| 순위 | 함수 | 스프레드쉬트 갯수 | 누적 백분율(%) |
|---|---|---|---|
| 1 | SUM | 578 | 6.4% |
| 2 | + | 1,259 | 14.0% |
| 3 | - | 2,262 | 25.1% |
| 4 | / | 2,625 | 29.1% |
| 5 | * | 3,959 | 43.9% |
| 6 | IF | 4,260 | 47.3% |
| 7 | NOW | 5,322 | 59.1% |
| 8 | AVERAGE | 5,664 | 62.8% |
| 9 | VLOOKUP | 5,733 | 63.6% |
| 10 | ROUND | 5,990 | 66.5% |
| 출처: Enron's spreadsheets and related emails: A dataset and analysis | |||
12 현실세계 도구 - 엑셀
김박사가 AI Text-to-SQL 시스템을 완성하던 그 시점, 연구소 복도 건너편에서는 흥미로운 일이 벌어지고 있었다. 같은 남극 탐사 데이터(survey.db)를 받은 박연구원이 “굳이 복잡한 SQL을 배워야 하나?”라며 익숙한 엑셀을 열고 있었던 것이다.
“1930년에 가장 활발했던 탐사대원을 실명으로 보여주세요.”
김박사가 AI와 대화로 해결했던 바로 그 질문을, 박연구원은 다른 방식으로 접근했다. SQLite에서 CSV로 내보내기, VLOOKUP으로 테이블 연결하기, 필터로 1930년 데이터 걸러내기, 피벗 테이블로 집계하기… 몇 시간 후 같은 결과에 도달했지만, 그 과정에서 수많은 클릭과 실수, 그리고 “혹시 실명이 제대로 연결되었나?”하는 불안감을 경험했다.
이것이 바로 현대 데이터 분석의 역설이다. AI가 완벽한 SQL을 생성하는 시대에도, 여전히 많은 연구자들이 스프레드시트의 익숙한 격자 안에서 데이터와 씨름하고 있다. 왜 그럴까?
노트현실적 도구 선택의 지혜
전쟁은 현재 가용한 군대와 함께 가야지, 나중에 원하거나 바라는 군대와 함께 가는 것은 아니다You go to war with the army you have, not the army you might want or wish to have at a later time.
– 도널드 럼스펠트 Donald Rumsfeld
데이터 분석은 알고 있는 도구와 함께 시작하지, 필요한 도구와 함께 시작하는 것이 아니다You go to data analysis with the tools you have, not the tools you might want or wish to have at a later time.
– 제니 브라이언 Jenny Bryan
12.1 스프레드시트 진화와 현실
스프레드시트는 1979년 VisiCalc부터 시작해 Lotus 1-2-3, Excel, Google Sheets에 이르기까지 40여 년간 진화해왔다. 하지만 그 본질적 특성은 변하지 않았다: 보이는 것이 전부라는 직관성과 즉시 조작 가능한 편의성이다.
이런 특성 때문에 박연구원처럼 많은 연구자들이 AI-SQL의 존재를 알면서도 여전히 스프레드시트를 선택한다. 그들은 “SQL 문법을 익힐 시간에 분석을 끝낼 수 있다”며 학습곡선의 차이를 지적한다. 또한 클릭 한 번으로 결과를 바로 볼 수 있는 즉시성과, 필터와 정렬을 눈으로 확인하며 조작할 수 있는 시각적 편의성을 포기하기 어려워한다. 무엇보다 “동료들도 모두 엑셀을 사용한다”는 협업 환경의 현실이 그들의 선택을 더욱 굳어지게 만든다. 하지만 이런 편의성에는 숨겨진 비용이 있다.
경고엔론 24% 오류율이 주는 교훈
회계부정으로 파산한 엔론(Enron)의 유산(Hermans & Murphy-Hill, 2015)에서 가장 충격적인 발견은 전문 분석가들이 만든 스프레드시트의 24% 오류율이다. 4개 중 1개의 스프레드시트에서 오류가 발견되었으며, 이러한 오류가 담긴 스프레드시트가 매일 100개씩 이메일로 유통되었다.
엔론 스프레드시트 분석 결과: 엔론 전체 이메일 중 10%가 스프레드시트와 관련되어 있었으며, 가장 많이 사용된 함수는 SUM, +, -, /, * 등 기본 연산이었다. 특히 주목할 점은 데이터 연결 시 오류가 자주 발생하는 VLOOKUP이 5,733개의 스프레드시트에서 사용되어 상위 9위를 차지했다는 것이다. 더 심각한 문제는 한 스프레드시트의 오류가 조직 전체로 연쇄적으로 전파되는 구조적 취약성이었다.
이는 AI Text-to-SQL 시스템의 가치를 역설적으로 증명한다. AI가 생성한 SQL은 일관된 로직을 보장하지만, 스프레드시트는 인간의 실수가 누적되는 구조다. 남극 탐사 데이터를 엑셀로 분석한다면 테이블 연결 실수, 필터링 오류, 집계 공식 착오 등 동일한 문제가 반복될 가능성이 높다.
12.2 스프레드시트 참사
엑셀의 참사는 단순한 도구의 결함이 아니다. 이는 데이터의 복잡성과 도구의 한계 사이에서 발생하는 구조적 문제다. 김박사의 AI Text-to-SQL 시스템이 중요한 이유도 여기에 있다. 데이터베이스는 무결성과 일관성을 보장하지만, 스프레드시트는 사람의 논리에 의존한다.
박연구원이 엑셀을 선택하는 이유도 충분히 이해할 만하다. SQL 문법을 배울 필요 없이 바로 시작할 수 있는 즉시성과, 클릭 한 번으로 결과를 확인할 수 있는 시각적 피드백이 매력적이다. 복잡한 코드 없이 드래그 앤 드롭만으로 작업이 가능하고, 데이터베이스 설정이나 서버 관리 같은 배경 노이즈도 최소화할 수 있다.
하지만 이런 편의성에는 심각한 한계가 숨어 있다. 우선 한 사람의 실수가 전체 분석을 잘못된 방향으로 이끄는 오류 전파의 위험이 상존한다. 또한 한 사람에게 너무 많은 중요 정보가 집중되는 지식 집중 현상이 발생하고, 같은 분석을 여러 번 반복해야 하는 비효율성도 피할 수 없다. 데이터가 커질수록 성능과 안정성이 급격히 저하되는 확장성 문제도 심각하며, 어떤 버전이 최신이고 정확한지 파악하기 어려운 버전 관리의 어려움까지 더해진다.
그렇다면 박연구원은 어떻게 해야 할까? AI-SQL 시대에도 엑셀의 편의성을 살리면서 그 한계를 극복할 수 있는 방법이 있을까? 이런 근본적인 한계 때문에 역사적으로 수많은 스프레드시트 참사가 발생했다. 표 12.2 에서 보듯이, 수십만 달러에서 수십억 달러에 이르는 손실이 발생했으며, 중요한 것은 이런 사례들이 단순한 ’실수’가 아니라 시스템적 문제라는 점이다.
이런 참사를 경험한 조직들은 이제 엑셀 사용에 대한 엄격한 가이드라인을 수립했다. JP Morgan Chase는 2013년 “런던 고래” 사건(London Whale Scandal) 이후 복잡한 금융 모델링에서 엑셀 사용을 금지하고 전문 시스템으로 전환했다. 유럽투자은행(EIB)은 “엑셀 적합성 평가(Excel Suitability Assessment)” 프로세스를 도입해, 업무를 세 가지 범주로 구분한다: 엑셀 허용 업무(간단한 계산과 시각화), 제한적 허용 업무(감사 추적이 필요한 경우), 엑셀 금지 업무(핵심 리스크 관리, 대규모 데이터 처리, 규제 보고서 작성).
특히 미국 연방준비제도는 2003년 대형 모기지 업체 ’패니메이(Fannie Mae) 2.5조 달러 회계 오류 이후, “End User Computing(EUC) 통제 프레임워크”를 구축했다. 이 프레임워크는 스프레드시트를 위험도에 따라 분류하고, 고위험 스프레드시트는 반드시 독립적인 검증과 버전 관리 시스템을 거치도록 의무화했다. 이제 많은 금융기관과 대기업들이 “스프레드시트는 프로토타이핑용, 프로덕션은 데이터베이스로”라는 원칙을 철저히 지키고 있다.
| 회사 | 참사 비용 | 발생일 | 영향 | 참사 개요 |
|---|---|---|---|---|
| 옥스포드 대학 | 미확인 | '11.12월 | 학생 인터뷰 일정 지연 | 엑셀이 수식이 꼬여 인터뷰 일정이 뒤죽박죽 |
| MI5 | 미확인 | '11년 | 잘못된 전화번호 작업 | 엑셀 서식 수식이 꼬여 엉뚱한 전화번호 작업 |
| '12년 런던 올림픽 | £ 0.5백만 | '12.01월 | 티켓 환불 소동 | 수영장 10,000 티켓이 초과 판매 (엑셀 입력 오류) |
| Mouchel | £ 4.3백만 | '10.11월 | CEO 사임, 주가폭락 | 연금펀드평가 £ 4.3백만 엑셀 오류 |
| C&C Group | £ 9 백만 | '09.7월 | 주가 15% 하락 등 | 매출 3% 상승이 아니고 5% 하락, 엑셀 오류 |
| UK 교통부 | 최소 £ 50 백만 | '12.10월 | 영국민 추가 세금 부담 | 영국 철도 입찰 오류 |
| King 펀드 | £ 130 백만 | '11.05월 | 브래드 이미지 하락 | 웨일즈 지방 NHS 지출 엑셀 오류 |
| AXA Rosenberg | £ 150 백만 | '11.02월 | 은폐, 벌금, 브래드 이미지 하락 | 엑셀 오류를 감춰서 $242 백만 벌금 |
| JP Morgan Chase | £ 250 백만 | '13.01월 | 명성, 고객 신뢰도 저하 | 바젤 II VaR 위험 평가 엑셀 오류 |
| Fidelity Magellan 펀드 | £ 1.6 십억 | '95.01월 | 투자자에게 약속한 배당금 지급 못함 | 음수 부호 누락으로 자본이득 과대계상 |
| 미연방준비위원회 | £ 2.5 십억 | '10.10월 | 명확하지 않음 | 리볼빙 카드 신용액 산출 과정에 엑셀 오류 |
| 하버드 대학 | 평가 불능 | '13.04월 | 유럽 정부 긴축예산 편성 근거 | GDP 대비 정부 부채 영향도 분석 엑셀 오류 |
| 출처: the dirty dozen 12 modelling horror stories & spreadsheet disasters | ||||
반면, 데이터베이스는 사용자 활동 기록, 정형화된 작업흐름 지원, 오류 감소, 효율적인 보고서 생성 및 강력한 보안과 규제 기능을 제공한다. 따라서 엑셀 스프레드시트 대신 데이터베이스를 사용하는 것이 여러 면에서 이점을 제공한다.
12.3 스프레드시트 복잡성
중요인간과 컴퓨터 모두에게 읽기 어려운 스프레드시트
데이터 분석에서 코드는 사람과 컴퓨터 모두에게 가독성을 제공해야 하며, 데이터 역시 마찬가지여야 한다. 그러나 스프레드시트는 역설적으로 양쪽 모두에게 가독성을 제공하지 못하는 경우가 많다.

그림 12.1가 보여주는 극단적 사례가 이를 잘 설명한다. “ALGORITHMS BY COMPLEXITY” 차트에서 LEFTPAD, QUICKSORT, GIT MERGE, 자율주행차, 구글 검색 백엔드를 모두 제치고 가장 복잡한 것은 “20년간 네브래스카 교회가 일정 조정용으로 만든 거대한 엑셀 스프레드시트”다. 이는 농담이 아니라 현실이다.
스프레드시트는 처음에는 인간에게 쉽게 접근 가능해 보이지만, 불과 1주일만 지나도 해독이 불가능한 미로가 되어버린다. 컴퓨터 입장에서도 상황은 다르지 않다. 데이터, 서식, 수식이 한 공간에 뒤섞여 있어 자동 처리가 극히 어렵다. 무엇보다 심각한 것은 시간이 지날수록 복잡도가 기하급수적으로 증가한다는 점이다. 처음에는 단순했던 스프레드시트가 수정과 추가를 거듭하며 누구도 완전히 이해할 수 없는 괴물로 변해간다.
이는 단순한 기술적 문제가 아니라 구조적 문제다. 컴퓨터 프로그램은 실행 코드와 주석을 명확히 구분하지만, 스프레드시트는 데이터, 서식, 수식이 한 공간에 뒤섞여 있다.
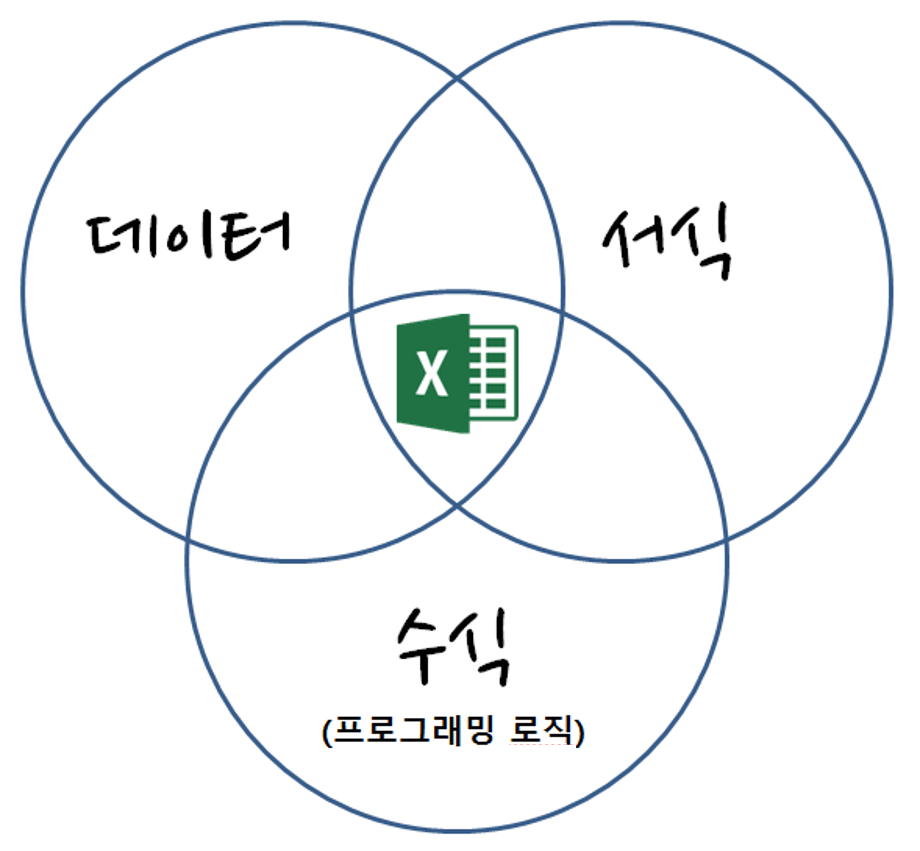
스프레드시트의 세 가지 구성요소(데이터, 서식, 수식)가 얽히면서 만드는 복잡성은 시간이 지날수록 통제 불가능한 수준에 이른다. 엑셀 내장 함수로 수식 계산을 수행하고, 서식을 입히는 과정에서 원래의 데이터 구조는 점점 모호해진다.
12.4 데이터베이스 해법
박연구원이 남극 탐사 데이터를 엑셀로 분석하던 중 또 다른 문제에 부딪혔다. 연구소에서 추가로 서지학 데이터베이스를 분석해달라는 요청이 들어온 것이다. 2,937개의 논문 정보가 담긴 bibliography.csv 파일을 받아들고, 두 가지 질문에 답해야 했다:
- 각 연구자가 기여한 논문 수는?
- 누가 누구와 협업하는가?
문제는 저자 정보가 “McClelland, J. L.; McNaughton, B. L.; O’Reilly, R. C.”처럼 한 필드에 여러 명이 섞여 있는 “다중 값 필드(multi-valued field)” 형태였다. 이런 데이터는 바로 데이터베이스에 넣을 수 없어 “추출(Extract), 변환(Transform), 로드(Load)” 즉 ETL 과정이 필요했다.
박연구원이 엑셀로 접근한다면 2,937개 행을 하나씩 검토하며 저자를 분리하고, VLOOKUP으로 연결하고, 피벗 테이블로 집계해야 한다. 한 명의 저자만 분석하는 데도 30분, 전체를 처리하려면 며칠이 걸릴 것이다. 더 큰 문제는 99% 정확도를 달성하려면 행당 오류율을 0.000342% 이하로 유지해야 한다는 점이다. 이는 인간에게는 불가능한 수준이다.
노트바흐라이(Bahlai) 법칙
“다른 사람의 데이터는 항상 일관성이 없고 잘못된 형식으로 되어 있다.”
이것이 바로 ETL이 필요한 이유다. 원본 데이터를 그대로 사용할 수 없기에, 변환 과정이 필수적이다.
12.4.1 ETL 구현
김박사는 이 문제를 체계적으로 접근했다. 많은 개발자들이 바로 복잡한 파싱 로직부터 시작하지만, 그는 기본기를 중시했다. 데이터를 다루기 전에 먼저 데이터의 전체 규모와 구조를 파악하는 것이 중요하다고 믿었기 때문이다. 그의 첫 번째 작업은 CSV 파일이 올바르게 읽히는지 확인하는 것이었다.
# count-lines.py - 데이터 무결성 확인
import sys
filename = sys.argv[1]
reader = open(filename, 'r')
count = 0
for line in reader:
count += 1
reader.close()
print(count) # 결과: 2937간단해 보이는 스크립트는 ETL 프로세스의 핵심 원칙을 담고 있다. 데이터를 신뢰하지 말고 항상 검증하라는 것이다. 2,937행이라는 숫자는 단순한 카운트가 아니라 앞으로 처리해야 할 작업의 규모를 의미한다. 만약 파일이 손상되었거나 중간에 잘렸다면, 이 단계에서 바로 발견할 수 있다. 김박사는 이런 기본적인 검증 없이 복잡한 파싱을 시작했다가 나중에 데이터 누락을 발견한 경험이 있었기 때문에, 항상 이 단계를 거쳤다.
다음 단계는 CSV의 각 필드를 올바르게 파싱하는 것이었다. 여기서 김박사는 초보자들이 흔히 저지르는 실수를 피했다. CSV 파일을 단순히 콤마로 나누어 처리하려는 유혹을 뿌리쳤던 것이다. 저자명 자체에 콤마가 포함되어 있어(“McClelland, James L” 같은 “성, 이름” 형식) 단순한 str.split으로는 처리할 수 없었기 때문이다.
# read-fields.py - CSV 래퍼(wrapper) 활용
import sys
import csv
raw = open(sys.argv[1], 'r')
reader = csv.reader(raw) # 래퍼 생성
for line in reader:
print(line[0], line[3]) # 키값과 저자 추출
raw.close()이 코드에서 csv.reader는 단순한 파일 읽기 도구가 아니라 복잡한 CSV 파싱 로직을 캡슐화한 “래퍼(wrapper)”다. 래퍼 패턴은 소프트웨어 개발에서 기존 인터페이스를 감싸서 더 사용하기 쉽게 만드는 디자인 패턴이다. csv.reader는 파일에서 읽어온 원시 텍스트를 받아서, 따옴표로 감싸진 필드, 이스케이프 문자, 내장된 콤마 등의 복잡한 CSV 규칙을 모두 처리해준다. 김박사는 “바퀴를 다시 발명하지 말라”는 원칙을 철저히 따랐고, 이미 잘 만들어진 라이브러리를 활용했다.
8SW85SQM McClelland, James L
85QV9X5F McClelland, J. L.; McNaughton, B. L.; O'Reilly, R. C.
Z4X6DT6N Ratcliff, R.이 출력 결과를 보면서 김박사는 안도했다. 키값(첫 번째 필드)과 저자명(네 번째 필드)이 정확히 추출되었고, 저자명 내의 콤마도 올바르게 보존되었다. 두 번째 행처럼 여러 명의 저자가 세미콜론으로 구분된 경우도 하나의 필드로 정확히 파싱되었다. 만약 단순 문자열 분할을 사용했다면, “McClelland, J. L.”과 ” McNaughton, B. L.” 사이의 콤마에서 잘못 분할되었을 것이다.
마지막 단계는 여러 저자를 개별 레코드로 분리하는 것이었다. 이것이 진정한 ETL의 “변환(Transform)” 단계였다. 하나의 논문에 여러 저자가 있는 경우, 각 저자를 별도의 행으로 만들어야 했다. 이는 관계형 데이터베이스의 정규화 원칙을 따르는 것이다.
# display-authors-2.py - 다중값 필드 정규화
import sys
import csv
raw = open(sys.argv[1], 'r')
reader = csv.reader(raw)
for line in reader:
key, authors = line[0], line[3]
for auth in authors.split('; '): # 세미콜론과 공백으로 분리
print(key, auth)
raw.close()이 코드에서 주목할 점은 '; '로 분할한다는 것이다. 처음에는 ;만 사용했지만, 그러면 두 번째 저자부터 이름 앞에 공백이 남게 된다. 김박사는 이런 세부사항을 놓치지 않았다. 데이터 품질은 이런 작은 디테일에서 결정되기 때문이다. 최종 결과에서 “McNaughton, B. L.” 앞에 원치 않는 공백이 있다면, 나중에 데이터베이스 쿼리에서 정확한 매칭이 어려워질 수 있다.
12.4.2 데이터베이스 생성
이제 추출된 데이터를 데이터베이스에 로드할 차례였다. 김박사는 여기서 흥미로운 선택을 했다. Python의 sqlite3 라이브러리를 사용해서 직접 데이터베이스에 연결하고 데이터를 삽입하는 것이 일반적인 방법이지만, 그는 더 간단하고 투명한 접근법을 택했다. SQL INSERT 문장을 생성해서 텍스트로 출력한 다음, 유닉스 파이프를 통해 SQLite에 전달하는 것이었다.
# convert-2.py - SQL 문장 생성
import sys
import csv
CREATE = 'create table data(key text not null, author text not null);'
INSERT = 'insert into data values("{0}", "{1}");'
print(CREATE)
raw = open(sys.argv[1], 'r')
reader = csv.reader(raw)
for line in reader:
key, authors = line[0], line[3]
for auth in authors.split('; '):
print(INSERT.format(key, auth))
raw.close()이러한 접근법의 우아함은 단순함에 있었다. CREATE 문장은 테이블 구조를 정의한다: key와 author 두 개의 텍스트 필드로, 둘 다 NULL 값을 허용하지 않는다. INSERT 템플릿은 형식 문자열(format string)로, {0}과 {1} 자리표시자가 각각 논문 키와 저자명으로 치환된다. 이런 방식은 생성될 SQL을 명확히 볼 수 있어 디버깅이 쉽고, 필요시 생성된 SQL을 파일로 저장해서 다른 데이터베이스 시스템에서도 실행할 수 있다는 장점이 있다.
하지만 김박사는 실제 데이터를 처리하면서 한 가지 문제를 발견했다. 저자명에 아포스트로피가 들어있는 경우였다. “O’Mear, Fiona”와 같은 이름이 있다면, 생성되는 SQL은 insert into data values("RJS8QDC4", "O'Mear, Fiona");가 된다. 여기서 문제는 없지만, 만약 단일 인용부호를 사용했다면 insert into data values('RJS8QDC4', 'O'Mear, Fiona');가 되어 SQLite 파서가 혼란스러워할 것이다. 아포스트로피에서 문자열이 끝난다고 판단하기 때문이다.
경고문자열 이스케이핑의 함정
저자명에 단일 인용부호가 들어있을 수 있어(예: “O’Mear, Fiona”) SQL 파싱 오류가 발생할 수 있다. 이중 인용부호를 사용하거나 prepared statement를 활용해야 한다. 실제 프로덕션 환경에서는 SQL 인젝션 공격을 방지하기 위해 매개변수화된 쿼리를 사용하는 것이 필수다.
김박사는 이 문제를 이중 인용부호로 해결했다. 사람 이름에 이중 인용부호가 들어가는 경우는 극히 드물기 때문이다. 하지만 그는 이것이 완벽한 해결책이 아니라는 것을 알고 있었다. 진정한 해결책은 prepared statement나 ORM을 사용하는 것이지만, 이번 경우에는 실용적인 접근법이 더 적절했다.
파이프라인을 통해 데이터베이스를 생성하는 순간이 왔다:
python convert-2.py bibliography.csv | sqlite3 bibliography.db이 한 줄의 명령어는 유닉스 철학의 정수를 보여준다. 하나의 프로그램이 한 가지 일을 잘 하고, 여러 프로그램을 조합해서 복잡한 작업을 수행한다는 것이다. convert-2.py는 SQL 문장을 생성하는 일에만 집중하고, sqlite3는 그 문장들을 실행해서 데이터베이스를 만드는 일에만 집중한다. 파이프(|)를 통해 두 프로그램이 우아하게 연결된다.
실행 결과는 놀라웠다. 4초 만에 205KB의 bibliography.db 파일이 생성되었다. 2,937개의 원본 행이 저자별로 분리되어 약 7,000개의 레코드로 변환되었다. 박연구원이 같은 작업을 엑셀에서 한다면? 각 행을 열어서 저자를 확인하고, 새로운 행을 만들고, 복사-붙여넣기를 반복해야 할 것이다. 최소 하루는 걸릴 작업이었다.
데이터베이스가 생성되자마자 김박사는 첫 번째 질문에 대한 답을 구했다:
-- 가장 활발한 저자 Top 10
SELECT author, COUNT(*)
FROM data
GROUP BY author
ORDER BY COUNT(*) DESC
LIMIT 10;
-- 결과
Bengio, Yoshua|122
Bengio, Y.|111
Hinton, Geoffrey E.|78
LeCun, Yann|56이 결과를 보는 순간 김박사는 두 가지를 깨달았다. 첫째, SQL의 GROUP BY와 집계 함수 COUNT(*)의 조합이 얼마나 강력한지였다. 단 한 줄의 쿼리로 2,937개 논문에서 각 저자의 기여도를 계산했다. 둘째, 데이터 정규화 문제가 여전히 남아있다는 것이었다. “Bengio, Yoshua”와 “Bengio, Y.”는 거의 확실히 동일인이지만 다른 저자로 카운트되고 있었다. 이는 원본 데이터의 역정규화(denormalization) 문제였다.
박연구원이 같은 질문에 답하려면 엑셀에서 어떻게 해야 할까? VLOOKUP이나 피벗 테이블을 사용할 수 있지만, 먼저 저자명을 분리하는 작업을 수동으로 해야 한다. 김박사의 4초짜리 쿼리 한 번이면 끝날 일을, 박연구원은 몇 시간에 걸쳐 처리해야 할 것이다.
12.4.3 협업 관계 분석
두 번째 질문 “누가 누구와 협업하는가?”에 대해 김박사는 AI의 도움을 받아 더 정교한 쿼리를 작성했다. 이 질문은 단순한 집계를 넘어서 관계형 데이터베이스의 진정한 힘을 보여주는 영역이었다. 같은 논문에 공동 저자로 참여한 연구자들 사이의 협업 네트워크를 분석하는 것이다.
-- 공동 저자 관계 분석
SELECT a.author, b.author, COUNT(*) as collaboration_count
FROM data a
JOIN data b ON a.key = b.key AND a.author > b.author
GROUP BY a.author, b.author
ORDER BY collaboration_count DESC
LIMIT 10;
-- 결과
Vincent, Pascal|Bengio, Yoshua|27
Roux, Nicolas Le|Bengio, Yoshua|20
Delalleau, Olivier|Bengio, Yoshua|19이 쿼리의 우아함은 셀프 조인(self-join)에 있었다. 같은 테이블 data를 a와 b라는 별칭으로 두 번 참조해서, 같은 논문(같은 key)에 등장하는 서로 다른 저자들을 찾아낸다. 여기서 핵심은 a.author > b.author 조건이다. 이는 중복을 제거하는 영리한 방법으로, 예를 들어 “Vincent, Pascal”과 “Bengio, Yoshua” 쌍이 한 번만 나타나게 하고, 그 역순인 “Bengio, Yoshua”와 “Vincent, Pascal” 쌍은 제외한다. 문자열의 알파벳 순서를 이용한 것이다.
박연구원이 엑셀에서 같은 분석을 하려면 어떻게 해야 할까? 먼저 각 논문의 모든 저자 쌍을 수동으로 만들어야 한다. 3명의 공동 저자가 있다면 3개의 쌍(A-B, A-C, B-C)을, 4명이 있다면 6개의 쌍을 만들어야 한다. 2,937개 논문에서 이런 작업을 수행하는 것은 상상하기도 어려운 노가다 작업이다.
중요데이터 정규화의 현실적 과제
“Bengio, Yoshua”와 “Bengio, Y.”는 거의 확실히 동일인이지만 다른 레코드로 처리되고 있다. 이는 역정규화(denormalization) 문제로, 완벽한 해결책은 없다. 휴리스틱을 통해 해결할 수 있지만 항상 근사치만 제공한다는 한계가 있다. 실제 연구에서는 “Mohammad Albar”와 “Michael Albar”처럼 같은 이니셜을 가진 다른 사람일 수도 있기 때문이다.
12.4.4 손익분기점 분석
이제 숫자로 말해보자. 박연구원이 수작업으로 같은 분석을 수행한다면, 각 행을 열어서 저자를 확인하고, 저자별로 새로운 행을 만들고, 협업 관계를 추적하는 데 최소 2분은 걸릴 것이다. 2,937행 × 2분 = 98시간의 순수 작업 시간이다. 여기에 실수로 인한 재작업, 중간 휴식, 정신적 피로를 고려하면 실제로는 2주간의 풀타임 작업이 필요하다.
반면 김박사의 경우는 어떨까? 만약 전통적인 방식으로 프로그래밍했다면 프로그램 작성에 2시간 + 실행 5분 = 2.1시간이 소요되었을 것이다. 하지만 김박사는 AI 보조 프로그래밍을 활용했다. ChatGPT에게 “CSV 파일에서 저자명을 분리해서 SQL INSERT 문장을 생성하는 Python 코드를 작성해줘”라고 요청한 순간, 기본 코드가 30초 만에 생성되었다. 이후 데이터에 맞는 미세 조정과 테스트에 30분이 걸려서, 총 31분 + 실행 5분 = 36분으로 단축되었다.
중요시간 효율성 비교: AI의 압도적 우위
- 박연구원 (엑셀 수작업): 98시간
- 김박사 (전통적 프로그래밍): 2.1시간 (98% 단축)
- 김박사 (AI 보조 프로그래밍): 0.6시간 (99.4% 단축)
AI 도입으로 프로그래밍 시간마저 3.5배 추가 단축!
AI의 도입으로 프로그래밍 시간마저 3.5배 단축되었다. 더 중요한 것은 AI가 생성한 코드의 품질이다. 단순히 동작하는 코드가 아니라, 모범 사례(best practices)를 따르는 코드였다. 예외 처리, 주석, 모듈화 등이 자동으로 포함되어 있어, 김박사가 직접 작성했다면 놓쳤을 수도 있는 세부사항까지 챙겨졌다.
하지만 진정한 가치는 재사용성에 있다. 다음에 5,000행의 새로운 데이터셋이 들어와도, 김박사는 AI에게 “이전 코드를 새로운 데이터 형식에 맞게 수정해줘”라고 요청해서 2분이면 처리할 수 있다. 박연구원은 다시 160시간을 투자해야 할 것이다.
AI 시대의 새로운 손익분기점 원칙이 여기서 등장한다: 수작업에 5분이 걸리는 작업도 AI를 활용하면 30초 만에 자동화할 수 있다. 김박사의 경우, 첫 번째 사용에서 163배의 수익률 (98시간 vs 0.6시간)을 얻었고, 두 번째부터는 무한대의 수익률을 누리게 된다.
12.4.5 버전 관리
김박사의 또 다른 습관은 작업이 완료되면 반드시 Git으로 버전을 관리하는 것이다. 다음 세 줄의 명령어는 단순한 백업 이상의 의미를 갖는다. 과학적 연구의 재현성(reproducibility)을 보장하는 것이다. 6개월 후 동료가 “어떻게 이 결과를 얻었나요?”라고 물어본다면, 김박사는 정확히 같은 코드로 같은 결과를 재생산할 수 있다. 심지어 사용한 데이터의 버전까지 추적할 수 있다.
git init .
git add -A
git commit -m "Extracting (key, author) pairs from bibliography"박연구원의 엑셀 클릭 작업과는 완전히 다른 세계다. 엑셀에서는 “실행 취소”가 제한적이고, 어떤 셀을 언제 어떻게 수정했는지 추적하기 어렵다. 더 중요한 것은 복잡한 수식과 매크로가 숨어있을 때, 나중에 그 로직을 이해하기 어렵다는 점이다. 김박사의 접근법은 완전한 감사 추적(audit trail)을 제공한다. 모든 변환 단계가 코드로 명시적으로 문서화되어 있고, Git을 통해 변경 이력이 보존된다.
이것이 현대 데이터 과학에서 “재현 가능한 연구(reproducible research)”가 중요한 이유다. 연구 결과가 신뢰받으려면, 다른 연구자가 같은 방법으로 같은 결과를 얻을 수 있어야 한다. 김박사의 ETL 파이프라인은 단순한 시간 절약 도구가 아니라, 과학적 엄밀성을 보장하는 방법론이었다.
💭 생각해볼 점
박연구원이 2,937개 논문 데이터를 처리하는 데 98시간이 걸릴 작업을, 김박사는 AI 보조 프로그래밍으로 0.6시간 만에 해결했다. 99.4%의 시간 단축, 163배의 수익률이다. 이 극적인 차이는 단순히 도구의 문제가 아니라 접근법의 패러다임 전환을 보여준다.
그렇다면 AI-SQL 시대에 스프레드시트는 완전히 사라져야 할까? 실제로는 그렇지 않다. 김박사도 최종 분석 결과를 동료들과 공유할 때는 엑셀 파일을 사용했다. 엑셀의 시각적 직관성과 AI-SQL의 논리적 정확성은 서로 다른 상황에서 최적의 선택이 된다.
현실적인 하이브리드 전략:
- 초기 탐색: 엑셀로 데이터의 전체적 구조 파악
- 본격 처리: AI-SQL 파이프라인으로 자동화
- 결과 공유: 엑셀 형태로 가독성 있는 보고서 작성
- 재현성 보장: Git으로 모든 과정 버전 관리
중요한 것은 도구에 종속되지 않는 판단력이다. 2분짜리 일회성 작업에 30분짜리 자동화를 시도하는 것은 비효율적이다. 하지만 반복 가능성이 있거나 데이터 규모가 크다면, AI의 도움을 받아 즉시 자동화해야 한다.
AI 시대의 새로운 손익분기점은 이렇다: 수작업 5분 = 자동화 30초. 두 번 이상 반복될 작업이라면 주저하지 말고 AI와 대화하라. 1927년 남극 탐사대의 수기 기록이 현시점 AI와 대화하는 시대까지 이어진 것처럼, 데이터 분석의 진화는 계속된다.