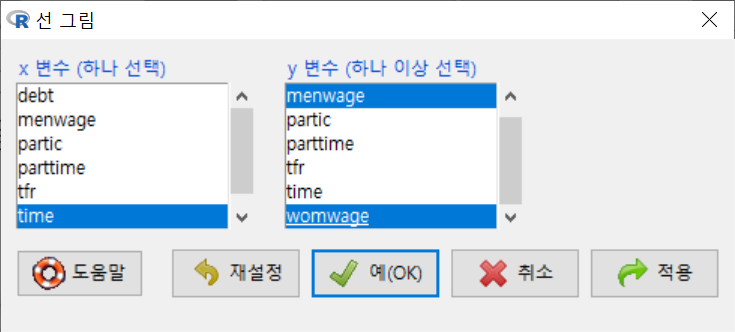
Windows 사례 (10 Pro)
with(Bfox, lineplot(time, menwage, womwage)) 그래픽장치 창에 다음과 같은 선 그래프가 출력된다. 1946년부터 1975년까지의 남성과 여성의 주급(weekly wage)의 변화를 보게된다.
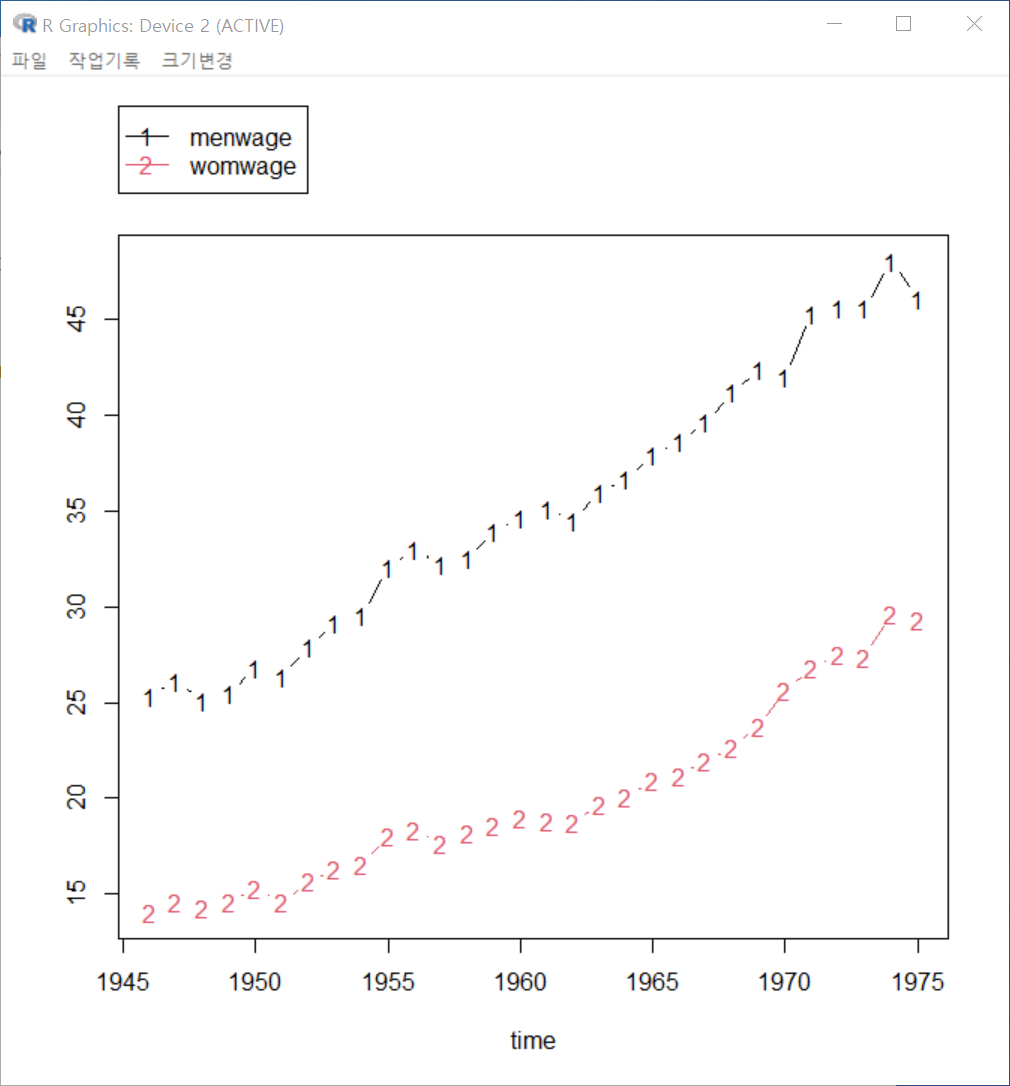
Windows 사례 (10 Pro)
또 다른 선 그래프를 만들어보자. partic은 노동인구내의 여성비율, parttime은 주당 34시간 이내의 시간제노동 비율이다. 이 두 변수의 연도별 변화 추이를 살펴보기 위하여 선 그래프를 만든다면 아래와 같을 것이다:
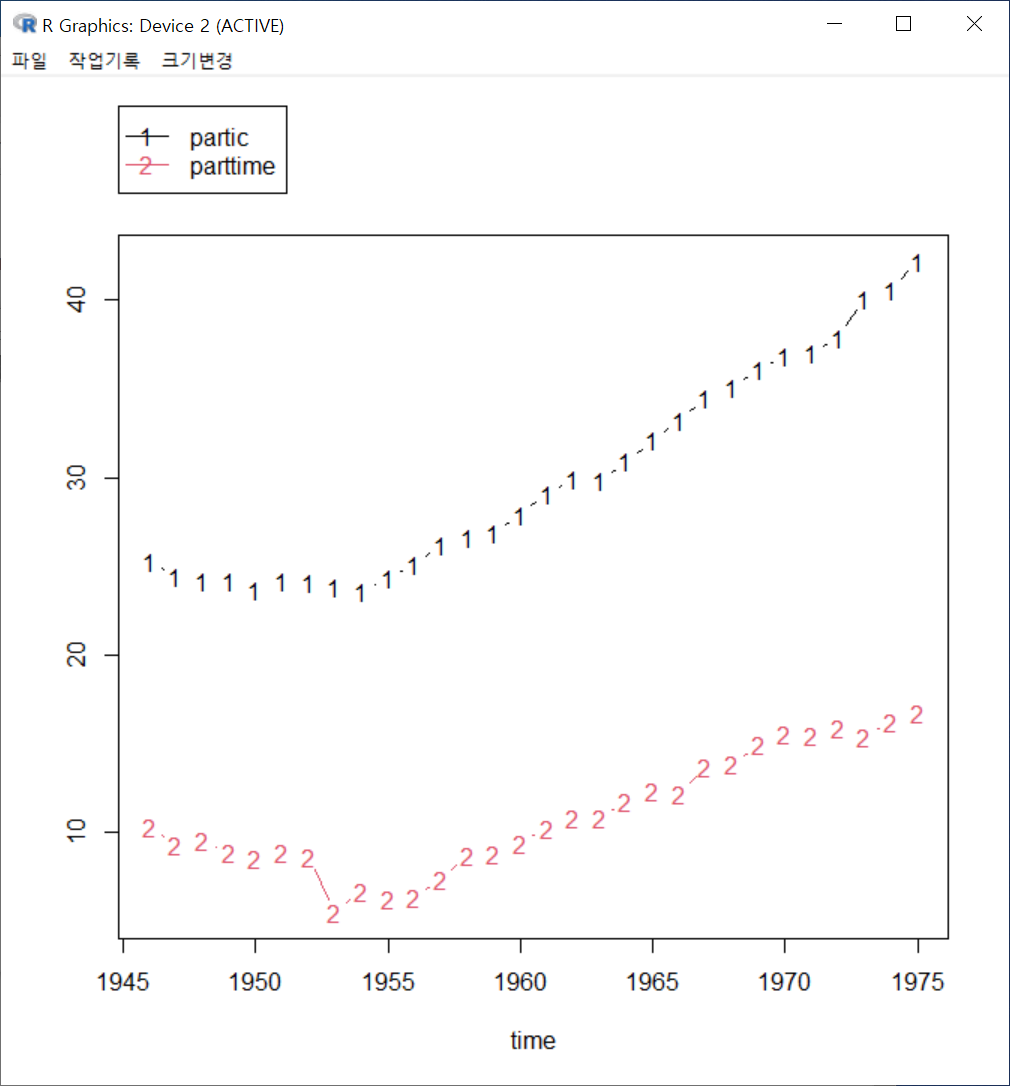
Windows 사례 (10 Pro)
선 그래프를 만드는데 가장 기본적인 출발점은 x 변수에 시간적 흐름을 갖는 변수를 선택하는 것이다. 만약 시계열적 수치형 변수가 선택되지 않는다면, 선그래프는 시사점을 가지 못하는 불규칙한 그림을 갖게 될 것이다. 예를 들어, carData에 있는 Prestige 데이터셋에는 시계열적 정보를 갖는 수치형 변수가 없다. prestige 변수를 x 변수에 놓고, education과 income을 y 변수에 놓고, 그래프를 그려보자.
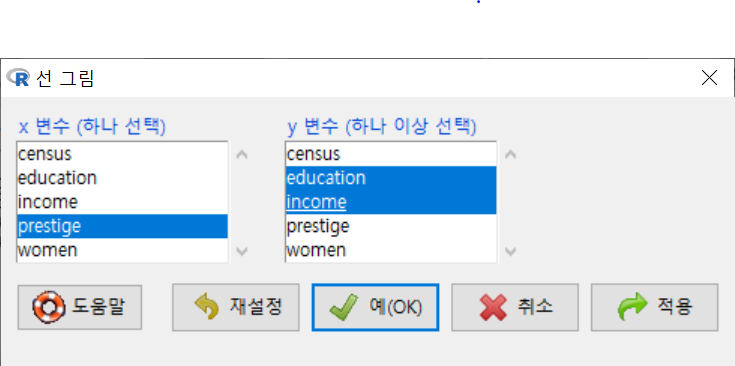
Windows 사례 (10 Pro)
다음과 같은 경고문을 만나게된다. x 변수인 prestige 변수의 사례배열에 순서가 없다는 지시문을 보게된다.
Windows 사례 (10 Pro)
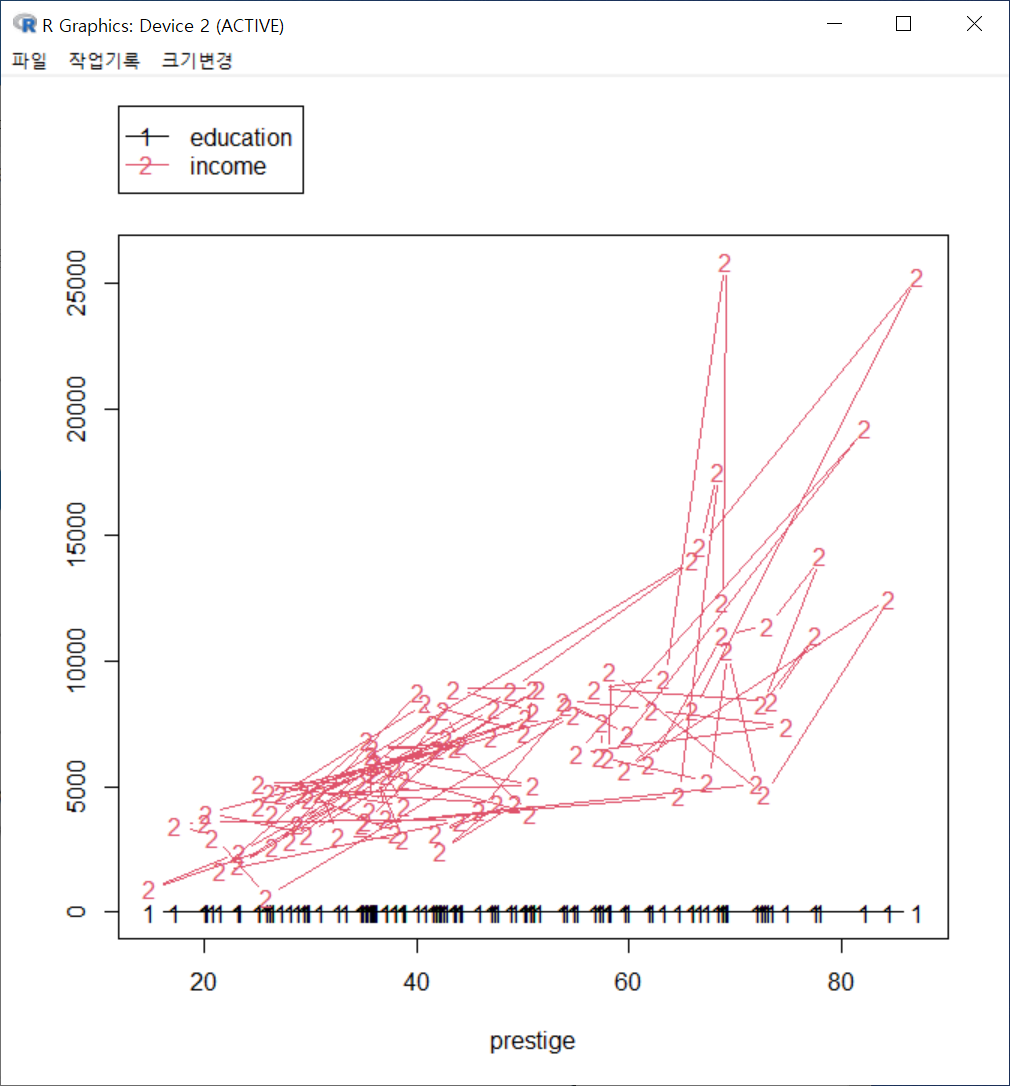
Windows 사례 (10 Pro)
8.13 XY 조건 그림…/ XY conditioning plot…
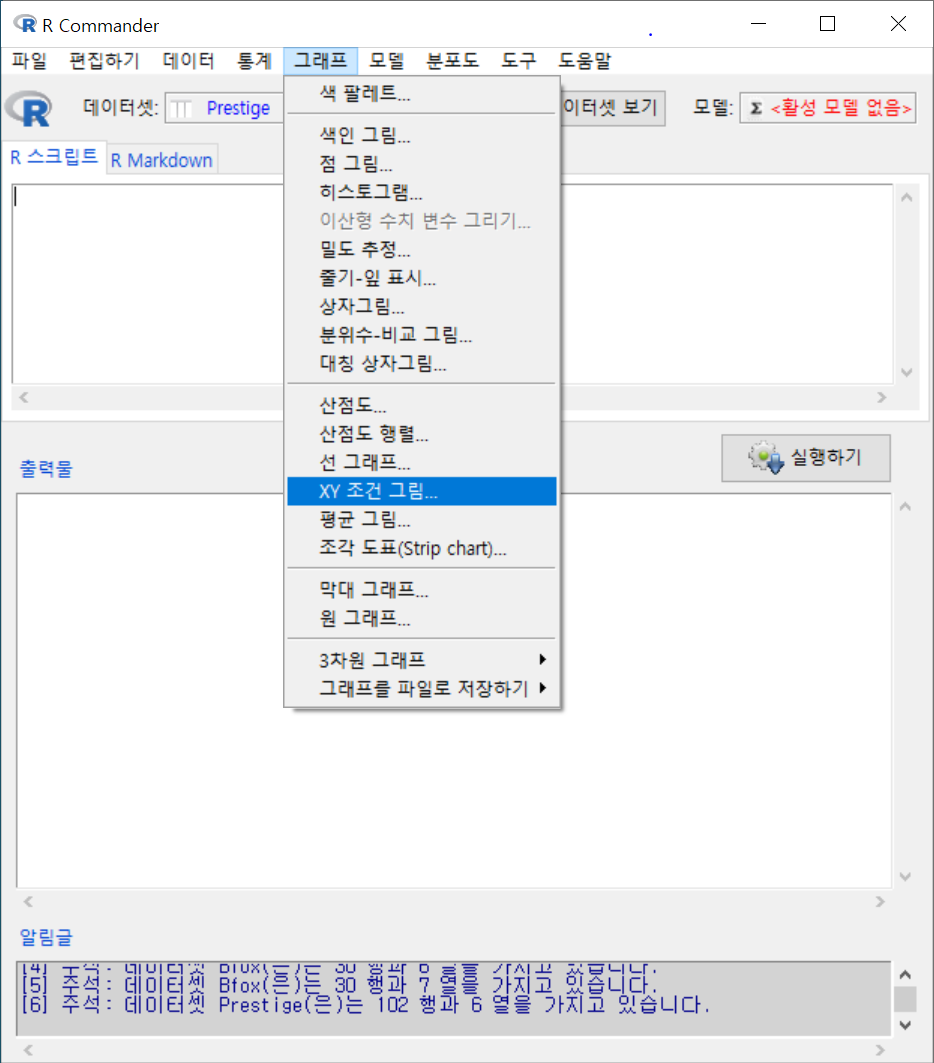
Windows 사례 (10 Pro)
carData 패키지의 Prestige 데이터셋을 활성화시키자. 연소득과 직업의 사회적귄위에 대한 이해를 확대하고자 income, prestige 변수의 연관성에 대하여 시각적으로 점검한다고 하자. bc, prof, wc라는 수준을 가진 요인형 변수 type을 집단화시켜 시각화에 포함시키자.
Windows 사례 (10 Pro)
창에 있는 많은 선택 기능은 기본설정으로 놓고 오른쪽의 에 그래프의 내용적 이해를 높이고자 관련 사항을 추가적으로 입력하자.
Windows 사례 (10 Pro)
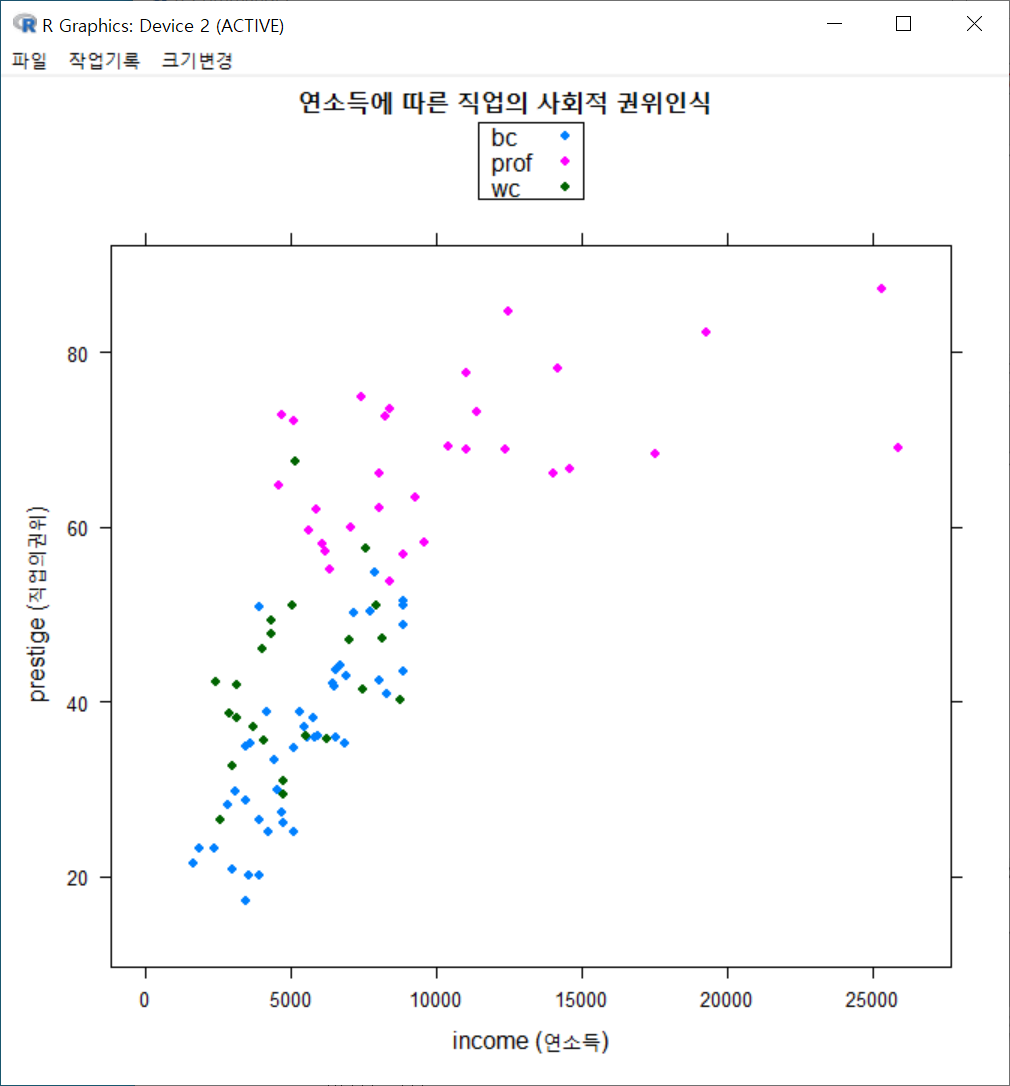
xyplot(prestige ~ income, groups=type, type="p", pch=16,
auto.key=list(border=TRUE), par.settings=simpleTheme(pch=16),
scales=list(x=list(relation='same'), y=list(relation='same')), data=Prestige,
xlab="income (연소득)", ylab="prestige (직업의권위)", main="연소득에 따른 직업의 사회적 권위인식")그래픽장치 창에 아래와 같은 그래프가 출력된다. 직업유형을 뜻하는 type 변수의 수준인 bc, prof, wc 수준의 범례가 보인다. 그리고 그 색깔별로 점들이 찍혀 있어, 추가적인 이해를 제공한다.
Windows 사례 (10 Pro)
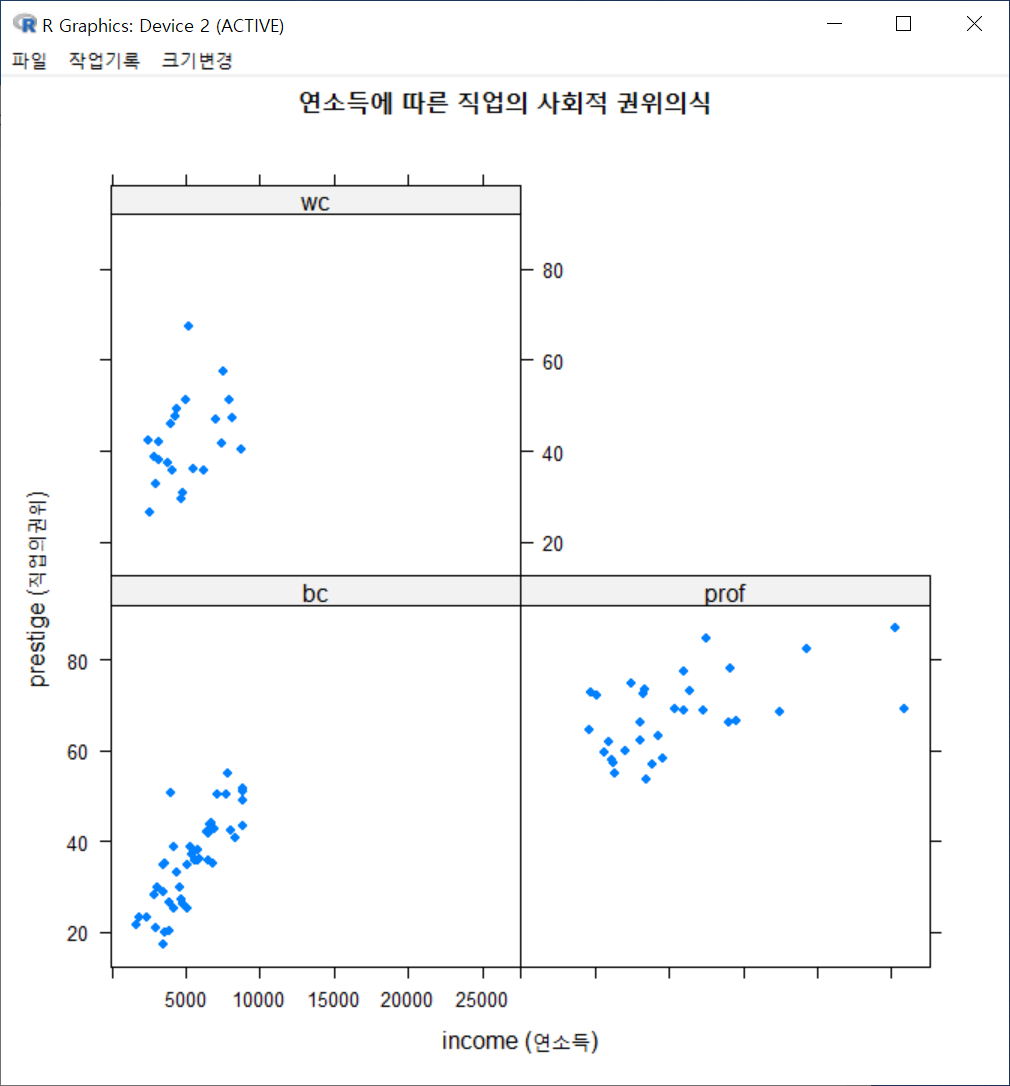
아래 그림은 직업유형 변수인 type을 “Groups ‘groups=’에서 해제하고, Conditions’|’에 선택한다.
Windows 사례 (10 Pro)
창의 오른쪽에 있는 에 내용적인 이해를 높이는 이름표과 제목을 넣자.
Windows 사례 (10 Pro)
Windows 사례 (10 Pro)
xyplot(prestige ~ income | type, type="p", pch=16, auto.key=list(border=TRUE),
par.settings=simpleTheme(pch=16), scales=list(x=list(relation='same'),
y=list(relation='same')), data=Prestige, xlab="income (연소득)", ylab="prestige
(직업의권위)", main="연소득에 따른 직업의 사회적 권위의식")아래에 있는 그래픽장치 창은 위에 있는 그래픽장치 창과 달리 직업유형별(bc, prof, wc)별로 산점도가 각각 제작된다.
Windows 사례 (10 Pro)
xyplot() 함수는 시계열적 수치형 변수와 관련해서는 lineplot()과 유사하게 그래프를 출력할 수 있다. carData 패키지의 Bfox의 사례를 수치형 time 변수로 변환시키고 그래프를 만들어보자.
Windows 사례 (10 Pro)
창에 있는 <그림 유형(하나 또는 둘 모두)>에 점/줄(선) 모두 선택해보자. 물론 에 내용을 추가할 수도 있다.
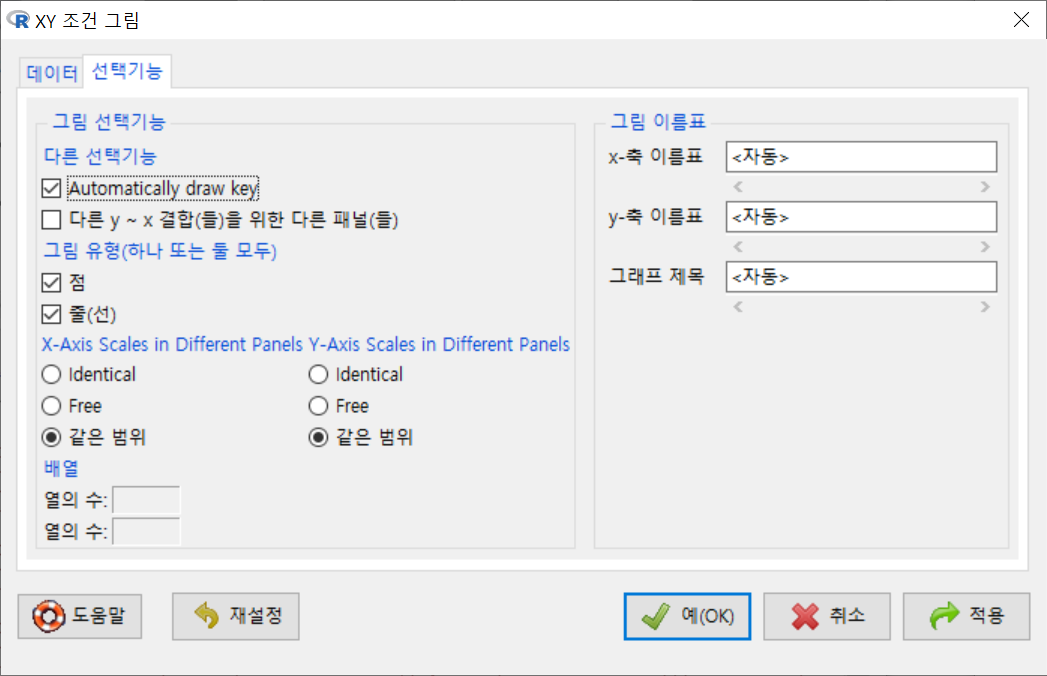
Windows 사례 (10 Pro)
xyplot(menwage + womwage \~ time, type=c("p", "l"), pch=16, auto.key=list(border=TRUE), par.settings=simpleTheme(pch=16), scales=list(x=list(relation='same'), y=list(relation='same')), data=Bfox)시간의 흐름에 따른 수치형 변수들의 변화 흐름을 파악할 수 있다. 주의해야할 점은 두개 이상의 수치형 변수를 그래프에 모두 넣을 경우, 각 변수들의 사례 기준(크기, 비율 등)이 동일해야 시각화가 특징을 잡아내는데 효과적이다.
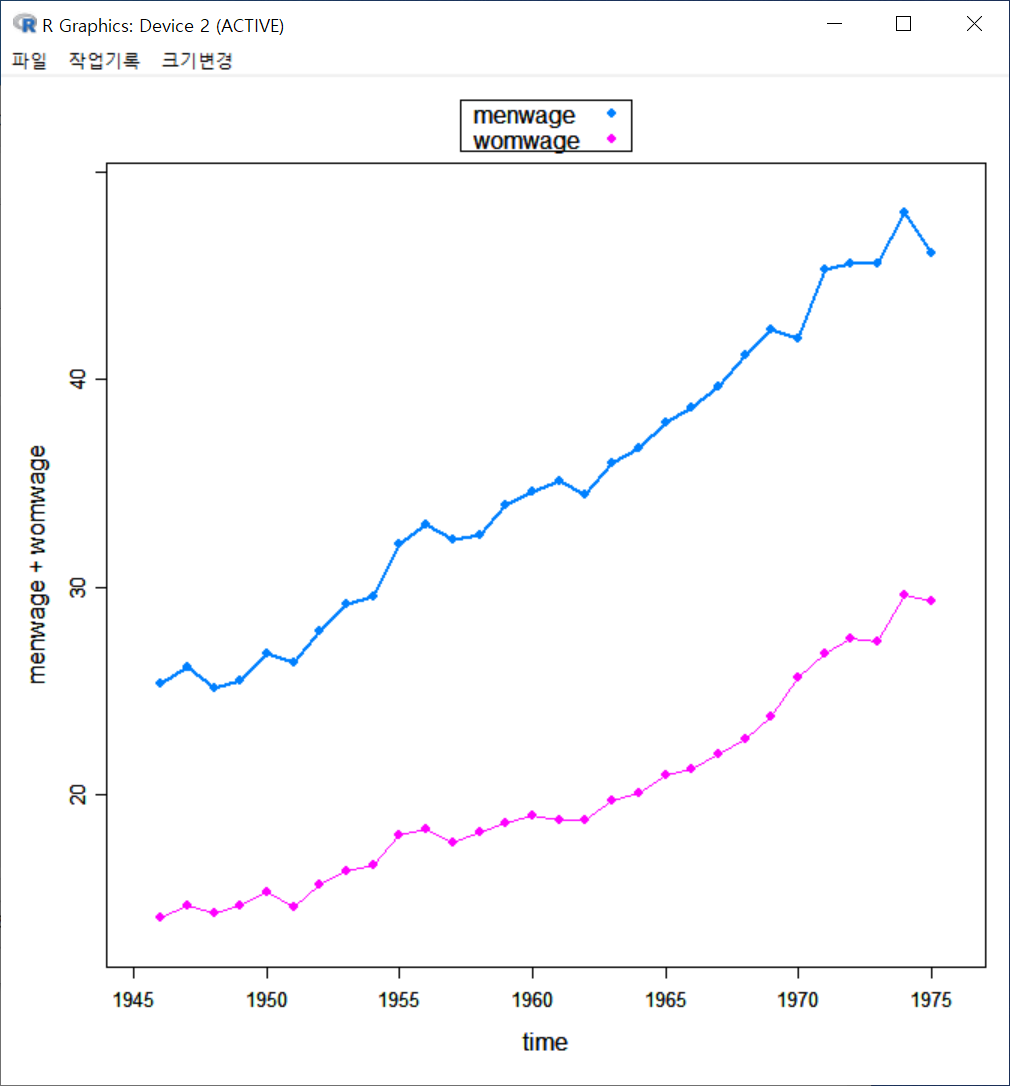
Windows 사례 (10 Pro)
8.14 평균 그림…/ Plot of means…
Linux 사례 (CentOS 7.x)
carData 패키지에 있는 Prestige 데이터셋을 활성화시키고, 그래프 메뉴창에 <평균 그림…> 기능을 선택하면 아래와 같은 추가 선택 창이 등장한다. type 이라는 요인형 변수 하나가 Prestige 데이터셋에 있어 자동 선택되며, <반응 변수 (하나 선택)>에서 income (수입, 연소득)을 선택해보자.
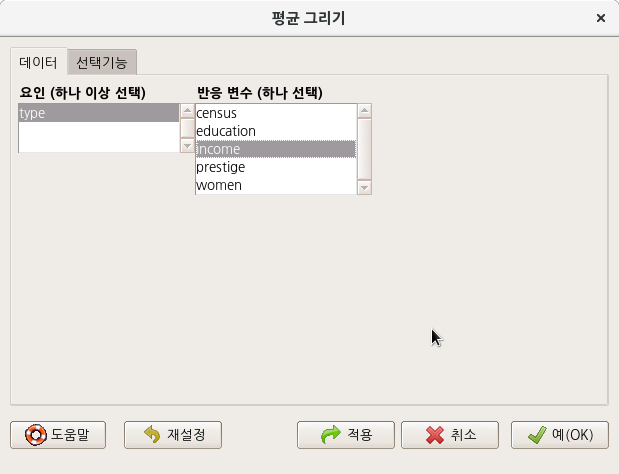
Linux 사례 (CentOS 7.x)
창에서 에 내용적 이해를 돕기 위해 변수이름, 그래프 제목에 설명을 입력하자.
Linux 사례 (CentOS 7.x)
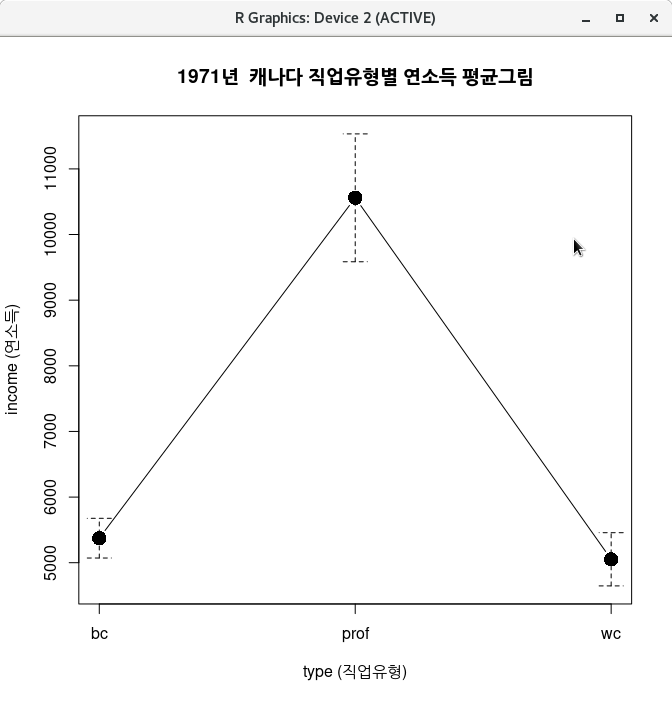
with(Prestige, plotMeans(income, type, error.bars="se", xlab="type (직업유형)",
ylab="income (연소득)", main="1971년 캐나다 직업유형별 연소득 평균그림", connect=TRUE))Prestige 데이터셋의 요인형 변수 type에는 세개의 수준이 있으며, bc, prof, wc 등이다. 아래 그래픽장치 창에는 bc, prof, wc 직업 유형에 포함된 직업들의 평균 소득을 알리는 그래프가 출력된다.
Linux 사례 (CentOS 7.x)
income 변수 대신 prestige 변수를 선택해보자. 해당 직업에 대한 사회적 권위의 크기를 표시하는 prestige 변수의 평균 그림을 직업유형 bc, prof, wc 별로 제작해 보자.
with(Prestige, plotMeans(income, type, error.bars="se",
xlab="type (직업유형)", ylab="prestige (직업권위)",
main="1971년 캐나다 직업유형별 직업권위 평균그림", connect=TRUE))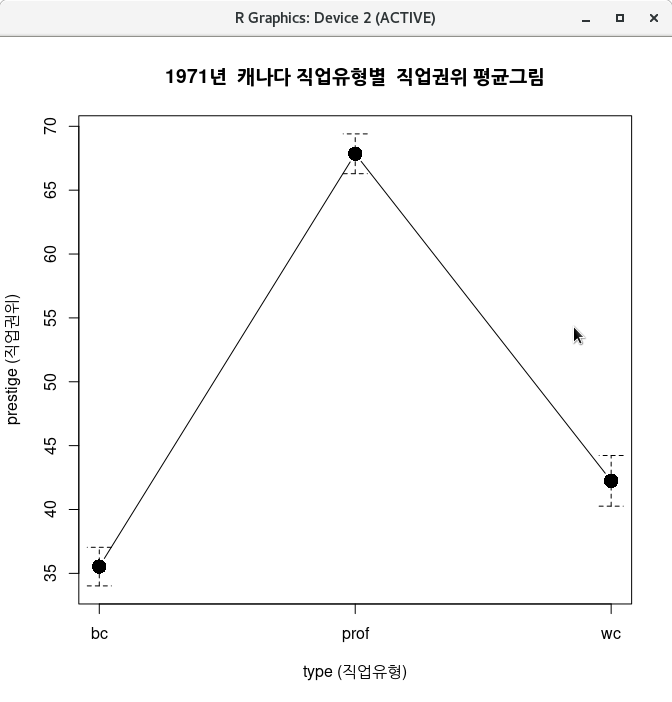
Linux 사례 (CentOS 7.x)
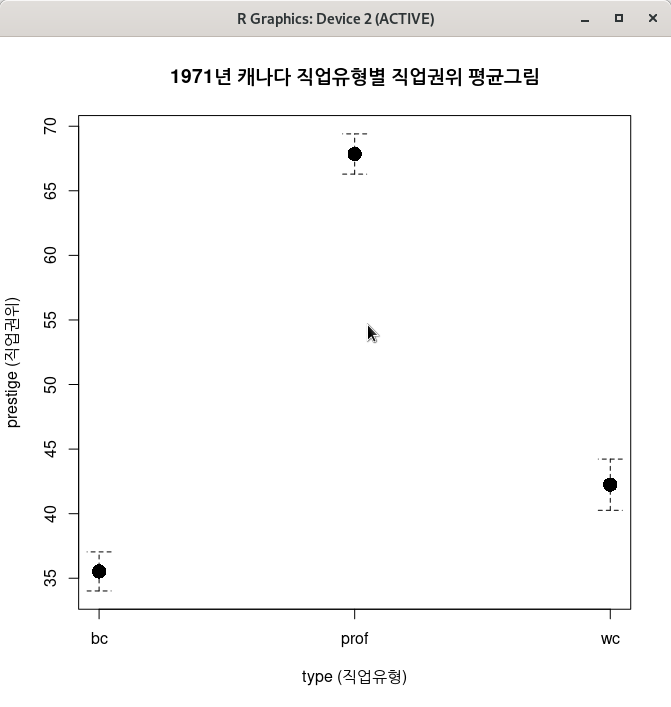
with(Prestige, plotMeans(prestige, type, error.bars="se", xlab="type (직업유형)",
ylab="prestige (직업권위)", main="1971년 캐나다 직업유형별 직업권위 평균그림", connect=TRUE))
with(Prestige, plotMeans(prestige, type, error.bars="se", xlab="type (직업유형)",
ylab="prestige (직업권위)", main="1971년 캐나다 직업유형별 직업권위 평균그림", connect=FALSE))명령문의 함수 내부를 살펴보자. 맨 마지막의 ‘connect=TRUE/FALSE’ 가 다를 것이다. 아래 메뉴 창의 맨 아래에서 에 표시를 제거해보자.
8.15 조각 도표…/ Strip chart…
Linux 사례 (CentOS 7.x)
carData 패키지에 포함된 Prestige 데이터셋을 활성화 시킨다. type 이라는 요인이 하나만 있다. <반응 변수 (하나 선택)>에서 income 변수를 선택해보자.
Linux 사례 (CentOS 7.x)
창에서, 에 있는 ’움직임(떨림)’을 선택해보자. 그리고, 에 있는 이름표와 제목에 내용 이해를 돕는 변수 이름, 설명, 제목 등을 입력한다.
Linux 사례 (CentOS 7.x)
stripchart(income ~ type, vertical=TRUE, method="jitter",
xlab="type (직업유형)", ylab="income (연소득)",
main="1971년 캐나다 직업유형별 연소득에 관한 조각 도표", data=Prestige)아래 그래픽장치 창에 ’조각 도표(Strip chart)’가 제작된다. 직업유형별로 연소득의 사례들이 크기별로 표시되어 있음을 알 수 있다.
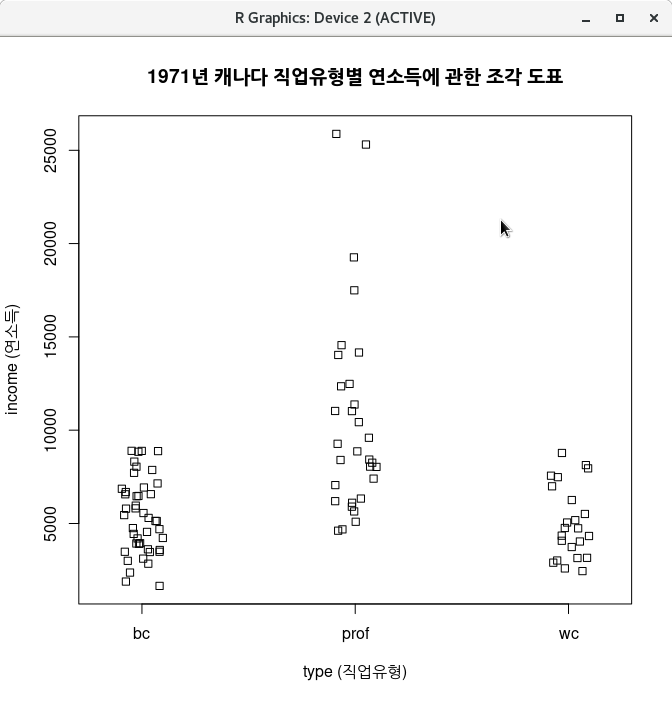
Linux 사례 (CentOS 7.x)
8.16 막대 그래프…/ Bar graph…
Linux 사례 (MX 21)
carData 패키지에 있는 Prestige 데이터셋을 활성화시키자. Prestige 데이터셋에는 요인형 변수가 한개 있다. type 변수인데 자동으로 선택된다. 만약 두개 이상이라면, 그 아래 있는 <집단 기준으로 그리기…>에서 추가적인 요인형변수를 선택할 수 있다.
Linux 사례 (MX 21)
창에 있는 에서 ’백분율’을 선택하자. 에서 ’색깔 팔레트에서’를 선택하자. 그리고 에 그래프를 이해하는 데 효과적인 이름표와 제목을 입력하자.
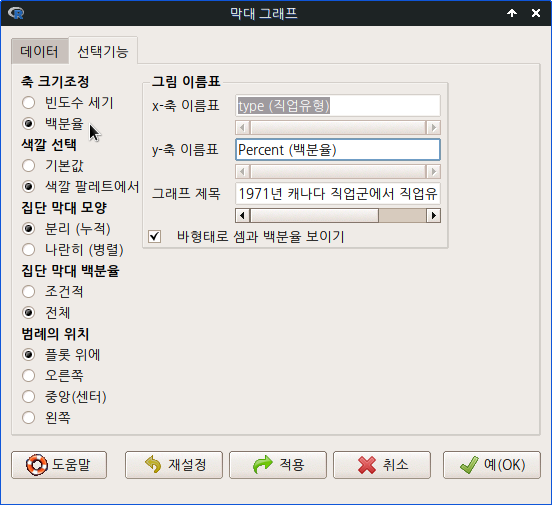
Linux 사례 (MX 21)
with(Prestige, Barplot(type, xlab="type (직업유형)", ylab="Percent",
main="1971년 캐나다 직업군에서 직업유형별 막대그래프",
col=palette()[2], scale="percent", label.bars=TRUE))아래와 같이 그래픽장치 창에 막대 그래프가 출력된다.
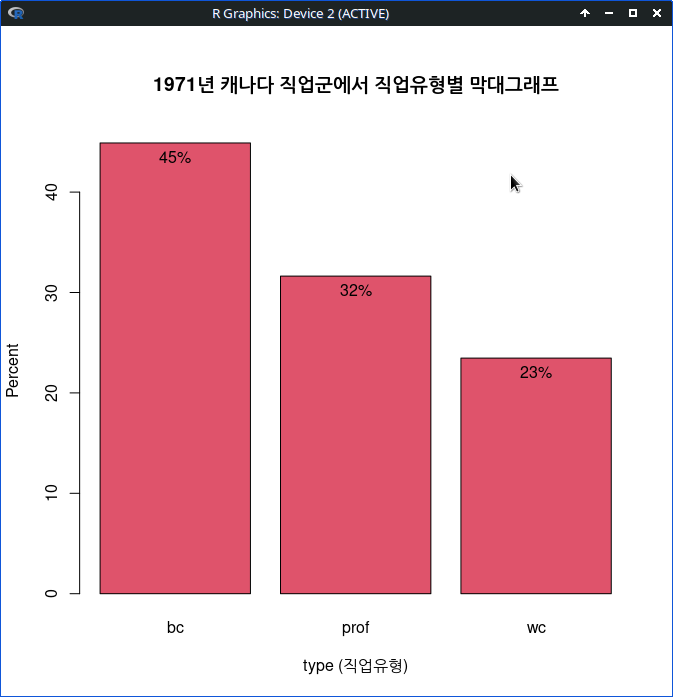
Linux 사례 (MX 21)
8.17 원 그래프…/ Pie chart…
Linux 사례 (MX 21)
carData 패키지에서 Prestige 데이터셋을 선택하여 활성화시키자. Prestige 데이터셋에는 요인형 변수가 type 하나이다. 원 그래프는 요인형 변수를 시각화할 때 사용하는 기법의 하나이다. 에서 ’색깔 팔레트에서’를 선택하고 에 내용을 이해하는데 효과적인 이름표와 제목을 입력한다.
Linux 사례 (MX 21)
with(Prestige, piechart(type, xlab="type (직업유형)", ylab="",
main="1971년 캐나다 직업군의 유형 비율", col=palette()[2:4], scale="percent"))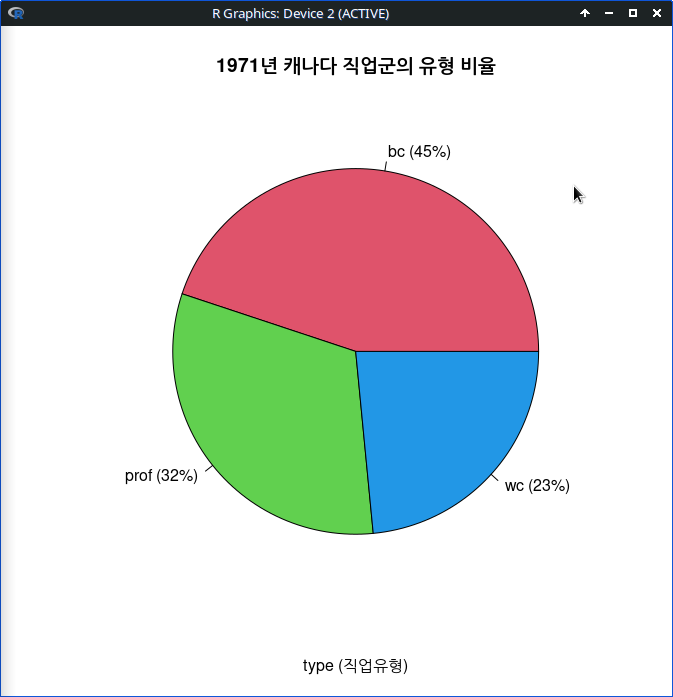
Linux 사례 (MX 21)
8.18 3D 그래프 / 3D Graph
8.18.1 3차원 산점도…/ 3D scatterplot
Linux 사례 (MX 21)
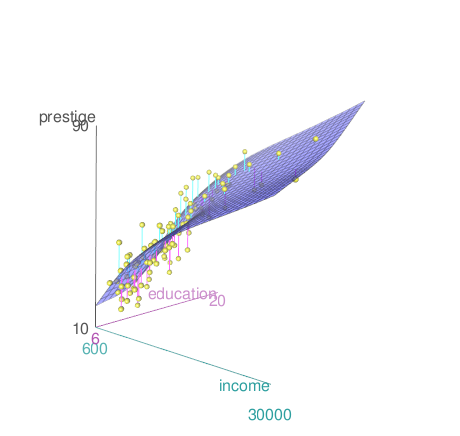
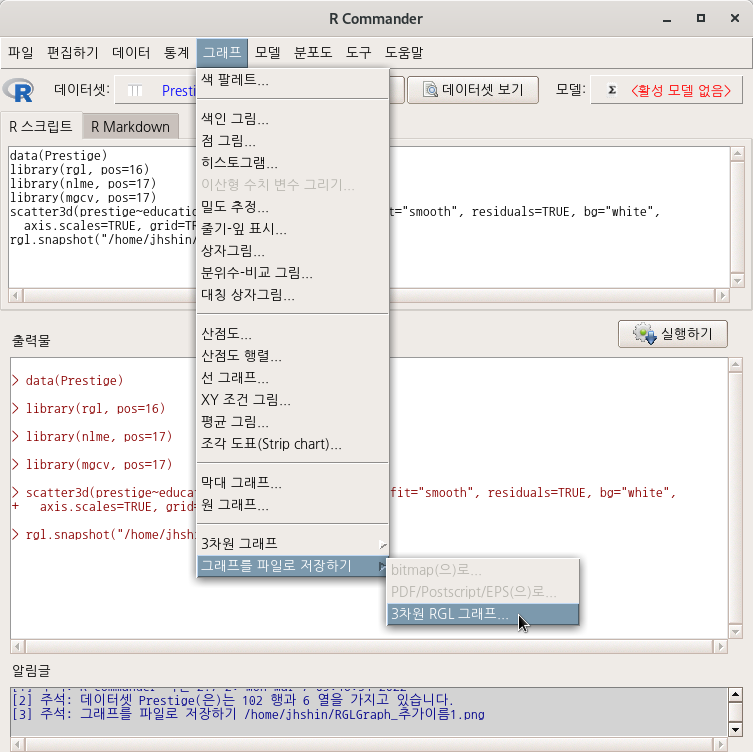
carData 패키지에 있는 Prestige 데이터셋을 활성화시키자. 교육연수와 연소득이 직업의 사회적 권위에 미치는 영향을 점검한다고 생각하자. <설명 변수 (두개 선택)>에 education, income을 <반응 변수 (한개 선택)>에 prestige 변수를 선택한다.
Linux 사례 (MX 21)
창에서 ‘축(axis) 규모 보이기’, ’표면 그리드 선 보이기’를 선택하고, 에서 ’평활 회귀’를 선택해본다.
Linux 사례 (MX 21)
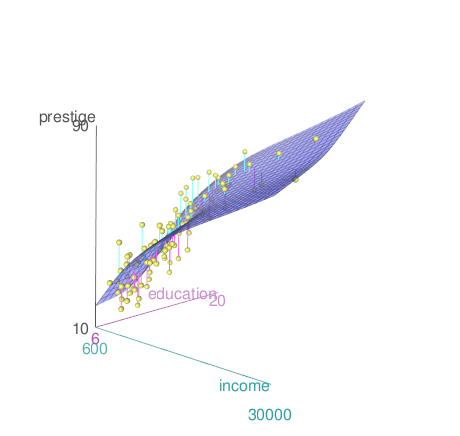
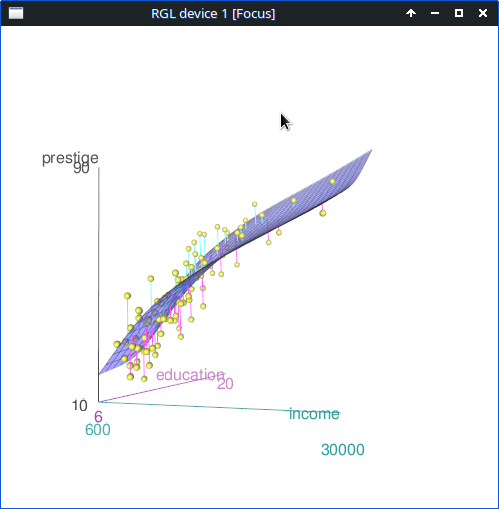
scatter3d(prestige~education+income, data=Prestige,
fit="smooth", residuals=TRUE, bg="white",
axis.scales=TRUE, grid=TRUE, ellipsoid=FALSE)아래 그래픽장치 창에 등장하는 3차원 산점도는 회전을 시켜서 최적의 시점(perspective)을 찾을 수 있다.
Linux 사례 (MX 21)