class: center, middle, inverse, title-slide .title[ # 통계학 ] .subtitle[ ## 시각화 ] .author[ ### 이광춘 ] --- --- class: center, middle, inverse # Amscombe 데이터셋 --- name: anscombe-stat ### 기술통계량 .panelset[ .panel[.panel-name[데이터셋] .pull-left[ ```r library(tidyverse) data(anscombe) anscombe_tbl <- anscombe %>% pivot_longer(cols = everything(), names_to = "변수", values_to = "값") %>% mutate(데이터셋 = case_when(str_detect(변수, "1") ~ "1번 데이터셋", str_detect(변수, "2") ~ "2번 데이터셋", str_detect(변수, "3") ~ "3번 데이터셋", str_detect(변수, "4") ~ "4번 데이터셋")) %>% mutate(변수 = str_remove(변수, "\\d")) %>% select(데이터셋, 변수, 값) anscombe_tbl ``` ] .pull-right[ ``` # A tibble: 88 × 3 데이터셋 변수 값 <chr> <chr> <dbl> 1 1번 데이터셋 x 10 2 2번 데이터셋 x 10 3 3번 데이터셋 x 10 4 4번 데이터셋 x 8 5 1번 데이터셋 y 8.04 6 2번 데이터셋 y 9.14 7 3번 데이터셋 y 7.46 8 4번 데이터셋 y 6.58 9 1번 데이터셋 x 8 10 2번 데이터셋 x 8 # … with 78 more rows ``` ] ] .panel[.panel-name[평균] .pull-left[ ```r anscombe_tbl %>% group_by(데이터셋, 변수) %>% summarise(mean = mean(값)) %>% pivot_wider(names_from = 변수, values_from = mean) ``` ] .pull-right[ ``` # A tibble: 4 × 3 # Groups: 데이터셋 [4] 데이터셋 x y <chr> <dbl> <dbl> 1 1번 데이터셋 9 7.50 2 2번 데이터셋 9 7.50 3 3번 데이터셋 9 7.5 4 4번 데이터셋 9 7.50 ``` ] ] .panel[.panel-name[분산] .pull-left[ ```r anscombe_tbl %>% group_by(데이터셋, 변수) %>% summarise(var = var(값)) %>% pivot_wider(names_from = 변수, values_from = var) ``` ] .pull-right[ ``` # A tibble: 4 × 3 # Groups: 데이터셋 [4] 데이터셋 x y <chr> <dbl> <dbl> 1 1번 데이터셋 11 4.13 2 2번 데이터셋 11 4.13 3 3번 데이터셋 11 4.12 4 4번 데이터셋 11 4.12 ``` ] ] .panel[.panel-name[상관계수] .pull-left[ ```r custom_correlation <- function(df) { cor(df$x, df$y) } anscombe_tbl %>% pivot_wider(names_from=`변수`, values_from = `값`) %>% unnest(cols = c(x, y)) %>% group_by(데이터셋) %>% nest() %>% mutate(corr = map(data, custom_correlation)) %>% unnest(corr) ``` ] .pull-right[ ``` # A tibble: 4 × 3 # Groups: 데이터셋 [4] 데이터셋 data corr <chr> <list> <dbl> 1 1번 데이터셋 <tibble [11 × 2]> 0.816 2 2번 데이터셋 <tibble [11 × 2]> 0.816 3 3번 데이터셋 <tibble [11 × 2]> 0.816 4 4번 데이터셋 <tibble [11 × 2]> 0.817 ``` ] ] ] --- name: anscombe count: false ### 공룡 데이터 .panel1-anscombe-auto[ ```r *library(tidyverse) ``` ] .panel2-anscombe-auto[ ] --- count: false ### 공룡 데이터 .panel1-anscombe-auto[ ```r library(tidyverse) *anscombe_tbl ``` ] .panel2-anscombe-auto[ ``` # A tibble: 88 × 3 데이터셋 변수 값 <chr> <chr> <dbl> 1 1번 데이터셋 x 10 2 2번 데이터셋 x 10 3 3번 데이터셋 x 10 4 4번 데이터셋 x 8 5 1번 데이터셋 y 8.04 6 2번 데이터셋 y 9.14 7 3번 데이터셋 y 7.46 8 4번 데이터셋 y 6.58 9 1번 데이터셋 x 8 10 2번 데이터셋 x 8 # … with 78 more rows ``` ] --- count: false ### 공룡 데이터 .panel1-anscombe-auto[ ```r library(tidyverse) anscombe_tbl %>% * pivot_wider(names_from=`변수`, values_from = `값`) ``` ] .panel2-anscombe-auto[ ``` # A tibble: 4 × 3 데이터셋 x y <chr> <list> <list> 1 1번 데이터셋 <dbl [11]> <dbl [11]> 2 2번 데이터셋 <dbl [11]> <dbl [11]> 3 3번 데이터셋 <dbl [11]> <dbl [11]> 4 4번 데이터셋 <dbl [11]> <dbl [11]> ``` ] --- count: false ### 공룡 데이터 .panel1-anscombe-auto[ ```r library(tidyverse) anscombe_tbl %>% pivot_wider(names_from=`변수`, values_from = `값`) %>% * unnest(cols = c(x, y)) ``` ] .panel2-anscombe-auto[ ``` # A tibble: 44 × 3 데이터셋 x y <chr> <dbl> <dbl> 1 1번 데이터셋 10 8.04 2 1번 데이터셋 8 6.95 3 1번 데이터셋 13 7.58 4 1번 데이터셋 9 8.81 5 1번 데이터셋 11 8.33 6 1번 데이터셋 14 9.96 7 1번 데이터셋 6 7.24 8 1번 데이터셋 4 4.26 9 1번 데이터셋 12 10.8 10 1번 데이터셋 7 4.82 # … with 34 more rows ``` ] --- count: false ### 공룡 데이터 .panel1-anscombe-auto[ ```r library(tidyverse) anscombe_tbl %>% pivot_wider(names_from=`변수`, values_from = `값`) %>% unnest(cols = c(x, y)) %>% * ggplot(aes(x = x, y = y)) ``` ] .panel2-anscombe-auto[ <!-- --> ] --- count: false ### 공룡 데이터 .panel1-anscombe-auto[ ```r library(tidyverse) anscombe_tbl %>% pivot_wider(names_from=`변수`, values_from = `값`) %>% unnest(cols = c(x, y)) %>% ggplot(aes(x = x, y = y)) + * geom_point() ``` ] .panel2-anscombe-auto[ <!-- --> ] --- count: false ### 공룡 데이터 .panel1-anscombe-auto[ ```r library(tidyverse) anscombe_tbl %>% pivot_wider(names_from=`변수`, values_from = `값`) %>% unnest(cols = c(x, y)) %>% ggplot(aes(x = x, y = y)) + geom_point() + * facet_wrap(facets = vars(데이터셋)) ``` ] .panel2-anscombe-auto[ <!-- --> ] --- count: false ### 공룡 데이터 .panel1-anscombe-auto[ ```r library(tidyverse) anscombe_tbl %>% pivot_wider(names_from=`변수`, values_from = `값`) %>% unnest(cols = c(x, y)) %>% ggplot(aes(x = x, y = y)) + geom_point() + facet_wrap(facets = vars(데이터셋)) + # mean of x * ggxmean::geom_x_mean() ``` ] .panel2-anscombe-auto[ <!-- --> ] --- count: false ### 공룡 데이터 .panel1-anscombe-auto[ ```r library(tidyverse) anscombe_tbl %>% pivot_wider(names_from=`변수`, values_from = `값`) %>% unnest(cols = c(x, y)) %>% ggplot(aes(x = x, y = y)) + geom_point() + facet_wrap(facets = vars(데이터셋)) + # mean of x ggxmean::geom_x_mean() + * ggxmean::geom_y_mean() ``` ] .panel2-anscombe-auto[ <!-- --> ] --- count: false ### 공룡 데이터 .panel1-anscombe-auto[ ```r library(tidyverse) anscombe_tbl %>% pivot_wider(names_from=`변수`, values_from = `값`) %>% unnest(cols = c(x, y)) %>% ggplot(aes(x = x, y = y)) + geom_point() + facet_wrap(facets = vars(데이터셋)) + # mean of x ggxmean::geom_x_mean() + ggxmean::geom_y_mean() + # mean of y * ggxmean:::geom_x1sd(linetype = "dashed") ``` ] .panel2-anscombe-auto[ <!-- --> ] --- count: false ### 공룡 데이터 .panel1-anscombe-auto[ ```r library(tidyverse) anscombe_tbl %>% pivot_wider(names_from=`변수`, values_from = `값`) %>% unnest(cols = c(x, y)) %>% ggplot(aes(x = x, y = y)) + geom_point() + facet_wrap(facets = vars(데이터셋)) + # mean of x ggxmean::geom_x_mean() + ggxmean::geom_y_mean() + # mean of y ggxmean:::geom_x1sd(linetype = "dashed") + * ggxmean:::geom_y1sd(linetype = "dashed") ``` ] .panel2-anscombe-auto[ <!-- --> ] --- count: false ### 공룡 데이터 .panel1-anscombe-auto[ ```r library(tidyverse) anscombe_tbl %>% pivot_wider(names_from=`변수`, values_from = `값`) %>% unnest(cols = c(x, y)) %>% ggplot(aes(x = x, y = y)) + geom_point() + facet_wrap(facets = vars(데이터셋)) + # mean of x ggxmean::geom_x_mean() + ggxmean::geom_y_mean() + # mean of y ggxmean:::geom_x1sd(linetype = "dashed") + ggxmean:::geom_y1sd(linetype = "dashed") + # linear model * ggxmean::geom_lm() ``` ] .panel2-anscombe-auto[ <!-- --> ] --- count: false ### 공룡 데이터 .panel1-anscombe-auto[ ```r library(tidyverse) anscombe_tbl %>% pivot_wider(names_from=`변수`, values_from = `값`) %>% unnest(cols = c(x, y)) %>% ggplot(aes(x = x, y = y)) + geom_point() + facet_wrap(facets = vars(데이터셋)) + # mean of x ggxmean::geom_x_mean() + ggxmean::geom_y_mean() + # mean of y ggxmean:::geom_x1sd(linetype = "dashed") + ggxmean:::geom_y1sd(linetype = "dashed") + # linear model ggxmean::geom_lm() + * ggxmean::geom_lm_formula() ``` ] .panel2-anscombe-auto[ 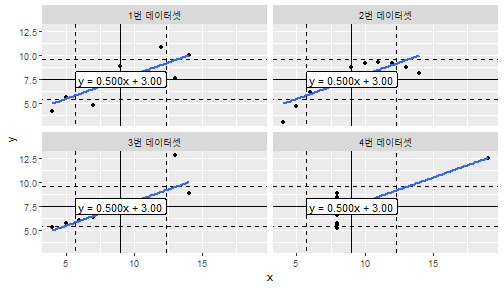<!-- --> ] --- count: false ### 공룡 데이터 .panel1-anscombe-auto[ ```r library(tidyverse) anscombe_tbl %>% pivot_wider(names_from=`변수`, values_from = `값`) %>% unnest(cols = c(x, y)) %>% ggplot(aes(x = x, y = y)) + geom_point() + facet_wrap(facets = vars(데이터셋)) + # mean of x ggxmean::geom_x_mean() + ggxmean::geom_y_mean() + # mean of y ggxmean:::geom_x1sd(linetype = "dashed") + ggxmean:::geom_y1sd(linetype = "dashed") + # linear model ggxmean::geom_lm() + ggxmean::geom_lm_formula() + # Pearson correlation * ggxmean:::geom_corrlabel() ``` ] .panel2-anscombe-auto[ 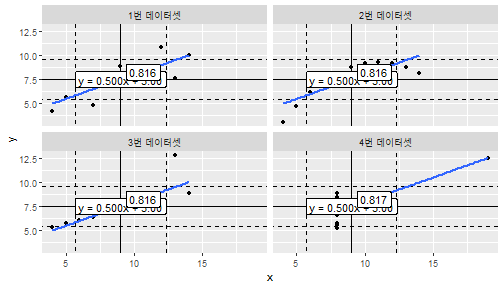<!-- --> ] <style> .panel1-anscombe-auto { color: black; width: 49%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel2-anscombe-auto { color: black; width: 49%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel3-anscombe-auto { color: black; width: NA%; hight: 33%; float: left; padding-left: 1%; font-size: 80% } </style> --- class: center, middle, inverse # 공룡 데이터 --- name: datasauRus count: false ### 공룡 데이터 .panel1-datasauRus-auto[ ```r *library(tidyverse) ``` ] .panel2-datasauRus-auto[ ] --- count: false ### 공룡 데이터 .panel1-datasauRus-auto[ ```r library(tidyverse) *datasauRus::datasaurus_dozen ``` ] .panel2-datasauRus-auto[ ``` # A tibble: 1,846 × 3 dataset x y <chr> <dbl> <dbl> 1 dino 55.4 97.2 2 dino 51.5 96.0 3 dino 46.2 94.5 4 dino 42.8 91.4 5 dino 40.8 88.3 6 dino 38.7 84.9 7 dino 35.6 79.9 8 dino 33.1 77.6 9 dino 29.0 74.5 10 dino 26.2 71.4 # … with 1,836 more rows ``` ] --- count: false ### 공룡 데이터 .panel1-datasauRus-auto[ ```r library(tidyverse) datasauRus::datasaurus_dozen %>% * ggplot(aes(x = x, y = y)) ``` ] .panel2-datasauRus-auto[ <!-- --> ] --- count: false ### 공룡 데이터 .panel1-datasauRus-auto[ ```r library(tidyverse) datasauRus::datasaurus_dozen %>% ggplot(aes(x = x, y = y)) + * geom_point() ``` ] .panel2-datasauRus-auto[ 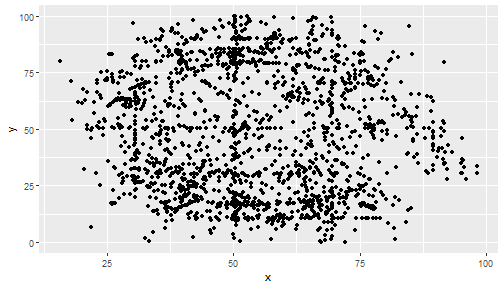<!-- --> ] --- count: false ### 공룡 데이터 .panel1-datasauRus-auto[ ```r library(tidyverse) datasauRus::datasaurus_dozen %>% ggplot(aes(x = x, y = y)) + geom_point() + * facet_wrap(facets = vars(dataset)) ``` ] .panel2-datasauRus-auto[ 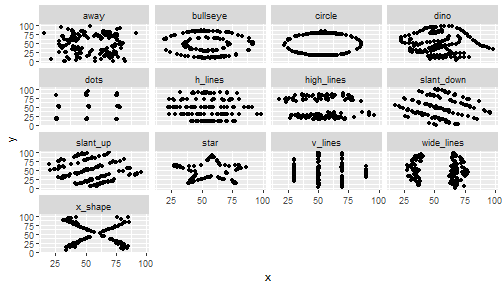<!-- --> ] --- count: false ### 공룡 데이터 .panel1-datasauRus-auto[ ```r library(tidyverse) datasauRus::datasaurus_dozen %>% ggplot(aes(x = x, y = y)) + geom_point() + facet_wrap(facets = vars(dataset)) + # mean of x * ggxmean::geom_x_mean() ``` ] .panel2-datasauRus-auto[ 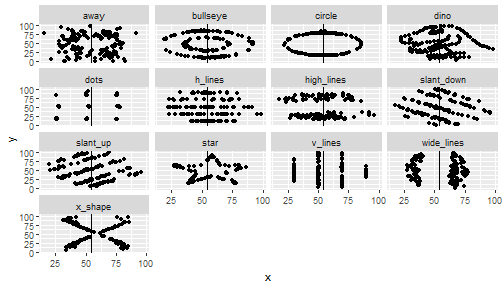<!-- --> ] --- count: false ### 공룡 데이터 .panel1-datasauRus-auto[ ```r library(tidyverse) datasauRus::datasaurus_dozen %>% ggplot(aes(x = x, y = y)) + geom_point() + facet_wrap(facets = vars(dataset)) + # mean of x ggxmean::geom_x_mean() + * ggxmean::geom_y_mean() ``` ] .panel2-datasauRus-auto[ 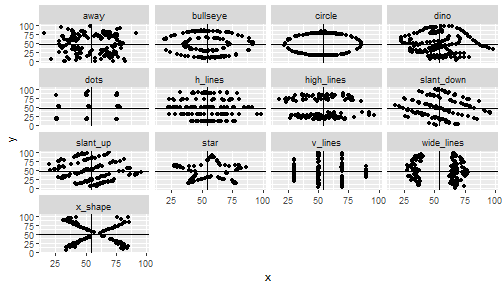<!-- --> ] --- count: false ### 공룡 데이터 .panel1-datasauRus-auto[ ```r library(tidyverse) datasauRus::datasaurus_dozen %>% ggplot(aes(x = x, y = y)) + geom_point() + facet_wrap(facets = vars(dataset)) + # mean of x ggxmean::geom_x_mean() + ggxmean::geom_y_mean() + # mean of y * ggxmean:::geom_x1sd(linetype = "dashed") ``` ] .panel2-datasauRus-auto[ 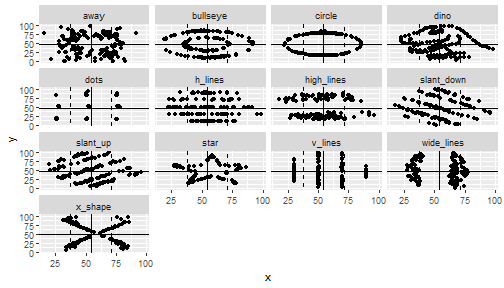<!-- --> ] --- count: false ### 공룡 데이터 .panel1-datasauRus-auto[ ```r library(tidyverse) datasauRus::datasaurus_dozen %>% ggplot(aes(x = x, y = y)) + geom_point() + facet_wrap(facets = vars(dataset)) + # mean of x ggxmean::geom_x_mean() + ggxmean::geom_y_mean() + # mean of y ggxmean:::geom_x1sd(linetype = "dashed") + * ggxmean:::geom_y1sd(linetype = "dashed") ``` ] .panel2-datasauRus-auto[ <!-- --> ] --- count: false ### 공룡 데이터 .panel1-datasauRus-auto[ ```r library(tidyverse) datasauRus::datasaurus_dozen %>% ggplot(aes(x = x, y = y)) + geom_point() + facet_wrap(facets = vars(dataset)) + # mean of x ggxmean::geom_x_mean() + ggxmean::geom_y_mean() + # mean of y ggxmean:::geom_x1sd(linetype = "dashed") + ggxmean:::geom_y1sd(linetype = "dashed") + # linear model * ggxmean::geom_lm() ``` ] .panel2-datasauRus-auto[ <!-- --> ] --- count: false ### 공룡 데이터 .panel1-datasauRus-auto[ ```r library(tidyverse) datasauRus::datasaurus_dozen %>% ggplot(aes(x = x, y = y)) + geom_point() + facet_wrap(facets = vars(dataset)) + # mean of x ggxmean::geom_x_mean() + ggxmean::geom_y_mean() + # mean of y ggxmean:::geom_x1sd(linetype = "dashed") + ggxmean:::geom_y1sd(linetype = "dashed") + # linear model ggxmean::geom_lm() + * ggxmean::geom_lm_formula() ``` ] .panel2-datasauRus-auto[ <!-- --> ] --- count: false ### 공룡 데이터 .panel1-datasauRus-auto[ ```r library(tidyverse) datasauRus::datasaurus_dozen %>% ggplot(aes(x = x, y = y)) + geom_point() + facet_wrap(facets = vars(dataset)) + # mean of x ggxmean::geom_x_mean() + ggxmean::geom_y_mean() + # mean of y ggxmean:::geom_x1sd(linetype = "dashed") + ggxmean:::geom_y1sd(linetype = "dashed") + # linear model ggxmean::geom_lm() + ggxmean::geom_lm_formula() + # Pearson correlation * ggxmean:::geom_corrlabel() ``` ] .panel2-datasauRus-auto[ <!-- --> ] <style> .panel1-datasauRus-auto { color: black; width: 49%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel2-datasauRus-auto { color: black; width: 49%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel3-datasauRus-auto { color: black; width: NA%; hight: 33%; float: left; padding-left: 1%; font-size: 80% } </style> --- name: datasauRus-stat ### 기술통계량 .panelset[ .panel[.panel-name[데이터셋] .pull-left[ ```r datasauRus::datasaurus_dozen ``` ] .pull-right[ ``` # A tibble: 1,846 × 3 dataset x y <chr> <dbl> <dbl> 1 dino 55.4 97.2 2 dino 51.5 96.0 3 dino 46.2 94.5 4 dino 42.8 91.4 5 dino 40.8 88.3 6 dino 38.7 84.9 7 dino 35.6 79.9 8 dino 33.1 77.6 9 dino 29.0 74.5 10 dino 26.2 71.4 # … with 1,836 more rows ``` ] ] .panel[.panel-name[평균] .pull-left[ ```r datasauRus::datasaurus_dozen %>% pivot_longer(cols = x:y) %>% group_by(dataset, name) %>% summarise(mean = mean(value)) %>% pivot_wider(names_from = name, values_from = mean) ``` ] .pull-right[ ``` # A tibble: 13 × 3 # Groups: dataset [13] dataset x y <chr> <dbl> <dbl> 1 away 54.3 47.8 2 bullseye 54.3 47.8 3 circle 54.3 47.8 4 dino 54.3 47.8 5 dots 54.3 47.8 6 h_lines 54.3 47.8 7 high_lines 54.3 47.8 8 slant_down 54.3 47.8 9 slant_up 54.3 47.8 10 star 54.3 47.8 11 v_lines 54.3 47.8 12 wide_lines 54.3 47.8 13 x_shape 54.3 47.8 ``` ] ] .panel[.panel-name[분산] .pull-left[ ```r datasauRus::datasaurus_dozen %>% pivot_longer(cols = x:y) %>% group_by(dataset, name) %>% summarise(var = var(value)) %>% pivot_wider(names_from = name, values_from = var) ``` ] .pull-right[ ``` # A tibble: 13 × 3 # Groups: dataset [13] dataset x y <chr> <dbl> <dbl> 1 away 281. 726. 2 bullseye 281. 726. 3 circle 281. 725. 4 dino 281. 726. 5 dots 281. 725. 6 h_lines 281. 726. 7 high_lines 281. 726. 8 slant_down 281. 726. 9 slant_up 281. 726. 10 star 281. 725. 11 v_lines 281. 726. 12 wide_lines 281. 726. 13 x_shape 281. 725. ``` ] ] .panel[.panel-name[상관계수] .pull-left[ ```r custom_correlation <- function(df) { cor(df$x, df$y) } datasauRus::datasaurus_dozen %>% group_by(dataset) %>% nest() %>% mutate(corr = map(data, custom_correlation)) %>% unnest(corr) ``` ] .pull-right[ ``` # A tibble: 13 × 3 # Groups: dataset [13] dataset data corr <chr> <list> <dbl> 1 dino <tibble [142 × 2]> -0.0645 2 away <tibble [142 × 2]> -0.0641 3 h_lines <tibble [142 × 2]> -0.0617 4 v_lines <tibble [142 × 2]> -0.0694 5 x_shape <tibble [142 × 2]> -0.0656 6 star <tibble [142 × 2]> -0.0630 7 high_lines <tibble [142 × 2]> -0.0685 8 dots <tibble [142 × 2]> -0.0603 9 circle <tibble [142 × 2]> -0.0683 10 bullseye <tibble [142 × 2]> -0.0686 11 slant_up <tibble [142 × 2]> -0.0686 12 slant_down <tibble [142 × 2]> -0.0690 13 wide_lines <tibble [142 × 2]> -0.0666 ``` ] ] ]