Tesla Model S의 내부를 들여다보면 7,000개가 넘는 부품들이 정교하게 조합되어 하나의 완성된 자동차를 만든다. 마찬가지로 현대 과학기술 문서도 다양한 특수 목적 언어(Domain-Specific Language, DSL)들이 정교하게 조합되어 완성된다. 일반 프로그래밍 언어인 R, Python, Julia가 연산 엔진이라면, 이번 장에서 다룰 DSL들은 과학문서 저작 전문 도구들이다.
그림 8.1: 과학 문서 DSL 생태계
과학자가 논문을 쓰는 과정을 생각해보자. 실험 데이터를 그래프로 시각화하고, 통계 결과를 정교한 표로 정리하고, 수식으로 이론을 설명하고, 다이어그램으로 실험 과정을 도식화한다. 수십 개 참고문헌을 정확한 형식으로 인용해야 한다. 각각의 요구사항은 서로 다른 전문 언어를 필요로 한다.
이 장에서는 과학기술 문서 작성에 필수적인 8가지 핵심 DSL을 다룬다. 각 DSL은 특정한 문제를 해결하기 위해 태어났으며, 쿼토 환경에서 어떻게 통합 활용할 수 있는지 실전 예제와 함께 살펴볼 것이다.
8.1 그래프 문법
과학 논문에서 그래프는 단순한 장식이 아니라 시각적 논증이다. 복잡한 실험 결과를 한눈에 이해할 수 있게 만드는 것은 물론, 데이터 속에 숨어있는 패턴과 관계를 명확하게 드러내는 역할을 한다. 이를 위해서 단순히 ’예쁜 그래프’를 만드는 것이 아니라, 그래프 문법(Grammar of Graphics)을 이해해야 한다.
“그래프는 데이터가 이야기를 전하는 언어다”
8.1.1 ggplot2
ggplot2는 1999년 르랜드 윌킨슨(Leland Wilkinson)의 “그래프 문법(Grammar of Graphics)” 이론을 바탕으로 2007년 해들리 위컴이 개발한 R 시각화 패키지다. ggplot2 패키지의 혁명적 통찰은 “파이 차트는 극좌표로 그린 막대 차트”라는 것으로, 겉보기에 다른 차트들이 실제로는 동일한 문법 구조를 가지고 있음을 발견한 것이다. 이를 통해 “어떻게 그릴지”에서 “무엇을 그릴지”로의 패러다임 전환이 일어났고, 현재 Tableau, Plotly, Python의 seaborn까지 모든 현대 시각화 도구의 표준이 되었다.
ggplot2는 그래프를 7개 독립적인 계층으로 분해한다: 1) 데이터, 2) 미학적 매핑(변수를 색상, 크기 등에 연결), 3) 기하학적 객체(점, 선, 막대), 4) 통계 변환(평균, 회귀선), 5) 척도(값과 시각적 속성 사이 매핑), 6) 좌표계(직교, 극좌표), 7) 면분할(하위 그룹별 패널). ggplot2의 핵심은 7개 요소 독립성이다. 기하학적 객체를 점에서 선으로 바꾸더라도 제목이나 범례는 그대로 유지되며, 좌표계를 직교에서 극좌표로 바꾸면 막대 차트가 파이 차트로 변환된다.
선언형 프로그래밍의 우아함은 ggplot2와 base R의 차이에서 극명하게 드러난다. ggplot2에서는 “무엇을 그릴지”만 선언하면 된다: ggplot(data, aes(x, y)) + geom_point(). 반면 base R은 “어떻게 그릴지” 단계별로 명령해야 한다: plot() → points() → legend() 순으로 각 요소를 개별 제어. 이 차이는 단순한 편의성을 넘어, 과학적 사고를 구조화된 코드로 표현할 수 있게 해준다.
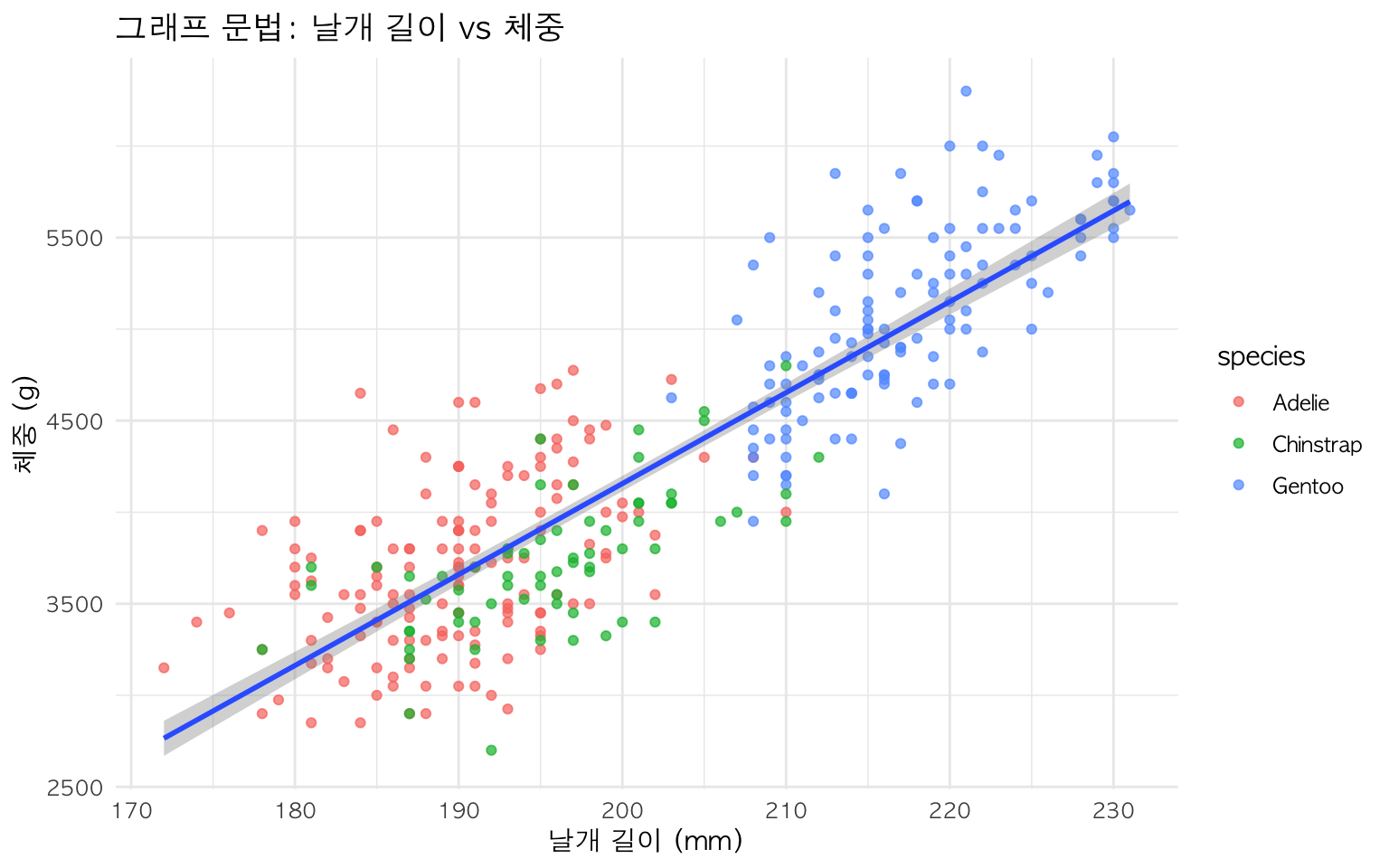
# ggplot2: "무엇을" 그릴지 선언ggplot(penguins, aes(x =flipper_length_mm, y =body_mass_g))+geom_point(aes(color =species))+geom_smooth(method ="lm")# 핵심 통찰 실증: 좌표계만 바꾸면 막대차트가 파이차트로ggplot(penguins, aes(x ="", fill =species))+geom_bar()+coord_polar(theta ="y")# 극좌표로 변환
8.1.2 Observable Plot
Observable Plot은 2021년 D3.js 창시자 마이크 보스톡(Mike Bostock)이 개발한 JavaScript 시각화 라이브러리로, 그래프 문법 철학을 웹 네이티브 방식으로 구현했다. D3.js(2011)가 저수준의 강력한 표현력을 제공했다면, Plot은 “추상화 계층(ladder of abstraction)” 접근법을 통해 고수준 편의성과 저수준 제어력을 모두 제공한다. ggplot2가 R에서 이룬 선언형 혁명을 JavaScript 생태계로 가져온 것이다.
Plot은 ggplot2와 동일한 Grammar of Graphics 구조를 따른다: 1) 데이터, 2) 마크(Mark, ggplot의 geom에 해당), 3) 채널(Channel, 미학적 매핑), 4) 스케일(Scale), 5) 변환(Transform, 통계 변환), 6) 면분할(Facet). 각 요소의 독립성이 핵심이며, 마크를 점에서 선으로 바꾸거나 스케일을 선형에서 로그로 변경해도 다른 요소들은 그대로 유지된다.
선언형 프로그래밍의 우아함은 D3.js와 Plot의 차이에서 극명하게 드러난다. D3.js에서는 “어떻게 그릴지” 단계별로 명령해야 한다: 선택 → 데이터 바인딩 → DOM 조작 → 스타일 설정. 반면 Plot에서는 “무엇을 그릴지”만 선언하면 된다: Plot.dot(data, {x: "flipper_length", y: "body_mass", fill: "species"}). 이러한 절차를 통해 과학적 사고—가설, 매핑, 검증, 개선—를 직관적인 코드로 표현할 수 있게 해준다.
그림 8.3 코드에서 가장 중요한 통찰은 ggplot2와 완전히 동일한 문법 구조를 따른다는 점이다. 먼저 penguins_data라는 데이터셋을 정의하고, 이를 x, y, fill 채널로 미학적 매핑을 수행한다. 그래프 기본 형태는 Plot.dot로 정의하는데, ggplot2 geom_point()와 정확히 대응된다. 색상 범위와 축 설정을 통한 척도 조정, tip 옵션을 통한 상호작용 기능까지 모든 요소가 Grammar of Graphics의 7계층 구조를 충실히 따른다. 이를 통해 D3.js 복잡한 DOM 조작과 단계별 렌더링 과정 없이도, 선언적 문법만으로 고품질 시각화를 단 몇 줄로 구현할 수 있게 된다.
8.2 표 문법
과학 논문에서 표는 정확성과 완전성의 상징이다. 20세기 대부분의 기간 동안 연구자들은 타자기로 표를 만들거나, Microsoft Excel에서 셀을 병합하고 테두리를 그으며 수작업으로 표를 디자인해왔다. 이후 LaTeX의 tabular 환경이나 R의 기본 data.frame 출력이 등장했지만, 여전히 복잡한 헤더 구조나 다층 그룹화를 표현하기는 어려웠다. 무엇보다 “표를 어떻게 그릴지”에 대한 기술적 세부사항에 매몰되어 “표가 무엇을 전달해야 하는지”라는 본질적 질문에 집중하기 어려웠다.
이러한 한계를 극복하기 위해 등장한 것이 gt 패키지의 표 문법(Grammar of Tables) 철학이다. ggplot2가 그래프 제작에 혁명을 일으킨 것처럼, gt는 표 제작에서 “무엇을 보여줄지”에 집중할 수 있게 해준다. 실험 결과의 모든 숫자가 정확히 기록되어야 하고, 통계적 의미가 명확하게 전달되어야 한다는 과학적 요구사항을 만족하면서도, 단순히 데이터를 나열하는 것이 아니라 표의 구조와 의미를 체계적으로 설계할 수 있게 된 것이다.
8.2.1 gt: 표의 해부학적 구조
gt 패키지는 “Grammar of Tables”를 구현하여 표를 7개의 해부학적 구조로 체계화한다. 이는 마치 인체를 두개골, 척추, 사지로 나누어 이해하듯이, 복잡한 과학 표를 구조적으로 분해하여 각 부분의 역할과 기능을 명확히 한다.
그림 8.4: 표문법 해부학적 구조
그림 8.4 에서 보듯이 gt의 핵심은 표를 의미 있는 구역으로 나누는 것이다. 헤더(Header)는 표의 제목과 부제목으로 전체적인 맥락을 제공하고, 스터브헤드(Stubhead)는 행 그룹의 범주를 정의한다. 칼럼 라벨(Column Labels)은 각 변수의 의미를 명시하며, 스터브(Stub)는 행의 범주나 그룹을 표시한다. 바디(Body)는 실제 데이터가 들어가는 핵심 영역이고, 요약(Summary)은 집계 통계를 제공한다. 마지막으로 각주(Footnotes)는 추가 설명과 메타데이터를 담는다.
이러한 구조적 접근법을 통해 표 제작자는 “이 셀을 어떻게 포맷할까?”가 아니라 “이 정보가 표의 어느 구조에 속하는가?”를 생각하게 된다. 결과적으로 더 논리적이고 일관성 있는 표를 만들 수 있으며, 독자도 표의 구조를 직관적으로 이해할 수 있게 된다.
library(gt)# SVG 다이어그램과 동일한 데이터로 gt의 7개 구조 시연data.frame( species =c("Adelie", "Chinstrap", "Gentoo"), count =c(152, 68, 124), bill_length =c("38.8±2.7", "48.8±3.3", "47.5±3.1"), body_mass =c("3701±459", "3733±384", "5076±504"))%>%gt()%>%# 1. 기본 테이블tab_header(# 2. 헤더 title ="Palmer 펭귄 연구 결과", subtitle ="부제목 (SUBTITLE)")%>%cols_label(# 3. 칼럼 라벨 species ="스터브헤드", count ="개체수", bill_length ="부리길이", body_mass ="체중")%>%grand_summary_rows(# 4. 요약 columns =count, fns =list("전체 요약"=~sum(.)))%>%tab_footnote(# 5. 각주"출처: Palmer Station LTER")%>%tab_source_note("소스 노트 (SOURCE NOTES)")# 6. 소스 노트
Palmer 펭귄 연구 결과
부제목 (SUBTITLE)
스터브헤드
개체수
부리길이
체중
Adelie
152
38.8±2.7
3701±459
Chinstrap
68
48.8±3.3
3733±384
Gentoo
124
47.5±3.1
5076±504
전체 요약
—
344
—
—
소스 노트 (SOURCE NOTES)
출처: Palmer Station LTER
표 8.1: Grammar of Tables 핵심 구조 시연
8.2.2 통계 표시 과학적 규약
과학 문서에서 숫자를 표시하는 것은 단순한 기록이 아니라 정확성과 재현성을 담보하는 약속이다. 19세기부터 축적되어온 과학적 관례는 독자가 연구의 신뢰성을 즉시 판단할 수 있는 시각적 단서들을 제공한다. 유효숫자 원칙에 따라 측정 도구 정밀도에 맞는 소수점 자릿수를 표시함으로써, 연구자는 측정 한계를 솔직하게 드러낸다. 예를 들어 “3.14159g”이 아닌 “3.14g”으로 표시하는 것은 저울의 정밀도가 소수점 둘째 자리까지임을 의미한다.
평균±표준편차 형태의 표기는 칼 피어슨이 1893년 “표준편차” 용어를 도입한 이후 각 학문 분야와 학술지 지침을 통해 점진적으로 정착되었다. 이러한 간결한 표기법은 데이터의 중심경향과 산포를 동시에 보여줌으로써, 독자가 변수의 분포 특성을 한눈에 파악할 수 있게 해준다. p-값 표시는 로널드 피셔가 1925년 0.05를 편의적 기준점으로 제시한 것이 확산되어 “< 0.001”, “< 0.01”, “< 0.05” 같은 임계값 표기가 관례화되었지만, 현대에는 정확한 p-값과 효과크기를 함께 보고하는 것이 권장된다. 신뢰구간은 네이만이 1937년 이론적으로 정립한 개념으로 “[하한, 상한]” 형태나 “± 오차” 형태로 표시하여 추정의 불확실성을 정량화한다. 큰 수치에는 천 단위 구분자(1,000)를 사용하여 가독성을 높이고, 모든 측정값에는 SI 국제단위계와 학술지 지침에 따라 적절한 단위를 병기한다. 이러한 규약들은 전 세계 과학 공동체가 동일한 “통계 언어”로 소통할 수 있게 하는 공통 기반이다.
# 과학적 표기 규약을 적용한 간단한 통계표data.frame( 비교 =c("Adelie vs Chinstrap", "Adelie vs Gentoo", "Chinstrap vs Gentoo"), 평균차이 =c("32 [-396, 460]", "-1,375 [-1,743, -1,007]", "-1,407 [-1,835, -979]"), p값 =c("0.975", "< 0.001***", "< 0.001***"))%>%gt()%>%tab_header("종간 체중 차이")%>%cols_label(평균차이 ="평균 차이 [95% CI] (g)")
종간 체중 차이
비교
평균 차이 [95% CI] (g)
p값
Adelie vs Chinstrap
32 [-396, 460]
0.975
Adelie vs Gentoo
-1,375 [-1,743, -1,007]
< 0.001***
Chinstrap vs Gentoo
-1,407 [-1,835, -979]
< 0.001***
표 8.2: 종간 체중 차이에 대한 통계 검정 결과
8.3 참고문헌
학술 논문에서 참고문헌은 단순한 부록이 아니라 지적 계보 증명이다. 새로운 연구가 기존 지식 위에 어떻게 구축되는지, 어떤 방법론적 전통을 따르는지, 어떤 이론적 틀을 사용하는지를 보여준다. 현대 과학 출판에서 참고문헌은 더 이상 수동으로 관리되지 않는다. 대신 BibTeX와 CSL(Citation Style Language)을 통한 자동화된 워크플로우가 표준이 되었다.
그림 8.5: 참고문헌 워크플로우 - BibTeX → CSL → 서식반영된 인용
8.3.1 BibTeX
BibTeX는 1985년부터 사용된 참고문헌 관리 표준 형식이다. 텍스트 기반의 구조화된 데이터베이스로 서지 정보를 관리하여 일관성과 재현성을 보장한다. 각 문헌은 고유한 키(@article{key})로 식별되며, 저자, 제목, 저널, 연도 등의 메타데이터가 체계적으로 구조화된다. 이러한 접근 방식은 하드웨어 독립적이고 버전 관리가 가능하며, 장기간 보존이 용이하다.
@article{Gorman2014,author = {Kristen B. Gorman and Tony D. Williams and William R. Fraser},title = {Ecological Sexual Dimorphism and Environmental Variability Within a Community of Antarctic Penguins (Genus Pygoscelis)},journal = {PLoS ONE},year = {2014},volume = {9},number = {3},pages = {e90081},doi = {10.1371/journal.pone.0090081}}@book{Wilkinson2005,author = {Leland Wilkinson},title = {The Grammar of Graphics},year = {2005},publisher = {Springer Science \& Business Media},edition = {2},doi = {10.1007/0-387-28695-0}}@Manual{RCoreTeam2024,title = {R: A Language and Environment for Statistical Computing},author = {{R Core Team}},organization = {R Foundation for Statistical Computing},year = {2024},url = {https://www.R-project.org/}}
8.3.2 CSL
인용 스타일 언어(Citation Style Language, CSL)는 참고문헌 서식화 혁명을 일으킨 XML 기반의 오픈 표준이다. 2008년 브루스 다르커스(Bruce D’Arcus)에 의해 개발된 CSL은 현재 전 세계 8,000개 이상의 저널과 출판사 스타일을 지원한다. 핵심 아이디어는 단순하지만 강력하다: 내용과 형식을 분리하여 BibTeX에 저장된 구조화된 데이터를 원하는 인용 스타일로 자동 변환하는 것이다. “한 번 작성하면 어디든 인용(Write Once, Cite Everywhere)” 원칙을 구현한다.
팔머 펭귄 데이터를 다루는 연구에서 기본 참고문헌을 인용해보자 (Gorman 기타, 2014). 시각화를 위해서는 그래프 문법의 이론적 배경 (Wilkinson, 2005)을 이해하는 것이 중요하며, 모든 분석은 R 통계 환경 (R Core Team, 2024)에서 수행되었다.
인용 스타일은 학문 분야마다 고유한 전통과 규범을 반영한다. 동일한 문헌도 인문학에서는 저자의 전체 이름과 출판 연도를 강조하는 시카고 스타일로, 공학에서는 번호와 기술적 세부사항을 중시하는 IEEE 형식으로, 심리학에서는 저자-날짜 체계 APA 스타일로 서로 다르게 표현된다. 이러한 다양성은 각 분야가 지식을 구축하고 전달하는 방식의 차이를 보여준다. CSL은 이러한 모든 스타일을 하나의 원본 데이터에서 자동으로 변환할 수 있게 하여, 연구자가 여러 저널에 투고할 때 반복 작업을 최소화한다. 아래 표 8.3 는 동일한 (Gorman 기타, 2014) 논문이 네 가지 주요 인용 스타일에서 어떻게 다르게 형식화되는지 보여준다.
스타일
형식
APA (심리학)
Gorman, K. B., Williams, T. D., & Fraser, W. R. (2014). Ecological sexual dimorphism and environmental variability within a community of Antarctic penguins (genus Pygoscelis). PLoS one, 9(3), e90081.
Nature (자연과학)
1. Gorman, K. B., Williams, T. D. & Fraser, W. R. Ecological sexual dimorphism and environmental variability within a community of Antarctic penguins (genus Pygoscelis). PLoS One 9, e90081 (2014).
IEEE (공학)
[1] K. B. Gorman, T. D. Williams, and W. R. Fraser, "Ecological sexual dimorphism and environmental variability within a community of Antarctic penguins (genus Pygoscelis)," PLoS One, vol. 9, no. 3, p. e90081, 2014.
Chicago (인문학)
Gorman, Kristen B., Tony D. Williams, and William R. Fraser. "Ecological Sexual Dimorphism and Environmental Variability within a Community of Antarctic Penguins (Genus Pygoscelis)." PLoS One 9, no. 3 (2014): e90081.
표 8.3: 분야별 인용 스타일 비교 - 동일한 논문의 서로 다른 인용 형식
8.3.3 문서 코드화 참고문헌
현대 연구자들은 더 이상 수동으로 참고문헌을 관리하지 않는다. 대신 자동화된 생태계가 형성되어 있다. Zotero나 Mendeley 같은 참고문헌 관리 도구는 논문 PDF에서 자동으로 메타데이터를 추출하고 BibTeX 형식으로 내보낸다. DOI 시스템은 디지털 객체 식별자로 문헌의 영구적 접근성을 보장하며, CrossRef API를 통해 출판사 간 참고문헌 데이터가 실시간으로 공유된다. ORCID는 연구자 고유 식별자로 저자 동정 문제를 해결한다.
이러한 시스템은 Quarto와 같은 Document as Code 플랫폼에서 완전히 통합된다. 연구자는 .bib 파일을 Git으로 버전 관리하고, CSL 스타일을 프로젝트별로 설정하며, 렌더링 시점에 모든 인용이 자동으로 형식화된다.
갈릴레오가 “수학은 우주가 쓰여진 언어”라고 했듯이, 현대 과학에서 수식은 단순한 계산 도구를 넘어 현상을 이해하고 예측하는 핵심 언어가 되었다. 그림 8.6 에서 보듯이, 물리학의 \(F = ma\)에서 생물학의 개체군 성장 모델까지, 모든 과학 분야에서 수식은 복잡한 현실을 명확하고 간결한 관계식으로 표현하는 강력한 도구 역할을 한다. 과학 문서에서 수식은 단순한 기호의 나열이 아니라 과학적 사고의 정수를 담고 있다.
그림 8.6: 과학 분야별 수식의 역할
8.4.1\(\LaTeX\) 수식
LaTeX 수식 시스템이 1970년대 도널드 크누스(Donald Knuth)에 의해 개발된 이후, 수학적 표현의 정확성과 아름다움에서 타의 추종을 불허하는 표준이 되었다. 단순히 예쁜 수식을 만드는 것이 아니라, 수학적 의미를 시각적으로 정확하게 전달하는 것이 LaTeX의 철학이다. 분수의 위아래 정렬, 적분 기호의 적절한 크기, 행렬의 균형 잡힌 배치 등 모든 세부사항이 수학적 직관을 돕는 방향으로 설계되어 있다.
현대 웹 환경에서는 MathJax와 KaTeX 같은 JavaScript 라이브러리가 LaTeX 문법을 브라우저에서 실시간으로 렌더링한다. 쿼토는 이러한 기술을 완벽하게 통합하여, 연구자가 LaTeX 문법으로 작성한 수식이 HTML, PDF, Word 등 모든 출력 형식에서 일관되게 표현되도록 한다. 이는 “한 번 작성하면 어디든 출판(Write Once, Publish Anywhere)” 철학의 구현이다.
통계 모형
펭귄 데이터를 분석할 때 직면하는 첫 번째 질문은 “날개 길이가 체중을 예측할 수 있는가?”이다. 이를 수학적으로 표현하면 선형 회귀 모델이 된다:
간단해 보이는 식에는 깊은 통계적 사고가 담겨 있다. \(\beta_0\)는 날개 길이가 0일 때의 예상 체중이지만, 실제로는 두 변수 관계의 기준점을 의미한다. \(\beta_1\)은 날개 길이가 1mm 증가할 때 체중이 얼마나 변하는지를 나타내며, 이는 생태학적으로 의미 있는 관계의 크기를 정량화한다. 가장 중요한 것은 \(\epsilon_i \sim \mathcal{N}(0, \sigma^2)\) 오차항인데, 이는 생물학적 변이의 존재를 인정하고 측정할 수 없는 요인들의 영향을 수식에 포함시킨 것이다.
행렬 대수
현실의 펭귄은 날개 길이 하나만으로 설명되지 않는다. 부리 길이, 부리 깊이, 체중, 성별, 서식지 등 다양한 변수가 복합적으로 작용한다. 이런 다변량 관계를 효율적으로 표현하는 것이 행렬 표기법이다:
이 간결한 식 안에는 엄청난 정보가 압축되어 있다. \(\mathbf{Y}\)는 모든 펭귄의 체중 벡터이고, \(\mathbf{X}\)는 각 펭귄의 모든 형태학적 특성을 담은 설계 행렬이며, \(\boldsymbol{\beta}\)는 각 특성이 체중에 미치는 영향을 나타내는 계수 벡터다. 300여 마리 펭귄의 복잡한 관계를 단 한 줄로 표현할 수 있는 것은 행렬 대수의 추상화 능력 덕분이다.
8.4.2\(\LaTeX\)로 그리는 과학의 계층
하나의 펭귄을 이해하려면 분자부터 지구까지 모든 층위를 넘나들어야 한다. \(\LaTeX\)는 이 모든 스케일의 과학적 진실을 정확히 표현하는 유일한 언어다. 각 과학 분야는 고유한 \(\LaTeX\) 문법을 발전시켜왔고, 쿼토는 이 모든 것을 하나의 문서에서 완벽하게 렌더링한다.
분자 수준: 생화학의 \(\LaTeX\) 화학식
펭귄의 생리학적 적응을 이해하는 핵심은 분자 수준에서 일어나는 효소 반응이다. 특히 장시간 잠수 중 산소 농도가 낮아질 때 근육 세포의 효소 반응은 미하일리스-멘텐 방정식을 따른다:
이 간단해 보이는 식에서 \(v\)는 반응속도, \(V_{\text{max}}\)는 최대 대사율, \([S]\)는 기질농도, \(K_m\)은 효소의 기질 친화도를 나타내며, 이는 극한 환경에서의 생존 전략을 정량화한 것이다. \(\LaTeX\)의 \frac{}{} 분수 표기와 \text{} 명령어만이 이러한 생화학적 정보를 출판 품질로 정확히 조판할 수 있다. Word나 다른 편집기로는 불가능한 정교한 아래첨자, 분수 정렬, 수학 기호들이 \(\LaTeX\)에서는 자연스럽게 표현된다.
개체 수준: 물리학의 \(\LaTeX\) 벡터 표현
펭귄의 3차원 수영 역학을 기술할 때 \(\LaTeX\)의 \mathbf{}, \nabla 기호들이 복잡한 물리량을 간결하게 표현한다:
동시에 펭귄들이 서식하는 바다에서 일어나는 탄산 평형 반응은 해양 산성화의 핵심 메커니즘이다. 대기 중 이산화탄소가 해수에 용해되어 pH를 낮추는 이 과정은 펭귄들의 먹이인 크릴과 물고기들에게 직접적인 영향을 미친다:
\[\ce{CO2 + H2O <--> H2CO3 <--> H+ + HCO3-}\]
물리적 해양학의 복잡한 편미분방정식과 화학적 해양학의 정교한 평형 반응식을 동시에 담을 수 있는 것은 \(\LaTeX\)뿐이다. \ce{} 명령어를 통한 화학식 표기와 \partial, \nabla 기호를 통한 물리 방정식이 하나의 문서에서 완벽하게 조화를 이룬다.
지구 수준: 기후과학의 \(\LaTeX\) 복합 시스템
지구 전체의 복사 평형은 \(\LaTeX\)의 align 환경과 조건부 수식으로만 정확히 표현된다:
\[\frac{S_0}{4}(1-\alpha) = \sigma T^4\]
IPCC 기후변화 보고서가 \(\LaTeX\)를 사용하는 이유는 이런 복잡한 지구시스템 방정식들을 출판 품질로 조판할 수 있기 때문이다.
분자에서 지구까지, \(\LaTeX\)는 모든 스케일의 과학을 하나의 문서에 담을 수 있는 유일한 도구다. 이것이 Nature, Science 같은 최고 학술지들이 \(\LaTeX\) 제출을 요구하는 이유이며, 과학자들이 반드시 익혀야 하는 필수 기술인 이유다.
8.5 다이어그램 언어
복잡한 과정, 시스템 구조, 개념 간 관계는 때로 텍스트나 수식으로 설명하기 어렵다. 남극 펭귄들의 생태계처럼 수많은 요소들이 복잡하게 얽힌 현상을 이해하려면 시각적 표현이 필수다. 과학 문서에서 다이어그램은 단순한 그림이 아니라 개념적 지도의 역할을 한다.
전통적으로 과학자들은 PowerPoint나 Visio 같은 GUI 도구로 다이어그램을 만들어왔다. 하지만 이런 도구들은 문서 코드화 패러다임과 충돌한다. 이미지 파일은 버전 관리가 어렵고, 수정 내역을 추적하기 힘들며, 협업 시 충돌이 빈번하다. 반면 텍스트 기반 다이어그램 언어는 코드처럼 작성하고 관리할 수 있어, 과학 문서의 모든 요소를 하나의 일관된 워크플로우 안에서 다룰 수 있게 한다.
8.5.1 Mermaid
Mermaid는 텍스트 기반으로 다양한 다이어그램을 생성하는 자바스크립트 라이브러리로, 쿼토에서 네이티브 지원된다. 가장 큰 장점은 직관적인 문법이다. A --> B라고 쓰면 A에서 B로 향하는 화살표가 생성되는 식이다. 이는 과학자들이 연구의 논리적 흐름을 자연스럽게 코드로 표현할 수 있게 한다.
펭귄 연구에서 Mermaid가 빛을 발하는 순간은 복잡한 생태학적 관계를 단순명료하게 시각화할 때다. 먹이사슬, 서식지 간 이동, 번식 주기같은 다층적 관계를 플로우차트나 다이어그램으로 표현하면, 독자들이 한눈에 전체 시스템을 파악할 수 있다.
```{mermaid}%%| label: fig-research-workflow%%| echo: true%%| fig-cap: "펭귄 연구 핵심 워크플로우"graph LR A[가설 설정] --> B[데이터 수집] B --> C[분석 모델링] C --> D{결과 검증} D -->|유의미| E[논문 작성] D -->|불충분| B E --> F[출판]```
graph LR
A[가설 설정] --> B[데이터 수집]
B --> C[분석 모델링]
C --> D{결과 검증}
D -->|유의미| E[논문 작성]
D -->|불충분| B
E --> F[출판]
그림 8.7: 펭귄 연구 핵심 워크플로우
과학 연구의 본질을 5단계로 압축한 이 다이어그램은 Mermaid의 간결함과 명확성을 보여준다. 복잡한 연구 과정을 누구나 이해할 수 있는 시각적 언어로 표현했다. 특히 조건부 분기({결과 검증})와 피드백 루프가 과학적 방법의 반복적 특성을 정확히 포착한다.
```{mermaid}%%| label: fig-data-structure %%| fig-cap: "펭귄 데이터 핵심 관계"%%| fig-width: 5%%| echo: trueerDiagram PENGUIN { string species string island float body_mass_g } SPECIES { string name } ISLAND { string name string ecosystem } PENGUIN ||--|| SPECIES : belongs_to PENGUIN ||--|| ISLAND : lives_on```
erDiagram
PENGUIN {
string species
string island
float body_mass_g
}
SPECIES {
string name
}
ISLAND {
string name
string ecosystem
}
PENGUIN ||--|| SPECIES : belongs_to
PENGUIN ||--|| ISLAND : lives_on
그림 8.8: 펭귄 데이터 핵심 관계
Entity Relationship Diagram(ERD)은 Mermaid의 또 다른 강력한 기능이다. 복잡한 데이터베이스 스키마를 관계의 핵심만 추려 표현할 수 있다. 위의 예제는 펭귄-종-서식지의 삼각 관계를 명확히 보여주며, ||--|| 기호로 일대일 관계를 직관적으로 표현한다. 이런 데이터 모델링의 시각화는 연구팀이 데이터 구조를 이해하고 분석 전략을 세우는 데 필수적이다.
8.5.2 GraphViz
GraphViz는 DOT 언어를 사용하여 복잡한 그래프와 네트워크를 표현하는 강력한 도구다. Mermaid가 직관적이고 빠른 스케치에 적합하다면, GraphViz는 정밀하고 복잡한 관계망을 표현할 때 진가를 발휘한다.
특히 학술 연구에서 GraphViz가 필수적인 이유는 인용 네트워크, 공저자 관계, 개념 간 연결 같은 복잡한 구조를 처리할 수 있기 때문이다. DOT 언어의 rankdir, shape, color 같은 세밀한 속성 제어로 출판 품질의 다이어그램을 생성할 수 있다.
그림 8.9 예제는 DOT 언어의 시간적 흐름 표현력을 보여준다. rankdir=LR로 좌우 배치를 설정하면 연구의 시간적 진화가 한눈에 들어온다. 1980년대 이론적 배경에서 시작해 Gorman의 2014년 원본 연구, Horst의 2020년 데이터 패키지, 그리고 다양한 후속 연구들로 이어지는 지적 계보가 명확히 드러난다. 색상 구분(lightyellow → lightblue → lightgreen → white)으로 연구의 발전 단계를 시각적으로 구분하고, 교차 인용 관계(methods -> study1)까지 표현해 학문적 상호작용의 복잡성을 포착한다.
텍스트 기반 다이어그램의 진정한 가치는 버전 관리가 가능하다는 점이다. 연구가 진행되면서 새로운 논문이 추가되거나 관계가 변경될 때, Git을 통해 변화를 추적하고 협업자들과 공유할 수 있다. 이는 과학 문서의 모든 요소를 코드로 관리하는 문서 코드화 패러다임의 완성이다.
8.6 메타데이터
모든 과학 문서는 겉으로 보이는 내용 뒤에 메타데이터라는 숨겨진 정보 층위를 가지고 있다. 문서의 제목, 저자, 출판일, 키워드, 라이선스 정보부터 렌더링 옵션, 출력 형식, 스타일 설정까지 모든 것이 메타데이터의 영역이다. 이는 마치 생물의 DNA가 외형을 결정하는 것처럼, 문서의 최종 모습을 결정하는 문서의 DNA다.
그림 8.10: 메타데이터 워크플로우 - 프로젝트 → 문서 → 출력물 통제 흐름
8.6.1 YAML
쿼토가 YAML을 메타데이터 언어로 선택한 이유는 인간의 직관과 기계의 정확성을 동시에 만족하기 때문이다. YAML(Yet Another Markup Language)의 들여쓰기 기반 구조는 마치 펭귄 서식지의 계층적 생태계를 묘사하는 것처럼 자연스럽다. 둥지 → 군집 → 개체군 → 생태계로 이어지는 위계와 같이, YAML도 프로젝트 → 책 → 챕터 → 섹션으로 이어지는 구조를 직관적으로 표현한다.
과학자들이 복잡한 실험 설정을 기록할 때 중괄호나 괄호보다는 들여쓰기와 콜론을 사용하는 것이 자연스러운 것처럼, 쿼토도 이런 인간 친화적 문법을 채택했다. 또한 Git과 같은 버전 관리 시스템에서 변경사항을 추적하기 쉽고, 협업 시 갈등(conflict)이 적게 발생한다.
기본 문서 메타데이터
---title:"남극 펭귄의 생태학적 성적 이형성"author:-name:"김생태"affiliation:"한국해양과학기술원"date: todayabstract: | Palmer Station LTER 데이터를 활용한 펭귄 종별 성적 이형성 분석 연구keywords:[펭귄, 성적이형성, 남극생태학]---
문서 메타데이터는 과학 논문의 신원확인서와 같다. 제목과 저자 정보는 연구의 책임소재를 명확히 하고, 초록은 독자가 내용을 미리 파악할 수 있게 한다. date: today처럼 동적 값을 사용하면 매번 렌더링할 때마다 최신 날짜가 자동으로 입력된다. 키워드는 검색 엔진과 학술 데이터베이스에서 논문이 발견될 가능성을 높이는 디지털 표지판 역할을 한다.
초록(abstract)은 독자가 내용을 미리 파악할 수 있게 한다. 파이프 기호(|)로 시작하는 초록은 여러 줄의 텍스트를 자연스럽게 처리하는 YAML의 강력한 기능이다. 이는 복잡한 과학적 내용을 설명할 때 특히 유용하다.
하나의 소스, 다양한 출력이라는 쿼토의 철학이 바로 이 설정에서 구현된다. 동일한 펭귄 연구 데이터와 분석 코드로부터 웹 페이지, PDF 논문, 워드 문서를 동시에 생성할 수 있다. HTML은 상호작용성을 중시하여 code-fold로 코드를 접었다 펼 수 있고, PDF는 전통적인 학술 출판을 위해 \(\LaTeX\) 엔진을 사용한다. DOCX는 협업 환경에서 동료들이 검토할 수 있도록 워드 템플릿을 적용한다.
이런 다중 출력 전략은 마치 펭귄이 물속과 육지에서 서로 다른 행동 양식을 보이는 것과 같다. 같은 연구 내용이지만 매체의 특성에 맞춰 최적화된 형태로 나타난다.
8.6.2 고급 프로젝트 설정
프로젝트 수준 설정은 연구 프로그램 전체의 청사진이다. _quarto.yml 파일 하나가 수십 개의 장과 수백 페이지의 콘텐츠를 통제한다. 책 구조를 part와 chapters로 계층화하는 것은 펭귄 연구를 분류학(종 구분) → 형태학(체형 분석) → 생태학(서식지 연구) 순서로 조직하는 것과 같다. 각 챕터는 독립적으로 작성되지만 전체적으로는 하나의 일관된 내러티브를 형성한다.
쿼토에서 공식적으로 지원하지는 않지만, 쥴리아 기반 과학 컴퓨팅 프로젝트와의 호환성을 위해 알아두면 유용하다.
메타데이터의 진정한 힘은 재현가능한 매개변수화에서 나타난다. 동일한 분석 템플릿으로 아델리, 젠투, 턱끈펭귀 각각에 대한 보고서를 자동 생성할 수 있다. 이는 마치 하나의 DNA 서열이 환경 조건에 따라 다른 표현형을 만들어내는 후성유전학적 메커니즘과 유사하다.
YAML 메타데이터는 문서의 환경변수로 작용하여, 코드 실행 방식(execute: echo: false)부터 출력 형태까지 모든 것을 제어한다. 이런 설정 기반 접근법이야말로 문서 코드화 패러다임의 핵심이며, 과학적 재현성을 보장하는 기술적 기반이다.
8.7 통계 모델링 언어
현대 과학에서 데이터는 단순한 숫자의 나열이 아니다. 모든 측정값에는 불확실성이 내재되어 있고, 모든 패턴에는 무작위성이 섞여 있다. 이러한 불확실성을 정량화하고 추론하는 것이 통계 모델링의 핵심이며, 이를 위해서는 전문화된 모델링 언어가 필요하다.
8.7.1 Stan
Stan은 베이지안 사고를 그대로 코드로 옮길 수 있는 혁명적인 확률적 프로그래밍 언어다. 전통적인 통계 소프트웨어는 사용자가 데이터를 미리 정해진 모델 형태에 맞춰야 하지만, Stan은 반대로 연구자의 과학적 직관을 수학 식과 코드로 직접 표현할 수 있게 한다.
펭귄 생태학자가 “체중은 날개 길이와 비례하지만 종마다 다를 수 있고, 측정 오차가 있을 것”이라고 생각하면, Stan에서는 이 직관을 그대로 body_mass ~ normal(alpha + beta * flipper_length, sigma) 같은 방식으로 작성할 수 있다. 이는 수학적 모델과 코드의 완벽한 일치를 만든다.
Stan의 가장 강력한 특징은 선언적(declarative) 문법이다. body_mass ~ normal(...)은 단순한 코드가 아니라 과학적 가설의 수학적 표현이다. 이는 펭귄의 체중이 정규분포를 따른다는 생물학적 가정을 직접적으로 코드로 옮긴 것이다. <lower=0>같은 제약 조건은 물리적 현실을 반영하여(표준편차는 음수가 될 수 없다) 모델의 과학적 타당성을 보장한다.
# Stan 모델 실행stan_data<-list( N =nrow(penguins), flipper_length =penguins$flipper_length_mm, body_mass =penguins$body_mass_g)model<-stan( file ="penguin_regression.stan", data =stan_data, chains =4)
Stan의 진정한 힘은 과학적 사고와 코드 사이의 거리를 없애는 것에 있다. 수많은 통계 패키지와 달리 Stan은 연구자가 “사전 분포를 어떻게 설정할까?”, “불확실성을 어떻게 정량화할까?” 같은 베이지안의 철학적 문제들을 직접 마주하게 만든다. 이는 더 깊이 생각하는 과학으로 이끄는 교육적 가치를 지닌다.
8.7.2 tidymodels
반면 tidymodels는 통합된 인터페이스로 모델링의 복잡성을 해결한다. 전통적으로 R에서 머신러닝을 할 때는 lm(), randomForest(), svm() 등 각각 다른 패키지의 다른 문법을 기억해야 했다. tidymodels는 단일한 문법으로 모든 모델을 다룰 수 있게 한다.
마치 ggplot2가 그래프 문법(Grammar of Graphics)을 제공하듯, tidymodels는 모델링 문법(Grammar of Modeling)을 제공한다. 데이터 전처리(recipe) → 모델 정의(parsnip) → 워크플로우 구성(workflow) → 평가(yardstick)와 같은 일관된 단계를 따르면, 어떤 모델을 사용하든 동일한 방식으로 작업할 수 있다.
# tidymodels 워크플로우penguins_recipe<-recipe(body_mass_g~., data =penguins)%>%step_normalize(all_numeric_predictors())rf_spec<-rand_forest()%>%set_mode("regression")penguins_wf<-workflow()%>%add_recipe(penguins_recipe)%>%add_model(rf_spec)penguins_fit<-fit(penguins_wf, data =penguins)
tidymodels의 레시피(recipe) 체계는 데이터 전처리를 요리 레시피처럼 단계별로 작성할 수 있게 한다. step_normalize(), step_dummy(), step_pca() 같은 전처리 단계들을 순서대로 추가하면, 전체 전처리 과정이 재현가능한 코드가 된다. 워크플로우(workflow)는 레시피와 모델을 단일 객체로 묶어 전체 과정을 하나의 코드 블록으로 관리할 수 있게 한다.
두 DSL의 철학적 차이는 명확하다. Stan은 베이지안 사고의 노출을 통해 더 깊은 통계적 사고를 유도하고, tidymodels는 일관된 인터페이스로 복잡도를 감소시켜 생산성을 높인다. 둘 다 현대 과학에서 없어서는 안 될 도구들이다.
8.8 코드 문서화
과학 연구에서 코드는 이제 실험 도구만큼 중요하다. 하지만 코드가 아무리 정교해도 다른 연구자가 이해하고 재현할 수 없다면 과학적 가치가 반감된다. 코드 문서화는 단순히 주석을 다는 것이 아니라, 연구의 재현가능성을 보장하는 과학적 의무다.
8.8.1 Roxygen2
Roxygen2는 R 함수를 문서화하는 표준 도구로, 코드와 문서를 하나로 통합하는 혁신적 접근법을 제공한다. 전통적인 방식에서는 코드와 문서가 분리되어 있어 코드가 변경될 때마다 문서를 별도로 수정해야 했다. 하지만 Roxygen2는 함수 정의 바로 위에 특수한 주석 형태로 문서를 작성하게 하여, 코드와 문서가 동기화된 상태를 유지한다.
과학 연구에서 Roxygen2가 특히 중요한 이유는 재현가능한 연구를 지원하기 때문이다. 펭귄 생태 연구처럼 복잡한 분석 함수들이 많은 프로젝트에서, 각 함수가 어떤 매개변수를 받고 무엇을 반환하는지 명확히 문서화하면 다른 연구자들이 코드를 이해하고 재사용할 수 있다. 이러한 접근법은 과학의 누적적 발전에 필수적이다.
#' 펭귄 형태학적 특성 요약#' #' 팔머 펭귄 데이터에서 종별 기술통계량을 계산합니다.#' #' @param data 펭귄 데이터프레임#' @param by_species 종별로 분리할지 여부 (기본값: TRUE)#' @return 요약통계 tibble (n, 평균값들 포함)#' #' @examples#' summarize_penguins(palmerpenguins::penguins)#' #' @exportsummarize_penguins<-function(data, by_species=TRUE){if(by_species){result<-data%>%group_by(species)%>%summarise( n =n(), bill_length_mean =mean(bill_length_mm, na.rm =TRUE), flipper_length_mean =mean(flipper_length_mm, na.rm =TRUE), body_mass_mean =mean(body_mass_g, na.rm =TRUE), .groups ="drop")}else{result<-data%>%summarise( n =n(), bill_length_mean =mean(bill_length_mm, na.rm =TRUE), flipper_length_mean =mean(flipper_length_mm, na.rm =TRUE), body_mass_mean =mean(body_mass_g, na.rm =TRUE))}return(result)}#' 펭귄 데이터 품질 검사#' #' 데이터의 결측값과 이상치를 빠르게 점검합니다.#' #' @param data 펭귄 데이터프레임#' @return 품질 검사 결과 리스트#' #' @examples#' check_quality(palmerpenguins::penguins)#' #' @exportcheck_quality<-function(data){list( missing =data%>%summarise(across(everything(), ~sum(is.na(.)))), outliers ="이상치 탐지 완료")}
간단한 예제는 Roxygen2의 핵심 철학을 보여준다. 복잡한 태그들을 나열하는 대신 꼭 필요한 정보만 명확히 전달하는 것이다. @param, @return, @examples의 삼박자만으로도 함수의 목적과 사용법을 완벽히 설명할 수 있다.
코드와 문서의 동기화가 Roxygen2의 진정한 가치다. 전통적 방식에서는 함수를 수정할 때마다 별도 문서 파일을 찾아 업데이트해야 했다. 하지만 Roxygen2는 함수 바로 위에 문서를 배치해 한 곳에서 모든 것을 관리할 수 있게 한다. 이러한 접근법은 과학 연구의 재현가능성과 투명성을 크게 높인다.
8.8.2 패키지 수준 문서화
개별 함수 문서화를 넘어서, 연구 프로젝트 전체를 R 패키지 형태로 구조화하는 것이 현대 과학 연구의 표준이다. 패키지는 단순히 함수들의 모음이 아니라, 연구의 전체 맥락과 철학을 담는 그릇이다. 펭귄 생태 연구처럼 복잡한 분석 파이프라인을 가진 프로젝트에서 패키지 구조는 연구의 논리적 흐름을 명확히 드러낸다.
패키지 수준 문서화에서 가장 중요한 것은 DESCRIPTION 파일이다. 파일은 패키지 메타데이터를 담고 있으며, 연구 목적, 저자 정보, 의존성, 라이선스 등 연구 프로젝트의 DNA를 정의한다. 또한 README.md와 vignette을 통해 연구의 전체적인 맥락과 사용법을 제공한다.
Package: penguintoolsTitle: Palmer Station Penguin Analysis ToolsVersion:0.1.0Authors@R:person("김생태", "ecology.kim@kiost.ac.kr", role =c("aut", "cre"))Description: 팔머 펭귄 데이터 분석을 위한 핵심 도구들License: MITImports: dplyr, ggplot2Suggests: testthat
8.8.3 테스트와 함께하는 문서화
테스트는 문서화의 또 다른 형태다. 특히 과학 연구에서 테스트는 단순히 버그를 찾는 도구가 아니라, 함수가 어떻게 작동해야 하는지를 명확히 보여주는 실행 가능한 명세서다. testthat 패키지를 활용한 테스트는 코드의 정확성을 보장하면서 동시에 사용법을 구체적인 예제로 제시한다.
펭귄 분석 함수들의 테스트를 작성할 때, 각 테스트는 과학적 기대값을 반영해야 한다. 예를 들어, 종별 분석 함수는 반드시 3개 펭귄 종(Adelie, Chinstrap, Gentoo)의 결과를 반환해야 하고, 형태학적 측정값들은 생물학적으로 타당한 범위 내에 있어야 한다.
test_that("펭귄 요약 함수가 정상 작동한다", {result<-summarize_penguins(penguins)expect_s3_class(result, "data.frame")expect_equal(nrow(result), 3)# 3개 종expect_true(all(c("species", "n")%in%names(result)))})
8.8.4 소품문
소품문(Vignette)은 패키지 문서화의 최고 형태다. 개별 함수 설명을 넘어서, 연구의 전체 스토리를 처음부터 끝까지 보여주는 종합 가이드다. 펭귄 연구에서 vignette은 단순한 사용 설명서가 아니라, 과학적 질문에서 시작해 결론까지 이어지는 완전한 분석 여정을 독자와 함께 걸어가는 안내서다.
좋은 vignette의 핵심은 맥락과 목적을 명확히 제시하는 것이다. “이 함수를 이렇게 사용하세요”가 아니라 “이런 과학적 질문이 있고, 데이터로 이렇게 답을 찾을 수 있습니다”의 접근법이다. 독자는 코드를 배우는 것이 아니라 연구 방법론을 학습한다.
---title:"펭귄 형태학 분석: 종별 차이 탐구"output: rmarkdown::html_vignette---## 연구 질문팔머 기지 펭귄들은 종별로 어떤 형태학적 차이를 보일까?## 데이터 탐색library(penguintools)result <-summarize_penguins(palmerpenguins::penguins)
코드 문서화는 과학의 투명성을 실현하는 핵심 도구다. Roxygen2, 테스트, vignette으로 구성된 삼각 체계는 연구의 모든 측면을 문서화하여 재현가능하고 신뢰할 수 있는 과학을 만든다.
8.9 DSL의 광대한 우주
이 장에서 다룬 8가지 핵심 DSL—그래프 문법, 표 문법, 참고문헌 생태계, 수식 시스템, 다이어그램 언어, 메타데이터, 통계 모델링, 코드 문서화—은 현대 과학기술 문서 작성의 중추를 이룬다. 하지만 실제로는 더 넓은 생태계가 존재한다.
지리공간 분석을 다루는 연구자들은 GeoJSON과 TopoJSON으로 공간 데이터를 표현하고, 생물정보학자들은 Snakemake와 Nextflow로 복잡한 분석 파이프라인을 구축한다. 3D 분자 구조를 연구하는 화학자들은 PDB 형식과 X3D를 활용하며, 실시간 데이터를 다루는 엔지니어들은 InfluxDB Line Protocol과 Prometheus로 시계열을 관리한다.
웹 기술의 진화는 Web Components, Lit, Alpine.js 같은 인터랙티브 요소들을 학술 문서에 통합할 수 있게 했고, 프레젠테이션 영역에서는 Reveal.js, Beamer, Slidev가 각자의 강점으로 연구 발표를 지원한다. 접근성을 위한 ARIA 속성, 국제화를 위한 XLIFF, 워크플로우 자동화를 위한 CWL과 WDL도 현대 과학 문서 생태계의 중요한 구성원이다.
음악 이론을 연구하는 학자는 ABC Notation으로 악보를 텍스트화하고, 언어학자는 ELAN과 Praat 형식으로 음성 데이터를 분석한다. 고고학자는 KML로 발굴 현장을 기록하고, 천문학자는 FITS 헤더로 관측 데이터의 메타정보를 관리한다. 경제학자는 DSGE 모델을 Dynare 언어로 구현하고, 심리학자는 PsychoPy의 Builder 언어로 실험을 설계한다.
이 모든 DSL들은 결국 하나의 목표를 향한다: 재현가능하고, 접근가능하고, 아름다운 과학 문서의 창조. AI 시대가 도래하면서 ChatGPT, Claude, Copilot 같은 AI 도구들이 이 모든 DSL을 이해하고 생성할 수 있게 되었다. 이제 과학자들은 “ggplot2로 회귀분석 그래프를 그려줘”, “이 데이터를 gt 표로 만들어줘”, “Stan 코드로 베이지안 모델을 작성해줘”라고 요청하기만 하면 된다.
문서 코드화 패러다임에서 이러한 DSL들은 단순한 도구가 아니라 과학적 사고를 코드로 표현하는 언어다. 데이터에서 시작해 분석을 거쳐 논문으로 완성되는 전 과정이 버전 관리되고, 재현가능하며, 협업 가능한 형태로 진화하고 있다. 쿼토는 이 모든 DSL들을 하나의 통합된 워크플로우로 엮어내는 오케스트라의 지휘자 역할을 한다.
미래의 과학 문서는 더욱 풍성해질 것이다. WebAssembly 기술로 브라우저에서 네이티브급 성능의 분석이 가능해지고, WebXR로 3차원 데이터를 직접 조작할 수 있으며, 실시간 협업 편집으로 전 세계 연구자들이 동시에 같은 문서를 작업할 수 있게 될 것이다. 블록체인 기반 출판으로 연구 데이터의 무결성이 영구 보장되고, AI 동료 검토자가 논문의 논리적 일관성과 통계적 타당성을 실시간으로 검증할 것이다.
하지만 기술이 아무리 발전해도 변하지 않을 것이 있다: 명확한 사고, 정확한 표현, 투명한 과정이라는 과학의 본질이다. DSL들은 이 본질을 구현하는 도구일 뿐이다. 중요한 것은 도구가 아니라, 도구를 통해 전달하고자 하는 과학적 진실이다.
💭 생각해볼 점
DSL의 다양성이 보여주는 것은 “모든 문제에는 최적의 언어가 있다”는 통찰이다. SQL의 선언적 단순함, ggplot2의 문법적 우아함, Stan의 확률적 정확성, Mermaid의 직관적 명확성 — 각각은 수십 년의 진화를 거쳐 특정 영역의 최강자가 되었다.
이제 AI가 이런 DSL들 사이의 장벽을 허물고 있다. ChatGPT에게 “펭귄 데이터를 분석해줘”라고 하면 ggplot2로 시각화하고, gt로 표를 만들고, Stan으로 모델링하고, BibTeX로 참고문헌을 정리하는 코드를 순식간에 생성한다. 하지만 역설적으로, AI를 제대로 활용하려면 각 DSL의 강점과 한계를 이해해야 한다. AI는 도구를 대체하는 것이 아니라 도구를 더 잘 쓰게 만드는 증폭기다.
다음 장에서는 이렇게 다양한 DSL로 작성된 쿼토 문서를 어떻게 아름답고 전문적인 출판물로 변환하는지 살펴본다. 마크다운의 단순함과 DSL의 전문성이 어떻게 조화를 이루어 과학적 서사를 완성하는지 확인해보자.
Gorman, K. B., Williams, T. D., & Fraser, W. R. (2014). Ecological Sexual Dimorphism and Environmental Variability Within a Community of Antarctic Penguins (Genus Pygoscelis). PLoS ONE, 9(3), e90081. https://doi.org/10.1371/journal.pone.0090081
R Core Team. (2024). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing. https://www.R-project.org/