학습 목표
데이터의 분류 체계로서의 척도를 이해하고, 이를 기반으로 한 R 데이터 객체를 이해한다. CSV 파일을 읽고, 데이터 프레임 객체로 CSV 파일을 생성할 수 있다.
이 장에서는 `bitPublish’를 이용하여 작성한 한글 책’의 형태를 이해할 수 있도록, 여러 조판 방법의 예시를 표현한다. 본문에 표현되는 내용은 저술중인, 가칭 “R로 배우는 기초 통계학”의 일부를 발췌한 것이다.(유충현 와/과 이상호 2013) 그러므로 본문의 내용은 완벽한 문맥이 아닌, 중간중간 문단이나 내용이 제거된 불완전한 내용임을 밝혀 둔다.
데이터의 분류 체계로서의 척도를 이해하고, 이를 기반으로 한 R 데이터 객체를 이해한다. CSV 파일을 읽고, 데이터 프레임 객체로 CSV 파일을 생성할 수 있다.
데이터(data)를 국어사전에서 찾으면 다음과 같은 세 가지의 뜻을 가지고 있다.
이 세 가지를 정리하면 데이터는 ``이론을 세우기 위해 관찰이나 실험, 조사를 통해서 얻은 정보를 컴퓨터가 처리하기 위한 형태로 만든 정보”로 생각해 볼 수 있다. 이 절에서는 데이터의 정의에서 컴퓨터가 처리하기 위한 형태로 된 정보를 R이 처리하기 위한 형태로 된 정보로 간주할 것이다. 또한 위키피디아(Wikipedia)에서는 데이터를 ``항목(items)의 집합(set)에 속하는 질적(qualitative) 또는 양적(quantitative) 변수(variables)의 값(values)”으로 정의하고 있다. 여기서 항목의 집합이란 관심이 있는 객체의 집합을 의미하며, 변수는 항목의 특성을 의미한다. 국어사전에서의 데이터 정의는 데이터의 목적성과 취득 방법 및 형태에 의한 것이라면, 위키피디아에서의 정의는 데이터의 속성에 대한 것이다.
국어사전에서의 정의를 기준으로 R을 이용한 통계분석을 위해서는 몇 단계의 과정이 필요하다.
첫째로, 사건이나 사실 등의 현상을 관찰하여 일정한 규칙에 의한 체계적인 단위의 수치를 부여하는 측정이 필요하다. 측정을 위해서는 자, 저울, 속도계, 온도계, 혈압계와 같은 측정을 위한 도구가 필요할 수도 있으며, 이를 통해서 측정한 현상을 수량화한다. 이처럼 사건이나 사실 등의 현상을 수량화하기 위해서 그 현상에 숫자를 부여한 것을 척도라 한다.
이러한 일련의 과정에 오류가 발생할 수 있다. 측정하는 과정에서 발생할 수 있는 측정의 오류, 측정된 값을 데이터로 코딩하는 과정에서의 오기(타)로 인한 오류도 있을 수 있다. 또한 측정하는 저울, 온도계와 같이 측정하는 도구의 정밀도에 따른 오류도 있을 수 있다. 그러므로 올바른 통계분석을 위해서는 분석 단계 이전에 정밀도가 높은 측정도구를 이용하여 정확하게 측정하고, 측정된 값을 정확하게 옮겨서 데이터화하는 것이 필요하다.
마지막으로 코딩된 데이터를 R의 데이터 객체로 변환하는 방법도 중요하다. 이 작업에서는 적절한 R의 데이터 객체로의 전환이 필요하며, 척도의 적당한 변환도 필요할 수 있다.
우수한 측정도구는 다음의 두 가지 조건을 만족해야 한다.
양궁으로 과녁을 맞히는 예를 R을 이용해서 그려 보자. 다음의 예제를 실행하면 그림 1.1같은 네 가지 종류 플롯을 얻는다. 여기서 가장 이상적인 과녁은 오른쪽 상단의 과녁으로 타당도와 신뢰도가 높음을 알 수 있다.

측정된 데이터는 본질적인 내용이 기호나 수량화되어서 변수로 만들어진다. 이 수치화된 변숫값들의 체계를 척도(scale)한다. 척도는 다음처럼 명목척도, 서열척도, 구간척도, 비율척도로 나누어진다.
빈도수를 이용한 계산만 의미가 있는 명목척도는 일반적으로 범주형 데이터로 만들어 진다. 예를 들면 성별이라는 범주형 데이터(categorical data)에서의 남자, 여자와 같은 수준(level)에 대한 도수 및 비율(빈도)을 이용한 분석을 수행할 수 있다. 서열척도 또한 범주형 데이터로 만들어지지만 명목척도와 달리 순서의 의미가 있기 때문에 빈도분석 이외에 중위수 등 순서통계량 기반의 분석을 수행할 수 있다. 구간척도와 비율척도에는 여러 가지의 기술통계 및 추론통계의 방법을 사용할 수 있으며, 우리가 일상생활에서 활용하는 수치 데이터들의 대부분은 비율척도로 이루어져 있다.
예제 1.1 (척도의 표현) 네 가지의 척도를 R의 데이터 객체로 표현해 보자.
명목척도에 대한 예제다. 예제의 fruits는 세 가지 과일 이름을 갖는 범주형 데이터로 R의 factor() 함수로 만들 수 있다. 이 함수는 factor라는, 명목척도를 표현하는 데이터 객체를 생성한다. 데이터 객체인 factor는 table() 함수를 이용해서 도수와 비율을 구할 수 있다.
명목척도를 표현하는 factor 객체는 apple, banana, pear와 같이 과일 이름으로 표현되지만 R의 내부에서는 1, 2, 3과 같이 인식된다. 그래서 as.numeric() 함수를 이용하면 apple, pear, pear, apple, banana가 1, 3, 3, 1, 2와 같이 인식됨을 알 수 있다. 여기서 각 수준을 인식하는 1, 2, 3은 비록 수치형이지만 각 수준의 크기가 아니라 몇 번째 수준인가를 나타내는 지시자다.
fruits <- c("apple", "pear", "pear", "apple", "banana")
fruits <- factor(fruits)
fruits[1] apple pear pear apple banana
Levels: apple banana peartable(fruits) # 도수분포fruits
apple banana pear
2 1 2 table(fruits) / sum(table(fruits)) * 100 # 비율 (백분율)fruits
apple banana pear
40 20 40 as.numeric(fruits) # 수준 인덱스[1] 1 3 3 1 2구간척도와 비율척도를 표현해 보자. 두 척도에서의 차이점은 절대 0의 여부에 따르기 때문에 표현하는 방법은 동일할 뿐, 개념적으로 절대 0을 갖느냐 갖지 못하느냐의 차이로 구분된다. 다음은 섭씨온도 값을 표현한 것과 절대온도 값을 표현한 예제다. 그런데 사실 두 사례는 동일한 온도값이다. 섭씨온도에 273.15를 더해서 절대온도로 변환하였기 때문이다.
도수분포표(frequency table)는 데이터의 분포 형태를 알아보기 위해서, 데이터를 구간별로 나누어 각 구간에 속하는 관찰치의 개수를 표로 나타낸 것이다. 각 구간을 계급(class)이라 하고 계급에 속한 관찰치의 개수를 도수(frequency)라 한다.
데이터가 \(x_1, x_2, x_3, \cdots, x_n\)일 때, 도수분포표는 다음의 단계적 방법으로 만든다.
클래스 상속과 ordered factor
상속(inheritance)은 부모 클래스의 내용(속성과 메소드)을 자식 클래스가 물려받는 것으로 객체지향형 언어의 특징이다. 예를 들면, 자동차라는 부모 클래스를 상속받아 세단과 SUV라는 자식 클래스를 생성하면, 자식 클래스인 세단과 SUV는 부모 클래스인 자동차가 갖고 있는 속성인 ‘핸들’, ‘브레이크’, ‘바퀴’와 같은 속성과 ‘엑셀을 밟다’, ‘핸들을 돌리다’, ‘브레이크를 밟다’와 같은 메소드를 사용할 수 있다. 세단은 ‘가벼운 중량’, ‘낮은 차체’ 속성을, SUV는 ‘무거운 중량’, ‘높은 차체’ 속성을 추가로 만들어서 부모 클래스로부터 자식 클래스를 정의한다.
R에서도 클래스 상속의 개념이 있다. ordered() 함수는 ’factor’라는 부모 클래스를 상속하여 ’ordered’라는 자식 클래스를 만든다. 그러므로 ’rdered’는 factor의 내용에, 수준의 순서가 서열로 처리되는 특성이 추가된 클래스다. 속성 중 class의 값이 “ordered” “factor”인 것은, 부모 클래스인 factor로부터 상속받아 만들어진 ordered 클래스라는 의미다. 오른쪽이 부모 클래스고, 왼쪽이 자식 클래스다.
CP949 인코딩과 fileEncoding 인수
MS Windows에서는 별도의 설정이 없으면, 텍스트 파일의 한글을 CP949로 인코딩하여 저장한다. 그러므로 MS Windows에서 만들어진 한글이 포함된 텍스트 파일을 읽을 때에는, ‘fileEncoding’ 인수에 “cp949”를 지정해야 한다. 그런데 그림처럼 Excel에서 CSV 파일을 저장할 때, 인코딩을 UTF-8로 설정하면 read.table() 함수에서 fileEncoding 인수로 인코딩을 “cp949”로 지정하지 않아도 된다.
외산 소프트웨어에서 한글을 문제없이 사용하는 것은 매우 번거롭고 까다롭다. 최선의 방법 중 하나는 한글이 포함된 데이터 파일을 UTF-8 인코딩으로 저장하는 것임을 잊지말자.
tidyverse 패키지는 R의 대표적인 패키지로 데이터 분석의 일련과정을 지원하는 여러 유용한 패키지의 모음이다. 그래서 패키지군이라 부르는 게 맞을듯 하다. tidyverse 패키지군을 구성하는 대표적인 패키지에는 dplyr 패키지와 ggplot2 패키지가 있다. dplyr 패키지는 논리적이고 순차적인 문법으로 데이터를 조작하거나 집계하는 패키지며 ggplot2 패키지는 데이터 시각화 패키지다. 우리는 dplyr 패키지를 이용해서 끊김없는 논리적 흐름의 전개로 도수분포표를 계산할 것이다.
개별 파이프의 목적은 파이프의 직경과 길이에 해당하는 수돗물을 특정 위치까지 이동시키는 것이다. 그리고 순차적인 데이터 처리의 흐름은 그림 1.2처럼 해당 처리를 담당하는 파이프들을 순차적으로 연결한 구조의 파이프라인으로 정의된다.
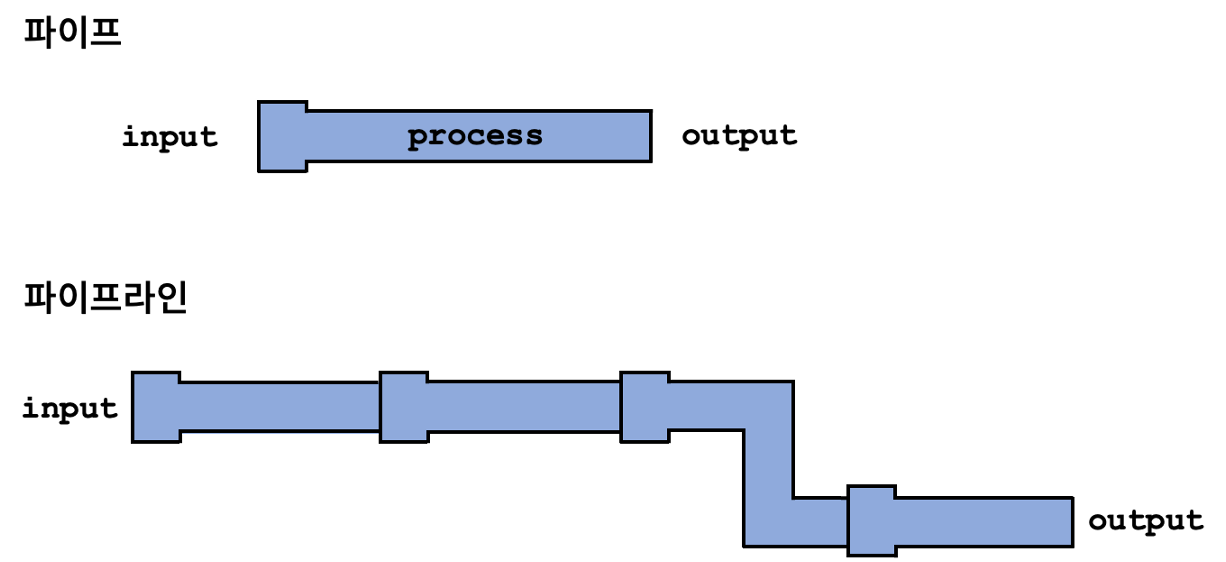
input -> process -> output 구조의 단일 파이프를 연결하기 위해서 tidyverse 패키지군의 magrittr 패키지가 파이프 연산자인 %>%를 제공한다. 이 연산자의 역할은 연산자 이전 함수(process)에서의 결과(output)를 다음 함수(process)의 입력(input)으로 전달하는 역할을 수행한다. 결국 이 연산자를 통해서 파이프라인이 만들어지며 input -> process -> output -> input -> process -> output과 같은 구조를 만들 수 있게 된다. 즉, 파이프 연산자 %>%는 파이프라인을 만드는 배관공이라 할 수 있다.
이러한 이유들로 인해서 파이프 연산자는 특히 dplyr 패키지의 데이터 처리에서 두각을 보였으며, 많은 R 사용자들의 R 스크립트에서 사랑받게되었다. 그래서 이제는 외부(3rd-party) 패키지가 아니라 R 엔진 자체에 파이프 연산자를 포함시켰고, |>로 표현한다.
이 책에서는 수리적인 알고리즘의 이해를 위한 작업이 아니라면, 가급적으로 R의 내장 파이프 연산자를 |>를 사용하여 파이프라인 처리를 하겠다. 유용한 기능이기 때문에 적극적으로 습득하는 것을 추천한다.
state.region은 내장 데이터셋으로 미국 50개주를 ‘Northeast’, ‘South’, ‘North Central’, `West’라는 4개 권역으로 분류한 범주형 데이터다. 이 데이터를 dplyr 패키지의 함수와 파이프 연산자를 이용해서 도수분포표를 만들어보겠다.
먼저 head() 함수로 데이터의 앞부분 몇 건을 조회해 본다.
head(state.region)[1] South West West South West West
Levels: Northeast South North Central West대략 데이터의 구조가 이해되었으니, tidyverse 패키지를 불러들여서 작업을 위한 환경을 구성한다. library() 함수로 tidyverse 패키지를 불러오면 dplyr, ggplot2를 비롯한 몇 개의 패키지가 자동으로 로드된다.
library(tidyverse)다음은 도수분포표를 생성하기 위한 dplyr 패키지 함수와 파이프 연산자를 이용한 스크립트다.
state.region |>
data.frame() |>
count(권역 = state.region, name = "도수") |>
mutate(누적도수 = cumsum(도수)) |>
mutate(상대도수 = 도수 / sum(도수)) |>
mutate(누적상대도수 = cumsum(상대도수)) 권역 도수 누적도수 상대도수 누적상대도수
1 Northeast 9 9 0.18 0.18
2 South 16 25 0.32 0.50
3 North Central 12 37 0.24 0.74
4 West 13 50 0.26 1.00열거형 도수분포표는 복잡한 수리적인 계산 알고리즘이 필요없다. 논리적인 사고로 데이터 처리 프로세스를 다음처럼 순차적으로 풀어나가면 된다.
data.frame()count()이 사례에서 중요한 것은 파이프 연산자로 심리스(seamless)1하게 데이터를 처리하는 순차 연산을 구현한다는 것이다.
뭔가를 연결할 때 마치 원래 하나였던 것처럼 끊김없이 매끄럽게 연결하는 것을 의미한다.↩︎