고등학생 통학 데이터 분석
attend_school.Rmd
library(bitData)
#> Warning: replacing previous import 'jsonlite::flatten' by 'purrr::flatten' when
#> loading 'bitData'
#>
#> Attaching package: 'bitData'
#> The following object is masked from 'package:datasets':
#>
#> co2데이터
원 데이터
library(tidyverse)
library(lubridate)
library(readxl)
# 2. 데이터 ------------
school_raw <- read_excel("inst/extdata/봉담고.xlsx")
# 3. 데이터 가공 ------------
school_tbl <- school_raw %>%
janitor::clean_names(ascii = FALSE) %>%
# 변수명 정리
set_names(c("요일", "통학방식", "출발시간",
"도착시간", "지각여부", "소요시간", "위도", "경도")) %>%
# 자료형
mutate(출발시간 = hms(출발시간),
도착시간 = hms(도착시간)) %>%
mutate(소요시간 = 도착시간 - 출발시간) %>%
# 범주형 연속형 변수 단순화
mutate(통학방식 = case_when(str_detect(통학방식, "(버스.*도보)") ~ "버스+도보",
TRUE ~ 통학방식))
school_tbl패키지 데이터
library(tidyverse)
#> ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.1 ──
#> ✔ ggplot2 3.3.6 ✔ purrr 0.3.4
#> ✔ tibble 3.1.8 ✔ dplyr 1.0.10
#> ✔ tidyr 1.2.1 ✔ stringr 1.4.1
#> ✔ readr 2.1.2 ✔ forcats 0.5.2
#> Warning: package 'tibble' was built under R version 4.2.1
#> Warning: package 'tidyr' was built under R version 4.2.1
#> Warning: package 'dplyr' was built under R version 4.2.1
#> Warning: package 'stringr' was built under R version 4.2.1
#> Warning: package 'forcats' was built under R version 4.2.1
#> ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
library(lubridate)
#>
#> Attaching package: 'lubridate'
#> The following objects are masked from 'package:base':
#>
#> date, intersect, setdiff, union
library(readxl)
#> Warning: package 'readxl' was built under R version 4.2.1
bitData::school
#> # A tibble: 2,752 × 8
#> 요일 통학방식 출발시간 도착시간 지각여부 소요시간 위도 경도
#> <chr> <chr> <Period> <Period> <chr> <Period> <dbl> <dbl>
#> 1 금 도보 7H 35M 0S 7H 40M 0S 정상 등교 5M 0S 37.2 127.
#> 2 화 도보 8H 27M 0S 8H 35M 0S 정상 등교 8M 0S 37.2 127.
#> 3 월 도보 8H 30M 0S 8H 36M 0S 정상 등교 6M 0S 37.2 127.
#> 4 목 도보 8H 35M 0S 8H 42M 0S 정상 등교 7M 0S 37.2 127.
#> 5 금 도보 8H 35M 0S 8H 42M 0S 정상 등교 7M 0S 37.2 127.
#> 6 화 도보 8H 40M 0S 8H 45M 0S 정상 등교 5M 0S 37.2 127.
#> 7 금 도보 7H 49M 0S 8H 46M 0S 정상 등교 1H -3M 0S 37.2 127.
#> 8 수 도보 8H 40M 0S 8H 47M 0S 정상 등교 7M 0S 37.2 127.
#> 9 화 도보 8H 40M 0S 8H 47M 0S 정상 등교 7M 0S 37.2 127.
#> 10 월 도보 8H 35M 0S 8H 47M 0S 정상 등교 12M 0S 37.2 127.
#> # … with 2,742 more rows탐색적 데이터 분석
기술통계량
skimr::skim(school)| Name | school |
| Number of rows | 2752 |
| Number of columns | 8 |
| _______________________ | |
| Column type frequency: | |
| character | 3 |
| numeric | 2 |
| Timespan | 3 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| 요일 | 0 | 1 | 1 | 1 | 0 | 5 | 0 |
| 통학방식 | 0 | 1 | 2 | 8 | 0 | 6 | 0 |
| 지각여부 | 0 | 1 | 2 | 5 | 0 | 3 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| 위도 | 0 | 1 | 37.22 | 0.03 | 37.16 | 37.21 | 37.22 | 37.22 | 37.56 | ▇▁▁▁▁ |
| 경도 | 0 | 1 | 126.96 | 0.01 | 126.86 | 126.95 | 126.96 | 126.97 | 127.03 | ▁▁▇▆▁ |
Variable type: Timespan
| skim_variable | n_missing | complete_rate | min | max | median | n_unique |
|---|---|---|---|---|---|---|
| 출발시간 | 0 | 1 | 0 | 0 | 0 | 1 |
| 도착시간 | 0 | 1 | 0 | 0 | 0 | 1 |
| 소요시간 | 0 | 1 | 0 | 0 | 0 | 1 |
연속형 변수
시분초 형태(Period) 자료구조로 표현된 등교소요시간에
대한 평균값을 구한다. 이를 위해서 lubridate 패키지
period_to_seconds() 함수를 사용해서 숫자형으로 변환한 후
평균을 계산하고 이를 다시 시분초 형태 자료형으로 변환시켜 평균
등교소요시간을 구한다.
school %>%
summarise(평균 = round(mean(period_to_seconds(소요시간))) %>% seconds_to_period(.))
#> # A tibble: 1 × 1
#> 평균
#> <Period>
#> 1 18M 12S통학방식, 요일, 지각여부를 구분하여 평균 등교소요시간을 구해보는 것은 그다음으로 의미있는 분석으로 보인다.
school %>%
group_by(요일) %>%
summarise(평균 = round(mean(period_to_seconds(소요시간))) %>% seconds_to_period(.))
#> # A tibble: 5 × 2
#> 요일 평균
#> <chr> <Period>
#> 1 금 18M 14S
#> 2 목 18M 2S
#> 3 수 18M 7S
#> 4 월 18M 15S
#> 5 화 18M 21S매번 코드를 달리 작성하면 어려움이 있기 때문에 함수를 작성하여 통학방식, 요일, 지각여부 인자를 달리하면 평균 등교소요시간을 계산할 수 있도록 한다.
calulate_commute_time <- function(varname) {
school %>%
group_by({{varname}}) %>%
summarise(평균 = round(mean(period_to_seconds(소요시간))) %>% seconds_to_period(.))
}
calulate_commute_time(통학방식)
#> # A tibble: 6 × 2
#> 통학방식 평균
#> <chr> <Period>
#> 1 도보 13M 50S
#> 2 버스 27M 49S
#> 3 버스+도보 47M 30S
#> 4 자가용(부모님) 17M 19S
#> 5 자가용+도보 11M 0S
#> 6 자전거 15M 0S
calulate_commute_time(요일)
#> # A tibble: 5 × 2
#> 요일 평균
#> <chr> <Period>
#> 1 금 18M 14S
#> 2 목 18M 2S
#> 3 수 18M 7S
#> 4 월 18M 15S
#> 5 화 18M 21S
calulate_commute_time(지각여부)
#> # A tibble: 3 × 2
#> 지각여부 평균
#> <chr> <Period>
#> 1 정상 등교 18M 4S
#> 2 지각 23M 29S
#> 3 질병 지각 16M 58S범주형 변수
요일별 등교 현황
월~금 요일별 학생 등교 비율을 살펴보면 월요일 다른 요일과 비교하여 적은 것이 보여진다. 중요한 점은 요일에는 순서가 월~금까지 정해져 있지만 컴퓨터는 가나다 순으로 기본설정이 되어 있어 이에 대한 조정이 필요하다.
통학방식
고등학생 통학데이터에서 중요한 변수로 통학방식으로 볼 수 있다. 하지만 원본 데이터가 특정 범주에 몰려 있어 이를 유의미한 범주로 정리하여 후속 분석에 활요하는 것이 필요하다.
school %>%
count(통학방식)
#> # A tibble: 6 × 2
#> 통학방식 n
#> <chr> <int>
#> 1 도보 1430
#> 2 버스 702
#> 3 버스+도보 2
#> 4 자가용(부모님) 615
#> 5 자가용+도보 2
#> 6 자전거 1통학방식에 자가용+도보, 버스+도보를 큰
틀에서 자가용, 버스 범주로 정리하여 비율과
빈도수를 구해본다.
school %>%
mutate(통학방식 = case_when(통학방식 == "버스+도보" ~ "버스",
통학방식 == "자가용(부모님)" ~ "자가용",
통학방식 == "자가용+도보" ~ "자가용",
TRUE ~ 통학방식)) %>%
filter(통학방식 != "자전거") %>%
count(통학방식, name = "빈도수") %>%
mutate(비율 = 빈도수 / sum(빈도수))
#> # A tibble: 3 × 3
#> 통학방식 빈도수 비율
#> <chr> <int> <dbl>
#> 1 도보 1430 0.520
#> 2 버스 704 0.256
#> 3 자가용 617 0.224지각여부
등교데이터셋에서 가장 중요한 사항은 지각여부로 보인다. 따라서 지각여부를 어떻게 정의하느냐에 따라 분석 결과도 달라질 수 있다.
school %>%
count(지각여부, name = "빈도수") %>%
mutate(비율 = 빈도수 / sum(빈도수))
#> # A tibble: 3 × 3
#> 지각여부 빈도수 비율
#> <chr> <int> <dbl>
#> 1 정상 등교 2644 0.961
#> 2 지각 75 0.0273
#> 3 질병 지각 33 0.0120지각 + 질병 지각이 전체 4%정도 되기 때문에 이 두 범주를
하나로 합쳐서 분석을 하고 추후 지각중에서 질병지각인지를 파악하는 것은
후속 심화분석으로 추진하면 좋을 듯 싶다.
공간지리정보
봉담교 등교(school) 데이터는 집위치정보가 위경도로
표시되어 있어 이를 지도상에 시각화하는 것이 가능하다. 이를 통해서
학교로부터 통학장소 거리가 지각여부에 영향을 주는지 검증할 수도
있다.
지도 가져오기
공간정보를 가져오는데 지도가 필요하다. 위도 경도 정보만 제공하면 바로
가져올 수 있는 leaftlet 패키지를 이용한다. 인터랙티브
기능도 제공하여 줌인/줌아웃도 가능하다. 우리나라를 비롯한 전세계 지도가
필요한 것은 아니고 경기도 화성 봉담고가 위치한 주변 지도만 필요하기
때문에 이곳으로 한정한다. 데이터의 위경도 평균을 내게 되면 별도 위경도를
구하지 않고도 쉽게 해당 지도 위치를 특정할 수 있다.
library(sf)
#> Linking to GEOS 3.9.1, GDAL 3.3.2, PROJ 7.2.1; sf_use_s2() is TRUE
library(leaflet)
library(fontawesome)
## 봉담교 주변 지도
lat_lng_tbl <- school %>%
summarise(lat_mean = mean(위도),
lng_mean = mean(경도))
leaflet(school) %>%
setView(lat = lat_lng_tbl$lat_mean,
lng = lat_lng_tbl$lng_mean, zoom=11) %>%
addTiles()공간정보 데이터
구글 지도 에 ’Google 지도 검색’을 하게 되면 예를 들어, “봉담고등학교”를 검색창에 넣게 되면 봉담고를 지도 중앙에 위치시키고 url이 포함된 웹브라우져 URL 창에서 봉담고등학교 위도와 경도 정보를 찾아낼 수 있다.
거의 96% 이상 학생이 지각하지 않고 정상등교를 하기 때문에 상대적으로 많은 데이터를 지도에 뿌리게 되면 속도가 늦어지기 때문에 96% 정상 등교를 지각하는 비율과 동일하게 표본추출하여 정보는 비교가능하게 하면서 속도는 향상시켜 시각화하는 방법을 모색한다. 이를 위해서 데이터를 표본추출하고 앞서 준비한 지도에 뿌려질 데이터도 함께 준비한다.
# 구글 지도에서 추출한 위경도 정보
bongdam_hs <- tibble("위도" = 37.2174845,
"경도" = 126.9540369)
school_hs <- school %>%
# 위경도 중복값이 많아... 난수를 일부 추가하여 가독성 향상
mutate(위도 = 위도 + runif(nrow(school), min = 0.0001, max = 0.001),
경도 = 경도 + runif(nrow(school), min = 0.0001, max = 0.001)) %>%
# 지각 108명 downsampling
mutate(지각여부 = ifelse(str_detect(지각여부, "지각"), "지각", "정상")) %>%
group_by(지각여부) %>%
add_count %>%
slice(sample(row_number(), min(.$n))) %>%
select(-n) %>%
ungroup() %>%
# 학교위치 추가
bind_rows(bongdam_hs) %>%
# 시각화를 위한 구분: 학교/정상/지각
mutate(구분 = case_when(is.na(요일) ~ "학교",
str_detect(지각여부, "정상") ~ "정상",
TRUE ~ "지각")) 시각화
지각과 정상등교를 학교와 한눈에 파악할 수 있도록
leaflet으로 시각화한다.
# 시각화 아이콘
highschool_icons <- awesomeIconList(
"학교" = makeAwesomeIcon(
icon = "school",
markerColor = "blue",
library = "fa",
text = fa("school")
),
"정상" = makeAwesomeIcon(
icon = "walking",
markerColor = "green",
library = "fa",
text = fa("walking")
),
"지각" = makeAwesomeIcon(
icon = "late",
markerColor = "red",
library = "fa",
text = fa("hospital")
)
)
# 시각화
leaflet(school_hs) %>%
setView(lat = lat_lng_tbl$lat_mean,
lng = lat_lng_tbl$lng_mean, zoom=11) %>%
addProviderTiles('CartoDB.Positron') %>%
addAwesomeMarkers(lat =~위도, lng = ~경도,
icon = ~ highschool_icons[구분]) 데이터 정제
앞서 탐색적 데이터분석을 통해 데이터의 특이한 점을 찾아냈고 이를
반영하여 이후 분석에 사용될 데이터를 가늠할 수 있게 되었다. 먼저,
데이터를 정제한 후 최종 분석에 사용될 데이터로 변환시켜 두자. 이를
데이터 정제과정(Cleansing)이라고 하는데 이는 컴퓨터가 Garbage-In
Garbage-Out과는 의미가 다르다. 앞선 school 원본 데이터도
컴퓨터 프로그램을 통해 분석이 가능하나 예를 들어 좀더 유의미한 등교율을
높이는데 목적을 둔 분석에 적합한 형태 데이터는 아니다.
library(geosphere)
#> Warning: package 'geosphere' was built under R version 4.2.2
school_tbl <- school %>%
mutate(요일 = factor(요일,
levels = c("월", "화", "수", "목", "금"))) %>%
mutate(통학방식 = case_when(통학방식 == "버스+도보" ~ "버스",
통학방식 == "자가용(부모님)" ~ "자가용",
통학방식 == "자가용+도보" ~ "자가용",
TRUE ~ 통학방식)) %>%
filter(통학방식 != "자전거") %>%
mutate(지각여부 = case_when(str_detect(지각여부, "지각") ~ "지각",
TRUE ~ "정상")) %>%
# 날짜와 시분초를 합쳐 온전한 일시 변수로 준비한다.
mutate(날짜 = as.Date("2022-11-07") + as.integer(요일) - 1 ) %>%
mutate(출발일시 = make_datetime(year = year(날짜),
month = month(날짜),
day = day(날짜),
hour = hour(출발시간),
min = minute(출발시간),
sec = second(출발시간)),
도착일시 = make_datetime(year = year(날짜),
month = month(날짜),
day = day(날짜),
hour = hour(도착시간),
min = minute(도착시간),
sec = second(도착시간)),
) %>%
mutate(학번 = row_number()) %>%
mutate(소요시간 = period_to_seconds(소요시간)) %>%
select(학번, 출발일시, 도착일시, 통학방식, 지각여부, 위도, 경도, 소요시간) %>%
# 학교에서 집까지 거리 (KM)
mutate(거리 = distHaversine(cbind(경도, 위도),
cbind(bongdam_hs$경도, bongdam_hs$위도))) %>%
mutate(거리 = 거리 / 1000)
school_tbl
#> # A tibble: 2,751 × 9
#> 학번 출발일시 도착일시 통학방식 지각여부 위도 경도
#> <int> <dttm> <dttm> <chr> <chr> <dbl> <dbl>
#> 1 1 2022-11-11 07:35:00 2022-11-11 07:40:00 도보 정상 37.2 127.
#> 2 2 2022-11-08 08:27:00 2022-11-08 08:35:00 도보 정상 37.2 127.
#> 3 3 2022-11-07 08:30:00 2022-11-07 08:36:00 도보 정상 37.2 127.
#> 4 4 2022-11-10 08:35:00 2022-11-10 08:42:00 도보 정상 37.2 127.
#> 5 5 2022-11-11 08:35:00 2022-11-11 08:42:00 도보 정상 37.2 127.
#> 6 6 2022-11-08 08:40:00 2022-11-08 08:45:00 도보 정상 37.2 127.
#> 7 7 2022-11-11 07:49:00 2022-11-11 08:46:00 도보 정상 37.2 127.
#> 8 8 2022-11-09 08:40:00 2022-11-09 08:47:00 도보 정상 37.2 127.
#> 9 9 2022-11-08 08:40:00 2022-11-08 08:47:00 도보 정상 37.2 127.
#> 10 10 2022-11-07 08:35:00 2022-11-07 08:47:00 도보 정상 37.2 127.
#> # … with 2,741 more rows, and 2 more variables: 소요시간 <dbl>, 거리 <dbl>소형 데이터셋
앞서 leaflet 시각화와 마찬자기로 연산이 대규모로 필요한
경우 데이터 크기를 줄여 빠르게 분석, 시각화, 모형개발이 필요한 경우가
있다. 이런 경우를 대비하여 크기를 up sampling, down sampling 하여
데이터셋 크기를 줄여 이를 활용하는 것도 실무에서 자주 있는 경우다.
school_down <- school_tbl %>%
group_by(지각여부) %>%
add_count %>%
slice(sample(row_number(), min(.$n))) %>%
select(-n) %>%
ungroup()
school_down
#> # A tibble: 216 × 9
#> 학번 출발일시 도착일시 통학방식 지각여부 위도 경도
#> <int> <dttm> <dttm> <chr> <chr> <dbl> <dbl>
#> 1 1275 2022-11-09 08:31:00 2022-11-09 08:45:00 도보 정상 37.2 127.
#> 2 423 2022-11-09 07:58:00 2022-11-09 08:15:00 자가용 정상 37.2 127.
#> 3 2197 2022-11-10 08:27:00 2022-11-10 08:46:00 도보 정상 37.2 127.
#> 4 2058 2022-11-08 07:40:00 2022-11-08 08:45:00 도보 정상 37.2 127.
#> 5 522 2022-11-07 08:04:00 2022-11-07 08:15:00 자가용 정상 37.2 127.
#> 6 1215 2022-11-09 08:35:00 2022-11-09 08:40:00 도보 정상 37.2 127.
#> 7 804 2022-11-08 08:09:00 2022-11-08 08:26:00 도보 정상 37.2 127.
#> 8 618 2022-11-09 08:00:00 2022-11-09 08:30:00 버스 정상 37.2 127.
#> 9 1083 2022-11-10 08:37:00 2022-11-10 08:46:00 도보 정상 37.2 127.
#> 10 202 2022-11-09 07:25:00 2022-11-09 08:00:00 버스 정상 37.2 127.
#> # … with 206 more rows, and 2 more variables: 소요시간 <dbl>, 거리 <dbl>등교 지각 줄이기
통학방식별 소요시간차이
정상등교와 질병을 포함한 지각에 주된 통학방식별로 차이가 있는지 평균 소요시간을 구해보자.
library(gt)
#> Warning: package 'gt' was built under R version 4.2.1
school_tbl %>%
group_by(통학방식, 지각여부) %>%
summarise(평균소요시간 = round(mean(소요시간)) %>% seconds_to_period(.)) %>%
ungroup() %>%
## 표 시각화를 위한 자료구조 변환
pivot_wider(names_from = 지각여부, values_from = 평균소요시간) %>%
mutate(차이 = 지각 - 정상) %>%
# 표 제작
gt() %>%
tab_header(
title = md("**☀ 봉담고등학생 평균 통학소요시간 ☀**"),
subtitle = md("*통학방식별 지각생과 정상 등교 소요시간*")
) %>%
tab_options(
table.width = "400px",
heading.background.color = "#1E61B0", # R logo 파란색
heading.title.font.size = "20px",
column_labels.background.color = "#F7F7F7", # R logo 회색
column_labels.font.weight = "bold",
stub.background.color = "#ffffff",
stub.font.weight = "bold"
) %>%
cols_align(
align = "center",
columns = everything()
) %>%
tab_style(style = list(cell_text(weight = 'bold',
size = "large",
color = "blue")),
locations = cells_body(columns = 차이,
rows = 통학방식 == "자가용")) %>%
tab_spanner(
label = "정상 등교 / (질병) 지각",
id = "dt",
columns = c(정상, 지각)
) %>%
tab_style(
style = cell_text(weight = "bold"),
locations = cells_column_spanners(spanners = "dt")
) %>%
tab_footnote(
footnote = "봉담고 등교 데이터: 지각 = 일반 지각 + 질병 지각",
locations = cells_column_spanners(spanners = "dt")
)
#> `summarise()` has grouped output by '통학방식'. You can override using the
#> `.groups` argument.| ☀ 봉담고등학생 평균 통학소요시간 ☀ | |||
| 통학방식별 지각생과 정상 등교 소요시간 | |||
| 통학방식 | 정상 등교 / (질병) 지각1 | 차이 | |
|---|---|---|---|
| 정상 | 지각 | ||
| 도보 | 13M 42S | 16M 50S | 3M 8S |
| 버스 | 27M 44S | 30M 45S | 3M 1S |
| 자가용 | 17M 11S | 21M 36S | 4M 25S |
| 1 봉담고 등교 데이터: 지각 = 일반 지각 + 질병 지각 | |||
통학거리와 소요시간 관계
통학거리에 따라 소요시간이 늘어가는 것은 상식이지만 도보, 버스, 자가용으로 인해 소요시간에는 직관적으로 알려진 것과 차이가 날 수 있다. 이를 실증적인 데이터를 통해 검증해 보자.
extrafont::loadfonts()
school_tbl %>%
filter(거리 < 8) %>%
mutate(소요시간_분 = 소요시간/60) %>%
ggplot(aes(x = 거리, y = 소요시간_분, color = 지각여부)) +
geom_jitter(width = 0.3, alpha = 0.5) +
geom_smooth(se= FALSE, method = "lm") +
facet_wrap(~통학방식, ncol = 1) +
scale_color_manual(values = c("정상" = "gray50",
"지각" = "red")) +
labs( x = "학교까지 거리 (킬로미터, KM)",
y = "등교소요시간 (단위: 분)",
title = "봉담고 통학거리와 통학시간 관계") +
theme_bw(base_family = "MaruBuri") +
theme(legend.position = "top")
#> `geom_smooth()` using formula 'y ~ x'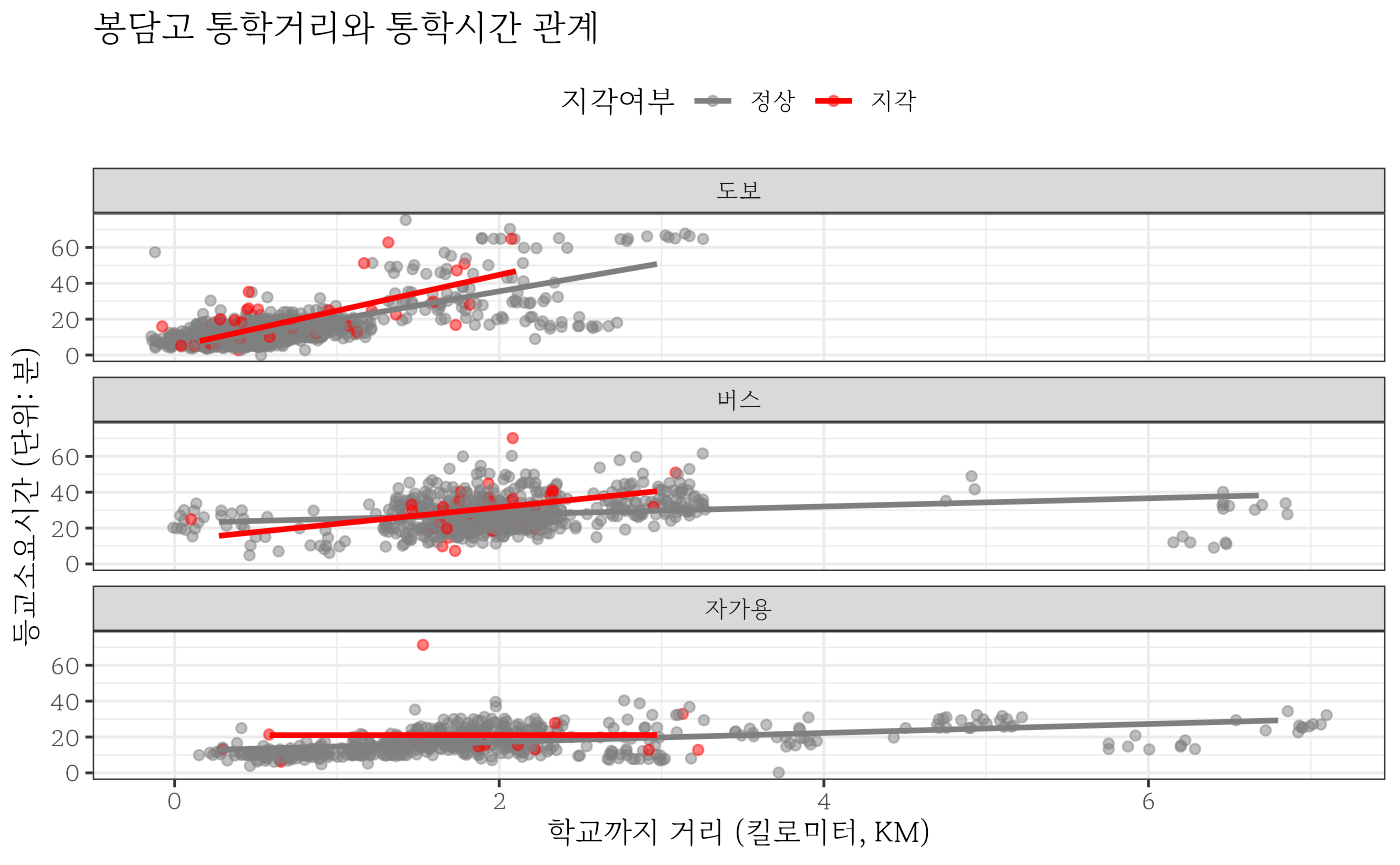
요일은 지각에 영향을 주는가?
월요병은 직장인이 필수적으로 겪고 있는 심각한 직업병(?)인데 고등학생도 이런 질병에 전염되었는지 데이터를 통해 확인해보자.
school_tbl %>%
mutate(요일 = lubridate::wday(출발일시, label=TRUE)) %>%
count(요일, 지각여부, name = "빈도수") %>%
pivot_wider(names_from = 지각여부, values_from = 빈도수) %>%
mutate(지각비율 = 지각 / (정상+지각)) %>%
# 표 제작
gt() %>%
tab_header(
title = md("**☀ 고등학생도 월요병이 있을까? ☀**"),
subtitle = md("*봉담고등학생 요일별 지각비율 데이터*")
) %>%
tab_options(
table.width = "400px",
heading.background.color = "#1E61B0", # R logo 파란색
heading.title.font.size = "20px",
column_labels.background.color = "#F7F7F7", # R logo 회색
column_labels.font.weight = "bold",
stub.background.color = "#ffffff",
stub.font.weight = "bold"
) %>%
cols_align(
align = "center",
columns = everything()
) %>%
fmt_percent(
columns = 지각비율,
decimals = 1,
use_seps = FALSE
) %>%
tab_style(style = list(cell_text(weight = 'bold',
size = "large",
color = "blue")),
locations = cells_body(columns = 지각비율,
rows = 지각비율 == max(지각비율))) %>%
tab_spanner(
label = "정상 등교 / (질병) 지각",
id = "late",
columns = c(정상, 지각)
) %>%
tab_style(
style = cell_text(weight = "bold"),
locations = cells_column_spanners(spanners = "late")
) %>%
tab_footnote(
footnote = "정상 등교 / (질병) 지각 = 일반 지각 + 질병 지각",
locations = cells_column_spanners(spanners = "late")
) | ☀ 고등학생도 월요병이 있을까? ☀ | |||
| 봉담고등학생 요일별 지각비율 데이터 | |||
| 요일 | 정상 등교 / (질병) 지각1 | 지각비율 | |
|---|---|---|---|
| 정상 | 지각 | ||
| 월 | 432 | 7 | 1.6% |
| 화 | 583 | 40 | 6.4% |
| 수 | 538 | 17 | 3.1% |
| 목 | 564 | 29 | 4.9% |
| 금 | 526 | 15 | 2.8% |
| 1 정상 등교 / (질병) 지각 = 일반 지각 + 질병 지각 | |||
Sys.setlocale(locale = "ko_KR.utf8")
#> [1] "LC_COLLATE=ko_KR.utf8;LC_CTYPE=ko_KR.utf8;LC_MONETARY=ko_KR.utf8;LC_NUMERIC=C;LC_TIME=ko_KR.utf8"
school_tbl %>%
mutate(요일 = lubridate::wday(출발일시, label=TRUE)) %>%
filter(거리 < 8) %>%
mutate(소요시간_분 = 소요시간/60) %>%
ggplot(aes(x = 거리, y = 소요시간_분, color = 지각여부)) +
geom_jitter(width = 0.3, alpha = 0.5) +
geom_smooth(se= FALSE, method = "lm") +
facet_wrap(~요일, nrow = 1) +
scale_color_manual(values = c("정상" = "gray50",
"지각" = "red")) +
labs( x = "학교까지 거리 (킬로미터, KM)",
y = "등교소요시간 (단위: 분)",
title = "봉담고 통학거리와 통학시간 관계") +
theme_bw(base_family = "MaruBuri") +
theme(legend.position = "top")
#> `geom_smooth()` using formula 'y ~ x'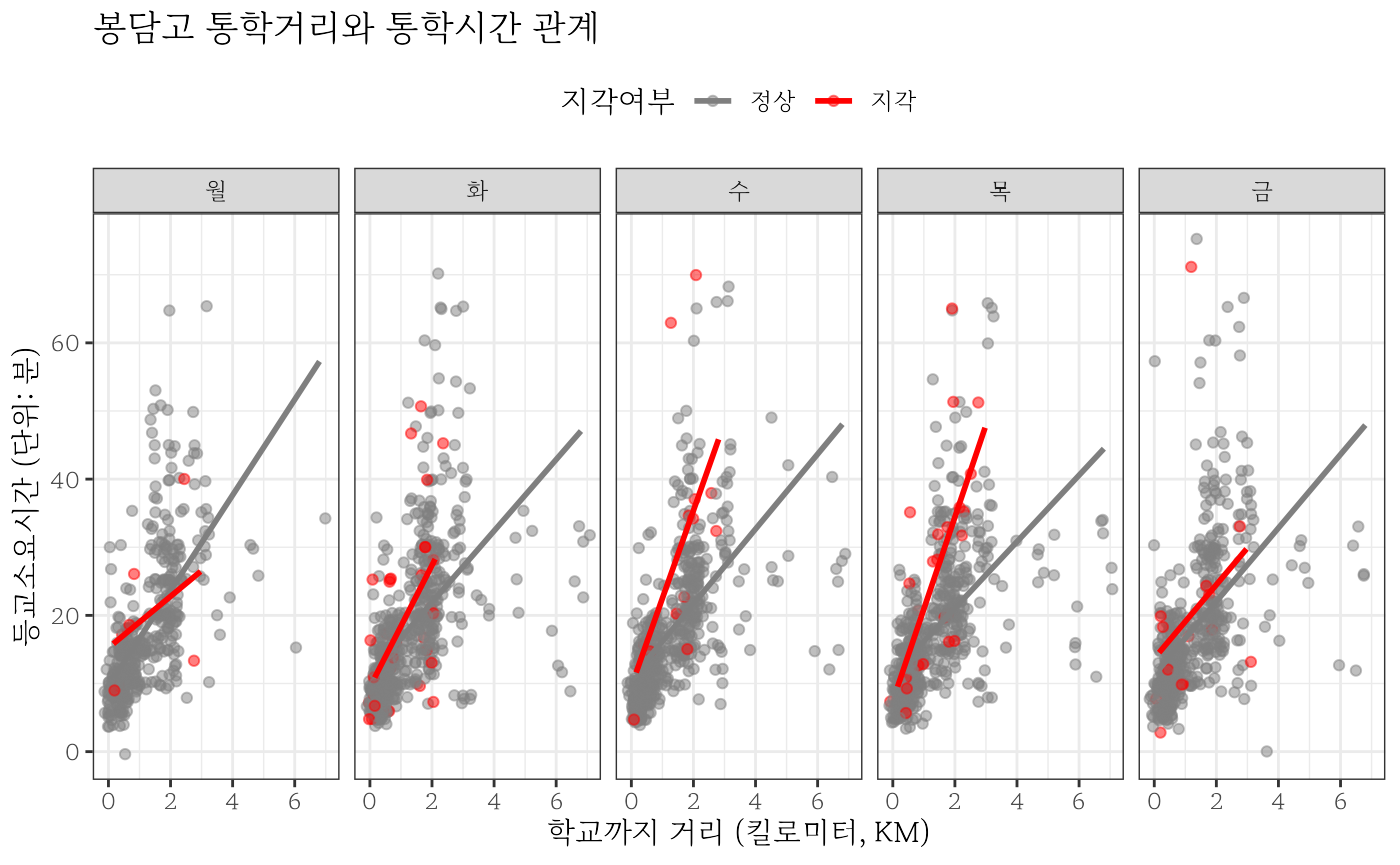
요일과 통학방식 고려
school_tbl %>%
mutate(요일 = lubridate::wday(출발일시, label=TRUE)) %>%
count(요일, 통학방식, 지각여부, name = "빈도수") %>%
pivot_wider(names_from = 지각여부, values_from =빈도수) %>%
mutate(지각비율 = 지각 / (정상 + 지각)) %>%
mutate(요약 = glue::glue("{지각} / {정상 + 지각} <br> ({scales::percent(지각비율, accuracy = 0.1)})") %>% as.character(.)) %>%
select(요일, 통학방식, 요약) %>%
pivot_wider(names_from = 통학방식, values_from = 요약) %>%
gt() %>%
fmt_markdown(columns = TRUE) %>%
tab_header(
title = md("**☀ 통학방법과 요일별 지각비율 ☀**"),
subtitle = md("*통학방법 요일별 지각횟수와 비율*")
) %>%
tab_options(
table.width = "400px",
heading.background.color = "#1E61B0", # R logo 파란색
heading.title.font.size = "20px",
column_labels.background.color = "#F7F7F7", # R logo 회색
column_labels.font.weight = "bold",
stub.background.color = "#ffffff",
stub.font.weight = "bold"
) %>%
cols_align(
align = "center",
columns = everything()
) %>%
tab_style(style = list(cell_text(weight = 'bold',
size = "large",
color = "blue")),
locations = cells_body(columns = 도보,
rows = 요일 == "화")) %>%
tab_spanner(
label = "통학방법",
id = "method",
columns = c(도보, 버스, 자가용)
) %>%
tab_style(
style = cell_text(weight = "bold"),
locations = cells_column_spanners(spanners = "method")
) %>%
tab_footnote(
footnote = "지각빈도수 / (지각+정상 빈도수) = 지각비율(%)",
locations = cells_column_spanners(spanners = "method")
)
#> Warning: Since gt v0.3.0, `columns = TRUE` has been deprecated.
#> • Please use `columns = everything()` instead.
#> Warning in `[<-.factor`(`*tmp*`, !is.na(x), value = c("<div
#> class='gt_from_md'><p>월</p>\n</div>", : invalid factor level, NA generated| ☀ 통학방법과 요일별 지각비율 ☀ | |||
| 통학방법 요일별 지각횟수와 비율 | |||
| 요일 | 통학방법1 | ||
|---|---|---|---|
| 도보 | 버스 | 자가용 | |
| 월 | 5 / 220 |
1 / 117 |
1 / 102 |
| 화 | 26 / 327 |
9 / 168 |
5 / 128 |
| 수 | 7 / 284 |
8 / 145 |
2 / 126 |
| 목 | 16 / 308 |
10 / 152 |
3 / 133 |
| 금 | 8 / 291 |
3 / 122 |
4 / 128 |
| 1 지각빈도수 / (지각+정상 빈도수) = 지각비율(%) | |||